



11.8.27.23:59: TWO MANY WORDS (PART 1)
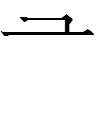
Andrew West recently uploaded a picture of a Jin Dynasty double fish mirror that inspired me to look up the Tangut equivalents of Chinese 雙 'double' in the Chinese-Tangut index of Li Fanwen 2008:
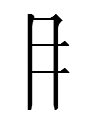
| Li Fanwen 2008 number | Tangraph | Reading |
| 0468 |
|
1phiõ |
| 0518 |
|
2baʳ |
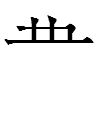
| 5747 |
|
2ʃɔɔ |
| 5855 |
|
2lọ |
The last one appears in the Tangut equivalent of Chinese 雙魚 'double fish':
3057 5855 2ʒɨu 2lọ
I'm out of time, so I only have a couple (!) of things to say.
First, 'twin girls' appears just one line before 'double fish' in the list of constellations in the Tangut-Chinese Pearl in the Palm glossary as
5855 5549 2lọ 2tʃhɨw
with the word order reversed. Apparently 'double fish' is a noun-adjective phrase whereas 'twin girls' is a numeral-noun phrase like other Tangut constellation names: Six Injuries, Three Penalties, Three Mounds, and Five Graves.
Second, I am tempted to derive 2lọ from Tangut period northwestern Chinese 兩 *lɨõ 'both' which was transcribed in Tibetan as lyong in the pre-Tangut period. Yet 2lọ lacks a medial -ɨ- and has a tense vowel implying an earlier preinitial *S- absent from Chinese. (The absence of nasality in the Tangut form is not a problem since both Tangut -o and -õ correspond to Chinese *-õ. The -o-borrowings may be from a Chinese dialect that lost nasal vowels.)
I would reconstruct the pre-Tangut ancestor of 2lọ as *SloH with an *S- to account for the tense vowel and an *-H to account for the later 'rising' tone signified by 2-.
Although the Chinese word did originally lack an *-ɨ-, that medial developed long after Old Chinese *r- had shifted to *l- and long before Chinese *-aŋ had shifted to *-õ, so the Tangut word cannot be an old loan from Chinese:
Old Chinese ́*raŋʔ > Middle Chinese *lɨaŋʔ > Tangut period NW Chinese *lɨõ
8.28.4:44: The analysis of 5549 is unknown.
The left side is
5815 1tsiə 'also, too; small' (cf. the shapes of Chn 亦 'also', 小 'small', 少 'few')
It is a phonetic for lo shared with
| Li Fanwen 2008 number | Tangraph | Reading | Gloss | Notes |
| 5885 |
|
1lõ | to exchange | 'person' (alphacode: dex) added to right of 5914 below |
| 5901 |
|
2lo | hole, concave | 'earth' (alphacode: ges) on right |
| 5914 |
|
2lọ | two, second | see below |
The right side is shared with 4027 1niəə 'two' (based on a mirror image of Chinese 貳 'two'?) whose halves (alphacode: ber and hul) combine with 5815 (alphacode: gux) to form two 2lọ tangraphs:
<
>
5914 2lọ < 4027 1niəə > 5855 2lọ
The semantic difference between 5914 and 5855 is not clear. Li Fanwen (2008: 933) only lists dictionary attestations for 5914 which do not include an entry for 5914 itself. Such an entry is presumably in the lost second volume of Tangraphic Sea. The Tangraphic Sea defined both 4027 and 0468 as 5914 and 5855 among various other near-synonyms.
5914 is phonetic in 5885:
=
The 'person' (dex) on the right was derived from 2888 2mə 'surname'. What does 'surname' have to do with 'exchange'?
The Combined Homophones-Tangraphic Sea analysis of 5901 does not contain 5914 as phonetic:
=
+
The left side of 5901 is derived from the right of 3799 2sew 'small' (< Chn 小), the mirror image of 5914.
The right side of 5901 is derived from the left of 2121 2giuʳ 'hollow; gully'.
Was 5901 'small hole'?
11.8.26.23:59: IN PURSUIT OF COVERED JADE
In "Covered Jade", I mentioned that Li Fanwen (2008: 313) glossed
1885 'hunchback' (reading unknown)
as 'waist' partly on the basis of the B edition of Homophones. Thanks to Andrew West for finding 1885 in Homophones B 38A65
O
with a circle indicating a division between homophone groups and a small clarifier tangraph
that appears to be a variant of
1141 2kiʳ 'waist'
containing 1885 in place of
3087 1dʒɨw 'waist'
beneath
(Boxenhorn alphacode bax; function unknown).
1885 is in the same homophone group as
implying that its reading was 1dʒɨw which is also the reading of2356 1dʒɨw 'to pursue'
Does 3087 have its own entry elsewhere in the B edition of Homophones? I suspect it doesn't.
3087 1dʒɨw 'waist'.
Did 1885 also represent a nonhomophonous word 'hunchback' listed elsewhere in the B edition of Homophones, or were 'waist' and 'hunchback' homophones?
8.27.1:36: In the most commonly cited edition of Homophones, 3087 has a clarifier 1141 corresponding to the 1141-like clarifier of 1185:
Homophones and Homophones B
3087 1dʒɨw 'waist' (37B51) and 1185 1dʒɨw 'waist' (B 37A65)
Although 3087 is the last member of its homophone group, there is no circle indicating a division between it and the following two nonhomophonous tangraphs
=
+

5339 1ʃɛ̃ 'to give birth' < borrowed from Chinese 生 *ʃɛ̉ =
all of 5435 1vəəi 'to give birth' (native word) +
left of 3281 2zwị 'to give birth' (native word) < ?*S-Pɯ-tsi, cognate to Old Chinese 子 *tsəʔ 'child', 孳 *N-tsəʔ-s 'to breed' (but the vowel correspondence is irregular)
<
2256 1ʃɛ̃, transcription of Chinese 生 *ʃɛ̉̃
doubled in 1ʃɛ̃ 1ʃɛ̉̃ 'beast, monkey', borrowed from Chinese 猩猩 *ʃɛ̉ ʃɛ̉written as a reversal of the elements of 558 nieʳ 'wild animal'
whose readings are not homophonous with 3087 1dʒɨw according to Tangraphic Sea and Precious Rhymes of the Tangraphic Sea.
The commonly cited edition of Homophones has 3087 as the clarifier of 1141 at 26A12:The Mixed Categories volume of Tangraphic Sea defines 3087 as 1141 at 3.2303.
No complete definition of 1141 is available, but I suspect it was defined as 3087.
1141 and 3087 are obviously graphically related. Could one or both have been derived from 要, the right side of Chinese 腰 'waist'? The bottom half of 1185 is even closer to the 女 at the bottom of 要 than the 乂 at the bottom of 1141 and 3087.
8.27.9:23: I don't know what the semantic differences are between
the two words for 'waist': 1141 2kiʳ ' and 3087 1dʒɨw
the two native words for 'to give birth': 5435 1vəəi and 3281 2zwị
Li Fanwen (2008: 191) lists no attestations of 1141 outside of dictionaries. Could 1141 be the ritual Tangut equivalent of the more widely attested 3087 even though it is monosyllabic rather than disyllabic like many other ritual Tangut words?
Both 5435 and 3281 are widely attested, so they do not constitute a ritual/common synonym pair.
11.8.25.23:59: RITUAL TANGUT AND RAACHAASAP
David Boxenhorn suggested that ritual Tangut (RT) could be like Thai ราชาศัพท์ raachaasap 'royal language'. (TRL) < Sanskrit raajaa 'king' + śabda 'sound'. David has also called RT 'Odic Tangut' because it appears only in odes (with the exception of dictionaries). RT is obviously not a royal language since it is not associated with Tangut royalty which is mentioned in common Tangut (CT) texts. However, it does share a few characteristics with TRL:
1. RT words have unrelated synonyms in CT, just as TRL words have unrelated synonyms in non-royal Thai.
2. RT words are often longer than their CT synonyms, just as TRL words are often longer than non-royal Thai words: e.g.,
'three': RT
2lheʳ 2giu vs. CT
1sọ
'to give': TRL พระราชทาน phraraatchathaan (< Skt vara 'best' + raaja 'king' + daana 'gift') vs. non-royal Thai ให้ haj
3. If length is disregarded, there is no obvious graphic distinction between RT and CT, just as there is no obvious graphic distinction between TRL and non-royal Thai words. There are no graphemes unique to RT and TRL.
4. RT and TRL both lack grammatical morphemes, so they are actually special registers rather than fully functional languages.TRL is a mixture of Sanskrit, Pali, and Khmer. Could RT be of non-Tangut origin? I have long suspected that RT is a remnant of a non-Sino-Tibetan substratum language. Kepping believed the RT odes were quite old because they lack references to Buddhism and to peoples other than the Tangut, the Tibetans, and the Chinese.
Nishida Tatsuo (1986: 74) proposed that RT was the language of the Tangut ruling class (a true royal language!) whereas CT was the language of the Tangut masses. However, this would not explain why CT is used everywhere but in the odes. Moreover, it is difficult to believe that the language of the ruling class would lack grammatical morphemes.
Tangut dictionaries do not distinguish between RT and CT at all. They define RT words in terms of CT and vice versa: e.g., in Tangraphic Sea,
'Tangut': the first half of RT
1lhwiẹ dʒɨə was defined as CT
2mi
'three': CT
RT definitions contain no terms like 'royal language' or 'odic language'. If we only knew Tangut through its dictionaries, we would notice monosyllabic-disyllabic synonym pairs, but we would not be able to guess that the longer words are far less frequent in other texts.
8.26.1:03: I Googled "'special registers' vocabulary" and found this passage by Grimes and Maryott (1994: 309) (emphasis mine):
The special registers discussed in this paper are clearly a likely mechanism for lexical innovation [cf. Kepping's hypothesis that "RL was invented by the pre-Buddhist, obviously shamanistic, Tangut priests for their own usage"]. There are some anomalies, however. Some of the replacement forms in the special registers appear to be retentions from the proto-language, while the form in the common register is the innovation. It is not clear, however, whether some forms are retentions or reintroductions of items apparently cognate with proto-forms [i.e., borrowing such items from another language that retained them?]. Since the norm in these special registers is for inherent vocabulary to be replaced, one must make the conservative assumption that the terms in the above examples have been reintroduced rather than retained from the proto-language.
Could RT 'replacements' for CT words actually be retentions from a substratal language?
If all known RT words were collected, one might be able to discover characteristics of the phonological structure of the substratal language.
8.26.7:49: Given that RT words are longer than CT words, it would not be surprising if RT only used a subset of the phonemic inventory of CT. Both RT and CT have two tones (excluding the mysterious 'entering tone' category) but it's not clear where all CT initials and finals also exist in RT.
Since TRL is derived from nontonal languages, it lacks reflexes of Proto-Tai tones B and C. (TRL syllables ending in sonorants have reflexes of PT tone A and TRLsyllables ending in obstruents have reflexes of PT tone D.)
11.8.24.23:59: COVERED JADE
Tangraphs for two out of the three Tangut words for 'camel'
0660 3996 2la 2diə 'camel' (native common Tangut)
0704 1260 2miəə 1tʃɨu 'camel' (ritual Tangut)
but not
3973 1tha 'camel' (borrowed common Tangut)
contain the component (Boxenhorn alphacode:gol) identified by Nishida (1966: 244) as 玉 'jade':
Adding a stroke ノ to cover 'jade' results in
which has no entry in any native Tangut dictionary: Tangraphic Sea, Precious Rhymes of the Tangraphic Sea, or Homophones. Li Fanwen (2008: 313) gives only a single attestation: Nevsky (1960 II: 429) which is not a primary source. Nevsky himself did not include a sample of usage. He only listed three definitions:
1885 'hunchback' (reading unknown)
傴僂 (Tib. sgur-po) crooked back
Written Tibetan sgur-po is 'hunchback'. Li translated 'crooked back' as 駝背 'hunchback' (lit. 'camel back').
Li also glossed 1885 as 'waist' as if it were a variant of
3087 1dʒɨw 'waist'
(See Andrew West's "Untangling the Web of Characters" on 3087 as a component in tangraphs.)
on the basis of Tangraphic Sea 7.242 and 38A65 in two Homophones texts, but I don't see it in the former, and I don't have access to either of the latter.
I don't know what to make of any of this. Questions:
Why isn't 'hunchback' in the spellings for all three words for 'camel'?
Why is the similar element 'jade' in only two of those spellings?
Could the unknown pronunciation of 'hunchback' be similar to any of the syllables in the words for 'camel'?
Is 'hunchback' homophonous with its graphic near-lookalike 'waist'?
11.8.23.23:53: RE-CALL THE REALM
In part 2 of "Kenning Camels", I mentioned that the first syllable of
0704 1260 2miəə 1tʃɨu 'camel'
is homophonous with
0163 2miəə 'to call' (common Tangut = CT?), 'boundary' (CT)
Ritual 'Call' or Common 'Call'?
I thought that 'to call' might be ritual Tangut because Li Fanwen 2008 only lists examples of this usage from dictionaries. However,
1. Ritual Tangut words are disyllabic, but 0163 stands by itself in a Tangraphic Sea definition for
5685 1po 'to report' (a borrowing from Chinese 報)
'hand' (Boxenhorn alphacode: pik) on the left reminds me of 扌 'hand' on the left of 报, a simplification of 報
2. 0163 shares a root with the CT word
0166 1mị 'to inform'
which is the second half of the compound
0163 0166 2miəə 1mị 'to inform'
Li Fanwen 2008 does not list any attestations of this compound outside dictionaries. It could be an RT disyllabic equivalent of 0163 or 0166.
0166 is analyzed as being from 0163 and 0165 xa 'to shout' (tone unknown):
=
+
0165 has a circular analysis with 1586 1ɣɪ̣ 'sound' as the source of the left-hand element 'sound' (Boxenhorn alphacode: bos):
=
+
The function of the right-hand element of 0165 and 0166 (Boxenhorn alphacode: dao) is unknown.
The analysis of 0163 is unknown. 0166 looks like 0163 with 'person' (Boxenhorn alphacode: dex) added in the middle.
3. I am unaware of any other tangraphs that have different meanings in ritual and common Tangut.
4. Li Fanwen 2008 is not an exhaustive listing of attestations.There is no way to tell from a dictionary listing whether any tangraph is ritual, common, or both. The two types of tangraphs also share components: e.g., the first tangraphs of the RT and CT words for 'camel'
0704 2miəə (RT) and 0660 2la (CT)
share a vertical line (Boxenhorn alphacode: bae) followed by the component (Boxenhorn alphacode:gol) identified by Nishida (1966: 244) as 玉 'jade' (!):
Apparently Tangut readers were just expected to know whether a tangraph was RT or CT.
Blunder at the Boundary
Li Fanwen listed the second meaning of 2miəə as 境, which I translated as 'border', and only lists examples from Buddhist texts. Soothill and Hodous' A Dictionary of Chinese Buddhist Terms defined 境 as
[Skt] viṣaya; artha; gocara. A region, territory, environment, surroundings, area, field, sphere, e.g. the sphere of mind, the sphere of form for the eye, of sound for the ear, etc.; any objective mental projection regarded as reality.
境 does not mean 'border' in a Buddhist context. So I conclude that 2miəə may not have the full semantic range of 境 'border; region (< 'bordered area'?)'. Grinstead (1972: 119) defined it as 'region'.
I fell into the trap of assuming that Tangut and Chinese words are truly equivalent. It is convenient for Tangut to be translated character for character into Chinese, but one should not conflate convenience with accuracy.
11.8.22.23:55: DIVIDING A FINE STEED (PART 4)
David Boxenhorn made me reconsider this Tangraphic Sea analysis last seen in part 2:
=
+
1055 1tʃɨu (first half of 1tʃɨu 2riuʳ 'fine steed') =
'frame' of 1013 1tʃɨu 'the surname Chu; transcription for Chinese *tʃɨu' +
bottom of 1054 1thiu (reduplicated in 1thiu 1thiu 'truth'; does it ever occur alone?)
(14.1.3.0:48: 1054 is an error for 1053!)
I initially rejected it because the bottoms of 1055 and 1054 looked different in the old Mojikyo font I was accidentally using. But in Li Fanwen 2008 and a newer Mojikyo font, both 1055 and 1054 have the same bottom right element: ㄇ with two horizontal strokes intersecting its left vertical stroke. However, 1055 and 1054 still have different bottom left elements:
(The second image is only an approximation. The horizontal strokes should touch the left vertical stroke.)
Moreover, this analysis could imply that the left and right halves of 1054
(Boxenhorn alphacodes: pul and hix; Nishida glossed pul as 'indicate')
consist of top and bottom halves. Are there any other analyses of tangraphs with pul and hix that split them vertically? I can't find any in the analyses in the surviving volumes of Tangraphic Sea. (I have not looked in Precious Rhymes of the Tangraphic Sea, but even PRTS does not have all the analyses that would have been in the missing second volume of Tangraphic Sea.)
1054 1thiu looks like 1053 2lị 'horse' (nonbasic but still common Tangut) with an extra stroke:
1054 vs. 1053
1053 has 'horse' (Boxenhorn alphacode: hin) on the left instead of pul 'indicate'.
Is 1053 the real source of the bottom of 1055? (14.1.3.0:50: Yes.)
?
Was 1054 an error for 1053 in the analysis of 1055? (14.1.3.0:50: It was my error.)
8.23.0:36: Li Fanwen's 2008 dictionary has
1051 2dəəu 'to crawl'
instead of the completely different
1053 2lị 'horse'
at the beginning of its entry for 1053, though 1053 appears in the body of the entry.
11.8.21.23:59: DIVIDING A FINE STEED (PART 3)
The second half of
1055 4061 1tʃɨu 2riuʳ 'fine steed'
has a rare top component (radical 99 in Andrew West's index for Li Fanwen 1997)
There are only three other tangraphs with that component (Boxenhorn alphacode: fan):
4068 2me (second half of 1bə 2me 'to fete, present a gift')
4070 2me 'catkin'; 'to mate' (two unrelated homophonous words)
4074 2me (second half of 1bə 2me 'soft cotton' - homophony with 'to present a gift' coincidental?; in one instance 2me means 'cotton' by itself - a loan from Chinese 綿 *mien 'soft'?)
4068 and 4074 are derived from each other in Precious Rhymes of the Tangraphic Sea. The derivations of 4061 and 4070 are unknown. The bottom of 4070 may be from the bottom of
2878 1bɪ̣ 'willow' (with 'person' [!] on the left and 'wood' on the top right)
since 4070 occurs in the phrase
4315 4070 1bɪ̣ 2me 'willow catkin'
The four fan-tangraphs lack a semantic common denominator. Their shared graphic component fan must be phonetic in the three homophonous tangraphs (4068, 4070, 4074) but cannot be phonetic in 4061. So what's it doing on the 'back' of
1055 4061 1tʃɨu 2riuʳ 'fine steed'
if one thinks of it as a horse facing leftward?
Subtracting fan from 4061 leaves three components (Boxenhorn alphacodes: cuo, bum, and cin). Nishida (1966: 242) identified
cuo
as 'movement' which suits a steed. Maybe
bum
defined by Grinstead (1972: 28) as 'finery, ornament' is also appropriate for a steed. But the common right-hand element
cin
is as mysterious in 4061 as it is in 547 other tangraphs.
Perhaps fan on the top of 4061 signifies a horse given as a gift or a horse worthy of mating.
8.22.1:02: 2me also sounds like Early Middle Chinese *mæʔ 'horse', borrowed into Japanese as me. However, the Tangut period northwestern Chinese word for 'horse' was *mba, so the Tangut would not have associated the phonetic element fan for 2me with horses.
































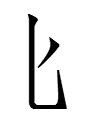
{kind=link}