

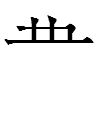
2ka 2tʂɨe
14.1.4.23:24:
BESTIAL MARSHAL (PART 1)
Last night, Ultraman Leo (1974-75), the first newly subtitled Japanese superhero show on Hawaii TV in over thirty years, debuted on KIKU-TV. That got me thinking about the Tangut word for 'lion',
2ka 2tʂɨe
which is unlike any other words for 'lion' in the region. I would
have expected loanwords such as
*1ʂʌ 1tsə < Tangut period northwestern Chinese 獅子 *ʂɨ tsɨ
(1ʂʌ 1tsə is attested as a transcription of Chinese 獅子 in the Timely Pearl, but is not a Tangut word.)
*sẽ ge < Written Tibetan sengge (< Sanskrit siṃha-?)
*aʳ lạ < *arslan < Turkic arslan
(*sl- > l- + tense vowel in Tangut; nasalization generally could not coexist with tension except in rhymes 65 and 76 whose original vowel was *e, not *a)
(Have any Turkic loanwords been identified in Tangut? Did the Uyghurs under Tangut rule contribute nothing to the written Tangut lexicon?)
2ka 2tʂɨe superficially resembles Written Burmese khraŋ
seˀ, but I would expect a Tangut cognate of the latter to be *1khɔ
2se < *khraŋ seˀ. Although I could reconstruct a
pre-Tangut *kaH Cɯ-tšeH (with a high-vowel presyllable to
condition the partial raising of *e to ɨe) as a
source of 2ka 2tʂɨe, I suspect that 2ka 2tʂɨe is simply
a borrowing from a word like *kace in the unknown substratum
language that may be the source of other mysterious disyllabic words in
Tangut (e.g.,
1ka 1o 'moon').
Tangut had no c and did not allow the sequence tʂe,
so tʂɨe was the best possible approximation of a foreign ce.
A study of these disyllabic words may enable us to outline the
phonological characteristics of their source.
2ka: 1nieʳ 2biuu 'li(on): beast commander'
Next: Dissecting the first tangraph for 2ka 2tʂɨe.
14.1.2.23:54: THE FAN-TASTIC FOUR AND AN EQUINE ENIGMA
Although the Tangut script has a 'horse' radical
< Chinese 馬 'horse'
that appears in the tangraphs for words for 'horse' - e..g,
0764 1rieʳ 'horse'

0803 2riaʳ 'horse'
1115 1gie 'horse'
(the above three were in my previous post)
1053 2lɨị 'horse'
- it is absent in the tangraphs for the disyllabic word
1055 4061 1tʂɨu 2riuʳ 'fine horse'
1055 in fact contains two near-mirror image elements (Boxenhorn codes tis and tir) that appear in no other characters.
Then again, according to the Tangraphic Sea, the bottom half of tis is taken from the 'horse' radical:
=
+
1055 (first half of 1tʂɨu 2riuʳ 'fine horse') =
'frame' (top left, center, and top right) of 1013 1tʂɨu 'the Chinese surname Chu' (phonetic) +
bottom of 1053 2lɨị 'horse' (semantic)
1055 thus may be an unusual semantophonetic compound whose halves are fused together.
The analysis of 4061 is unknown. I think it might have up to four source tangraphs:
=
+
+
+
/
?
4061 (second half of 1tʂɨu 2riuʳ 'fine horse') =
top of 4068 2me (second half of 1bə 2me 'to fete, present a gift') +
'move' (Nishida radical 049) = bottom left of 2miu 'to move' +
'finery, ornament' (Grinstead 1972: 28) = left of 2ʂwɨo 'dignified' +
right of 0764 1rieʳ 'horse' or 0803 2riaʳ 'horse'
Only two other tangraphs share a top component
Boxenhorn code fan < Tangut period northwestern Chinese 皿 *mie (1.3.0:39: which oddly wasn't used as a phonetic in tangraphs pronounced mie)
with 4061 and 4068:
4070 2me 'catkin'; 'to mate' (two unrelated homophonous words)
4074 2me 'cotton' < Middle Chinese 綿 *mien 'soft'?; is the homophony of 1bə 2me 'soft cotton' with 1bə 2me 'to fete, present a gift' (to soften someone up?) a coincidence?
I call the tangraphs with that component the 'fan-tastic four'.
Oops, I just realized I already wrote a four-part series on this word back in August 2011 (1 2 3 4). At least this time
- I gave the correct Tangraphic Sea analysis of 1055
- I proposed an analysis of 4061
- I proposed a Chinese origin of the Tangut component fan
so this post wasn't totally repetitive.
14.1.1.23:59: TRACING A TRIO OF HORSES
2014 is the year of the horse. The Tangut word for 'horse' in that context is
=
1115 1gie 'horse' =
left of 0764 1rieʳ 'horse' +
left of 0803 2riaʳ 'horse' (itself containing all of 1rieʳ 'horse')
It occurred to me last night that 1gie 'horse' might be from *CI-ŋgo. A prefix *CI- conditioned the fronting of *o:
*CI-ŋgo > *CI-ŋgø > *CI-ŋge > *CI-ŋgie > *ŋgie > 1gie
The root *ŋgo could have been borrowed from Late Middle Chinese 午 *ŋgo 'horse (calendrical)'.
I have already written about how 1rieʳ 'horse' may be from *mI-ro whose back vowel also fronted and lost its rounding under the influence of a front-vowel presyllable.It is tempting to relate 1rieʳ < *mI-ro 'horse' to both 2riaʳ 'horse' and the second syllable of
1055 4061 1tʂɨu 2riuʳ 'fine horse'
but their vowels cannot be reconciled; the latter two go back to pre-Tangut *Cɯ-raH (possibly related to Old Chinese 馬 *mraʔ 'horse'?) and *tšu ruH.
1.2.0:22: *mI-ro goes back to an even earlier *mI-raŋ whose *a does match the *a of *Cɯ-raH, but the presence and absence of *-ŋ needs to be explained if the two words share a common *r-root.
13.12.31.23:45: SVĀHĀ IN THE PILLAR OF THE VICTORIOUS SIGN
I have long been skeptical about reconstructing long vowels in Tangut. Both Gong and Arakawa reconstructed long vowels, albeit often in different rhymes and for different reasons. I have carried over Gong's long vowels into mine despite my reservations because they seem to correspond to vowel-consonant sequences elsewhere: e.g.,
Gong: 1njaa / my 1nɨaa 'black' : Written Tibetan nag-po 'id.'
Gong: 2njaa / my 2niaa (second syllable of Mynya 'Tangut') : Written Tibetan Mi-nyag 'Tangut'
However, if Tangut really had long vowels, I would expect tangraphs for long-vowel syllables to transcribe Sanskrit long-vowel syllables.
I first saw a reference to the last known Tangut inscription years ago but never actually examined any part of it until I saw Andrew West's photo last Saturday. Its title is at the top:
1swa dʐ-? 1xa dʐ-? = Sanskrit svāhā
The small dʐ-? (rhyme unknown) characters (Li Fanwen 2008 #5032) indicate that the vowel of the preceding character is long: 1swaa ?xaa. They are graphically and probably phonetically similar to
0443 1dʐɨo < *ɖɨaŋ < Middle Chinese *ɖɨaŋ 'long'
Their usage is modeled after that of 引 'pull' which indicates long vowels in Chinese transcriptions of Sanskrit.
If Tangut had long vowels, why would this notation be necessary? The Tangut were not shy about creating transcription tangraphs for foreign syllables.
But there are no tangraphs read as 1swaa or 1xaa in my reconstruction or Gong's.
Let's look at the actual tangraphs that were used:
=
+
4045 1swa 'hair' =
upper right of 2061 2pɛ̣̃ < *SpreN 'hair' +
cf. Daofu spə 'hair'; Written Tibetan spra 'hair (of head)' at STEDT is presumably a typo for skra 'id.'; Written Tibetan spu suggests that a presyllabic front vowel lowered and unrounded the main vowel: e.g.,
*SEpruN > *SEproN > *SEprøN > *SEPreN > *SEPreN
The *S- conditioned tension in the vowel (indicated with a subscript dot), the medial *-r- lowered *e to ɛ, and the final *-N conditioned nasalization of the vowel.
center of 5133 2rieʳ 'wool'
could have been combined with an 1-aa tangraph to form a special fanqie tangraph 1swaa for transcribing Sanskrit svā. Why not?
And why did Sanskrit svā have a second transcription
1swa 1vaʳ
with a small 3561 1vaʳ containing a retroflex vowel? Was this sequence meant to be read as [svaʳ] with retroflexion before a retroflex consonant? Li Fanwen (2008: 576) listed
1swa 1vaʳ 1xa
as a transcription of Sanskrit svāhā (with a full-size 3561 - and without any retroflexes!) in 佛說大孔雀明王經. (The large size of 3561 in Li Fanwen's entry does not reflect typographical limitations, as the small 5032 indicating vowel length is reproduced at half size in that dictionary.)
In Arakawa's reconstruction,
1swia (Gong: 1sjwa) 'time'
might be 1swaː (since his vowel length corresponds to my high vowels and Gong's -j-), but it was not used to transcribe Sanskrit svā.
Similarly,
=
+
4475 1xa 'to blow' =
top and bottom left of 4469 2ʂɨi 'to go toward, to depart' +
'mouth' = bottom left of 44711xɨu (1fu?) 'to blow', itself derived from 4475 plus the right of 2603 1ʂwɨew 'to attend, follow':
=
could have been combined with an 1-aa tangraph to form a special fanqie tangraph 1xaa for transcribing Sanskrit hā. And none of the four characters that I think Arakawa would reconstruct with long vowels as 1ha: or 2ha: are listed as tangraphs for Sanskrit hā in Arakawa (1997: 112):
1644 first half of 1xɨa 1ʂwɨe 'to condemn, swear'
2521 1xɨa 'fast, rapid'
3670 2xia (transcription tangraph for Sanskrit hya; see Arakawa 1997: 121)
5748 2xia (transcription tangraph for Sanskrit hya and Tangut northwestern Chinese 獻 *xɨã (*xiã?); see Arakawa 1997: 121 and Li Fanwen 2008: 906)
Oddly 3670 and 5748 are listed as 'isolated characters' (i.e., tangraphs lacking homophones) in Homophones even though they transcribe the same Sanskrit syllable. Neither appear in the second (i.e., rising) tone volume of the Precious Rhymes of the Tangraphic Sea. They are reconstructed with the second tone because they are fanqie characters whose right half is derived from the left side of
5314 2ja (transcription tangraph for Sanskrit ya; see Arakawa 1997: 110)
whose tone can be confirmed in the Precious Rhymes of the Tangraphic Sea.
Arakawa (2007: 110, 112) listed only a single tangraph as a transcription of Sanskrit hā - 4475 1xa which doubled as a transcription of Sanskrit ha with a short vowel. 4475 is the source of the right side of a fanqie character which is another transcription of Sanskrit ha with a short vowel (Arakawa 2007: 110):
=
+
0898 2a? = left of 0434 1ɨi (zero initial) + 4475 1xa (whose rhyme is not 2-a!)
Oddly 0898 does not have x- or the tone of its rhyme source tangraph.
After all this, I am back where I started. I remain skeptical about whether Tangut had syllables like svā or hā - or long vowels in general. I can give many more examples of mismatches between reconstructed vowel length in Tangut reconstructions and Sanskrit vowel length: e.g.,
3909 1pəu (a first syllable of Tangut clan names)
transcribed both Sanskrit pu and pū (Arakawa 2007: 110, 112), just as
4475 1xa
transcribed both Sanskrit ha and hā.
If vowel length were an integral feature of Tangut phonology, there would have been no need to use 5032 to indicate it; Sanskrit syllables with long vowels could have been rendered with tangraphs for native Tangut long-vowel syllables and fanqie tangraphs for Sanskrit-only long-vowel syllables. Surely such fanqie tangraphs would have been created for a high-frequency Sanskrit word such as svāhā. But they weren't. If the Tangut considered length to be a foreign characteristic requiring a special symbol (5032), how did they differentiate rhymes that modern scholars reconstructed with different vowel lengths?
A sample of rhymes differentiated by vowel length
| Rhyme | Sanskrit transcription (Arakawa 1997) | Arakawa | Gong | This site |
| 17 | -a, -ā | -a | -a | -a |
| 18 | only for la, pā | -ya | -ia | -æ |
| 19 | -a | -a: | -ja | -ɨa |
| 20 | -a, -ā | -ia | ||
| 21 | -a, -ā | -ya: | -jaa | -ɨaa |
| 22 | (never used?) | -a' | -aa | -aa |
| 23 | -ya' | -iaa | -ææ | |
| 24 | -a, -ā | -a:' | -jaa | -iaa |
All the a-rhymes except 19, 22, and 23 transcribed both Sanskrit short and long a.
Rhyme 18 was never used to transcribe Sanskrit -ya-syllables even though Arakawa and Gong respectively reconstructed -y- and -i- in that rhyme. Such syllables were mostly transcribed with rhyme 20 which Arakawa reconstructed without -y-.
The absence of rhymes 19 and 23 in transcriptions of Sanskrit ā-syllables may be a statistical artifact. Rhyme 19 mostly follows Grade III initials (with the exception of x- in 1644 and 2521 above). Such initials were rarely used in Sanskrit transcription apart from l- and ʂ-, and there were no examples of Sanskrit lā, śā [ɕaː], or ṣā [ʂaː] in Arakawa (1997). Those three syllables might have been transcribed with rhyme 19, and the last two could have been transcribed with rhyme 23 (which did not follow l-).
The complete absence of rhyme 22 from Sanskrit transcription is a big surprise to me. If rhyme 22 really was -aa, why wasn't it used to transcribe Sanskrit -ā? Why use rhymes 17, 18, and 20 as well as 21 and 24 instead?
One last puzzling point for now: Sanskrit short a is [ɐ] or [ə]; either is higher than long ā [aː]. If Tangut had a schwa, why weren't Sanskrit a-syllables transcribed with Tangut ə? I have long thought that the Tangut only heard Sanskrit through a Chinese filter, and now I suspect they also encountered Tibetanized Sanskrit. In Tibetan and Middle Chinese, Sanskrit a was localized as a since Tibetan had no schwa and Middle Chinese had no simple -ə syllables. (Middle Chinese did have -ɨə syllables without any counterparts in Sanskrit.)
13.12.29.23:49: PILLAR OF THE VICTORIOUS SIGN
I first saw a reference to the last known Tangut inscription years ago but never actually examined any part of it until I saw Andrew West's photo last Saturday. Its title is at the top:
1je 2bəəu 1dʐɨõ (from right to left)
lit. 'sign victorious flag'
I interpret this as a
[[noun adjective] noun]
structure: 2bəəu 'victorious' is an adjective modifying 1je 'sign', and that noun phrase in turn modifies the noun 1dʐɨõ 'flag' (which in this context is 'column' since the inscription is on a column).
Having roundness isn't my idea of what a sign is, but that's the Tangraphic Sea analysis of 1je:
=
+
5498 1je 'sign, look, appearance' =
left of 5258 1ɔ̣ 'round' +
top and bottom right of 0930 1diu 'to have'
No analysis of 0206 2bəəu 'victorious' is known, but it contains components identified by Nishida (1966: ) as 'language', 'sage', and 'flag', implying that victories were symbolized by flags with sages' words on them (in Tibetan before the Tangut had a script of their own?).
=
+
+
1329 1dʐɨõ 'flag' is an early borrowing from Middle Chinese 幢 *ɖɔŋ. (Later borrowings have voiceless aspirate initials reflecting devoicing and aspiration of Middle Chinese voiced initials in Tangut period northwestern Chinese. The affricate dʐ- may be from pre-Tangut *dr-. The vowel mismatch needs explanation.)
The Tangraphic Sea analysis of 1329 1dʐɨõ 'flag' implies that a 1dʐɨõ flag was larger than a 1lɨəə flag.
=
+
1329 1dʐɨõ 'flag' =
'flag' (not the same element as in 0206!) = left of 1696 1lɨəə 'flag; to raise in the wind' (< 1lɨə 'wind' plus a suffix?) +
right of 4457 2liẹ 'large'























{kind=link}