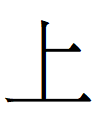 <ha>.
<ha>.21.11.16.20:26:
WHITE OX 10.12
𘬈𘭌𘲐𘰯𘭧𘰯𘲝𘲺
? uni ai par sair par ? nyair
'white ox year, ten month ten two day'
Continuing yesterday's Turkic theme:
1. Last night I learned the 7th century Chinese transcription of Ötüken:
於都斤 *ʔɨə to kɨn.
於 *ʔɨə: *ə would be the closest match for ö until Chinese developed front rounded vowels. But there was no syllable *ʔə, so *ʔɨə was the closest matching syllable.
都 *to: 7th century Chinese had no syllables like *tü, *tu, or *tö.
斤 *kɨn: This is a surprise since I'd expect *ken.
Could Old Turkic e have been [ə]? I doubt it because Turkic has
a palatal harmony system. Could the Chinese transcription reflect an
unstressed e? I doubt that too because in Old Turkic, medial
syllable syncopation implies "that the first and the last syllable of a
word had some prominence over the others, or that medial vowels were
not stressed" (Erdal 2004: 97). Also, "word-final
accent is the usual pattern in Turkish", and Turkish has a pitch
rather than a stress accent. (However, there is no guarantee Old Turkic
was suprasegmentally like Turkish.)
2. Today I learned about Ertuğrul ارطغرل <ʔrtˁɣrl> (d. c. 1280 AD), whose name is from er 'brave man' + tuğrul 'a kind of bird of prey'.
The name of the current president of Turkey has a similar etymology: Erdoğan ارطوغان <ʔrtˁwɣān> from er 'brave man' + doğan 'hawk'.
Two puzzles:
First, I would expect ط <tˁ> to only be in Arabic words, since Turkic has no /tˁ/. But my impression is that in Ottoman Turkish orthography, ط <tˁ> was used to write /t/ before back vowels, whereas ت <t> was used to write /t/ before front vowels. Did /t/ have an allophone [tˁ] before back vowels?
Second, ط <tˁ> also did double duty for /d/ before back
vowels. Why not use ض <dˁ> for /d/ before back vowels: e.g., as
in قاضی <qādˁy> qādı 'judge'? Because ض <dˁ> was
generally pronounced [z] in Ottoman Turkish, implying that Ottoman
Turkish got its alphabet via Persian (which also has [z] for ض
<dˁ>)? Was Persian [z] an approximation of [ɮˤ], the earlier
value of ض <dˁ> in Arabic?
21.11.15.21:25: WHITE OX 10.11
𘬈𘭌𘲐𘰯𘭧𘰯𘬣𘲺
? uni ai par sair par ? nyair
'white ox year, ten month ten one day'
I take the inclusion of Old Turkic in Unicode for granted now, so I needed Michael Everson's document to remind me that it's a relatively recent addition (v. 5.2, 2009).
Two lines caught my attention:
There are no more than 6 or 7 of them [Orkhon inscriptions].
But aren't there just two Orkhon
inscriptions? The
Japanese Wikipedia includes the two Tonyukuk
inscriptions among the Orkhon insciptions even though they are 360
km away from the Orkhon inscriptions.
Old Turkic is used to write Iranian text in a few manuscripts.
I would be interested to see how the Old Turkic script was adapted for a language without vowel harmony.
The English Wikipedia doesn't mention Iranic in Old Turkic script, but it does list variants I've never heard of.
I wonder what "Turkic inscriptions in the Greek alphabet" look like.
21.11.12.23:45: WHITE OX 10.8
𘬈𘭌𘲐𘰯𘭧𘬌𘲺
? uni ai par sair nyêm nyair
'white ox year, ten month eight day'
Tonight I found the New Pohnpeian-English Online Dictionary edited by Prof. Kenneth L. Rehg, who introduced me to the Micronesian world back in the 90s, his longtime colleague Damian Sohl, and Robert Andreas.
Stephen Trussel worked on the software, so it's not surprising that the dictionary resembles the Austronesian Comparative Dictionary that he coauthored with Prof. Robert Blust, who introduced me to the Austronesian world twenty-five years ago.
The first entry in the English finderlist is sorapang 'abacus' from Japanese 算盤 soroban 'id.' I wonder why the word isn't *soropang. (Pohnpeian has no b, and -ng is closer to Japanese -n [ɴ] than -n.) Clicking on sorapang took me to the s-entries. Sohseng 'Korea' from Japanese 朝鮮 Chōsen 'id.' caught my eye.
Pohnpeian has no affricates, so Ch- is approximated as s-. (That pattern of borrowing is parallel to how Old Japanese borrowed all Chinese voiceless affricates as s-. The word now pronounced Chōsen was Teusen in Old Japanese. Japanese ch- is from the affrication of t-.)
Pohnpeian <oh> is [oː]. I should have guessed that the use of <h> to indicate vowel length was a convention adopted from German.
I don't know whether the <e> of <Sohseng> is [e] or [ɛ]. Why is <e> ambiguous in Pohnpeian orthography if /e/ and /ɛ/ are distinct phonemes according to Wikipedia? Are there too few minimal pairs to justify a digraph *<ea> for [ɛ] parallel to the digraph <oa> for [ɔ]?
Ah, seems I misunderstood. eh₁ is defined as
name of the letter e, the second letter of the Pohnpeian alphabet, used to represent the phoneme /ɛ/, a lower-mid front vowel which occurs in both the Northern and Kitti dialects, as well as the phoneme /e/, a mid front vowel, found only in the Northern dialect.
So there is only one nonhigh front vowel phoneme whose realization varies by dialect. Hence Sohseng would be [soːsɛŋ] or [soːseŋ] depending on dialect.
I wish the online dictionary had its own pronunciation key so I didn't have to rely on Wikipedia.
Who is the online dictionary primarily for? Learners or native speakers? How common is online access on Pohnpei?
Now that so many have smartphones, do print dictionaries make sense any more for small languages when one can access online dictionaries for free with the latest words like sehlpwohn 'cell phone' and interned 'internet'? (<d> is [t].)
21.11.11.23:57: WHITE OX 10.7
𘬈𘭌𘲐𘰯𘭧𘬌𘲺
? uni ai par sair ? nyair
'white ox year, ten month seven day'
1. Is Korean 까치 kkachhi 'magpie' related to Japanese kasasagi 'id.'? Let me try to force a relationship.
As far as I know, kasasagi is not phonetically attested in Old Japanese. According to Martin (1987: 441), the word appears in the 鎮國守國神社 Chinkoku-shukoku jinja manuscript of 名義抄 Myōgishō as kasasaki. Let's assume that -g- (originally /Nk/) in kasasagi is an innovation, perhaps by analogy with sagi 'heron'.
Now let's suppose that kasasaki is borrowed from an earlier Koreanic compound like *kàsá-tsàkí. Each half of the compound has the canonical pitch pattern *low-high typical of Koreanic disyllabic nouns (Ramsey 1991: 219). I am not going to speculate what each half meant.
At some point between borrowing into Japanese and Late Middle Korean, the Koreanic form underwent reduction:
*kàsá- > *kàzá- > *kàá > kǎː
*-s- lenited to *-z- and then disappeared
after the medial consonant, the low-pitched first vowel and the high-pitched second vowel became adjacent and fused into a single long vowel with a rising pitch
*tsàkí > *tsʌ̀kí > *tskí > tshí
the first vowel was reduced to ʌ and then nothing
*-k- was reduced to aspiration of the preceding *ts-
Putting kǎː and tshí together results in Late Middle Korean 가치 kǎːtshí, the earliest attested form of the word. The word should have become modern Korean *kachhi with the same hangul spelling, but instead became kkachhi. Wiktionary explains:
The spontaneous gemination of the initial consonant occurred in the late nineteenth century. Spontaneous gemination is a recurrent phenomenon in Modern Korean, motivated by sound-symbolic effects.
See Wiktionary
for non-Koreanic etymologies of kasasagi 'magpie'.
2. In modern standard Mandarin, 鵲 què 'magpie' and 雀 què 'sparrow' are homophones with aspirated initials. But in the Middle Chinese lexicographical tradition, 鵲 'magpie' had initial aspirated *tsʰ- whereas 雀 'sparrow' had initial unaspirated *ts-. Modern Chinese forms have both aspirated and unaspirated initials. How can the variation be explained? I have derived Tangut aspiration in part from a preinitial *K-. Could the aspirated forms of 雀 'sparrow' reflect a preinitial *k-? My Old Chinese reconstruction requires a minor syllable *CI- with a high vowel to account for the high vowel in Middle Chinese:
*CItsekʷ > *CItsiekʷ > *tsɨakʷ > *tsɨakʷ
Could aspirated readings be from *kts- < *kIts-?
3. Today I learned from Wiktionary that the Chinese name of the Crested Myna (八哥
<EIGHT OLDER.BROTHER>: Mandarin bāgē) is a phonetic
transcription of Arabic ببغاء <bbghā`> babghā` ~ babaghā` ~
babbaghā` 'parrot'. Perhaps the Arabic original was disyllabic babghā`.
4. Forty-five years and a week ago today, Gaiking fought the 白鯨 Hakugei 'White Whale'. Was that Sino-Japanese term made up to translate Moby Dick (白鯨記 'Record of the White Whale' in Chinese)? Scripta Sinica has only one instance of it in its database of premodern Chinese texts in a 1499 entry in 朝鮮王朝實錄 Veritable Records of the Yi Dynasty.
11.12.1:45: I struggled to make up a Latin compound for 'white whale' but failed, so I settled for Greek leukophallaena. I don't know of any words with *albo-, which is what I'd expect for a combining form of Latin albus 'white'.
Wiktionary derives Latin ballaena 'whale' from Greek φάλλαινα. Why was Greek [pʰ] borrowed as Latin b-? Greek [pʰ] is from Proto-Indo-European *bh-. Could the Latin form reflect a variety of Greek that had not devoiced *bh-? That seems unlikely, as I know of no other evidence for such a variety.
Latin ballaena cannot be inherited from Proto-Indo-European, as b- would go back to the rare consonant *b-; the true Latin reflex of *bh- is f-: e.g., frater 'brother' corresponding to Greek φράτηρ 'member of a community' and Sanskrit bhrātr̥ 'brother', all from Proto-Indo-European *bhréʕtēr 'brother'.
21.11.10.23:55: WHITE OX 10.6
𘬈𘭌𘲐𘰯𘭧𘭬𘲺
? uni ai par sair ? nyair
'white ox year, ten month six day'
1. In today's installment of finally learning the incredibly obvious, I never realized that the -bek- in Uzbekistan was the Turkic title beg. What precedes it is uncertain.
2. I always thought beg was a loanword from Middle Chinese 伯
*pæk. Chinese unaspirated p- could be perceived as b,
and p- was not originally possible as an onset in Turkic (Erdal
2004: 100). Although Chinese loans in Turkic could begin with p-,
such loans could postdate beg which may date from an earlier
period before initial p- was possible. The final -g is
harder to explain, as Turkic phonotactics allowed -k. Had *-k
already lenited to *-ɣ in the Chinese source variety? Turkic
phonotactics did not allow *peɣ mixing front *e with
back *-ɣ, so *beg preserved the vowel at the expense of
the coda.
But Wikipedia
mentions an alternative etymology from an Iranic reflex of *baga-.
The problem with the Iranic etymology is the vowel: why isn't the
Turkic form *bagh with back vocalism and back gh
instead of front g? Was a front vowel needed to preserve -g?
3. Why will Kyrgyzstan soon "be
the only independent Turkic-speaking country in a few years that
exclusively uses the Cyrillic script"? In other words, what makes
it different from the other ex-Soviet Turkic countries?
21.11.9.1:15: WHITE OX 10.5
𘬈𘭌𘲐𘰯𘭧𘬦𘲺
? uni ai par sair tau nyair
'white ox year, ten month five day'
Yesterday I found this page confirming my memory of brainwashing as a calque of 洗腦 xǐnǎo 'wash brain'). The page has a couple of other etymologies of interest:
yen 'craving' < Cantonese 癮 [jɐn] 'addiction' (CantoDict entry)
I always assumed that had something to do with Japanese yen (also of Chinese origin but a different morpheme 圓 'circle').
Did Cantonese /ɐ/ ever have a fronted allophone before /j/? I can't
think of any other Anglicization of Cantonese /ɐ/ with fronting.
chop chop 'right away' < Cantonese 速速 [tsʰok tsʰok] 'hurry, urgent'
The expression makes me think of "a quickly moving knife" as the
page puts it. Could it be English with Chinese-style reduplication?
速速 isn't in either CantoDict or Bauer's huge Cantonese-English dictionary. Is it obsolete?
I suppose English -p reflects an overextension of the labiality of [o] to the final stop or a folk etymology involving chopping. It would be interesting if the expression were first attested as something like choke choke with [k].
21.11.8.23:56:
WHITE OX 10.4
𘬈𘭌𘲐𘰯𘭧𘲂𘲺
? uni ai par sair ? nyair
'white ox year, ten month four day'
1. Forty-five years ago today, the Battlehawk team fought a monster named 大魔公望 Daima Kōbō. 大魔 Daima is 'great devil'. What is 公望 Kōbō? Is it from 黄公望 Kō Kōbō, the Japanese name for Huang Gongwang?
Naver's
Japanese dictionary gives the odd hybrid native/Sino-Japanese
reading Kō Kinmochi for 黄公望, citing Wikipedia - which as of
today doesn't mention that reading.
2. The Chinese dictionary I use (重編國語辭典修訂本) has a new front page
but no entry for 公望. Only now did I learn that its author is 李鍌 Li
Xian. I had to look up 鍌 Xiǎn,
defined as 人名用字 'a character for personal names'. I guess <GOLD>
on the bottom is supposed to symbolize a positive quality beneath
the phonetic 洗 Xiǎn (a surname or plant name usually read xǐ
'wash': brainwashing is a calque of 洗腦 xǐnǎo 'wash
brain').
21.11.7.23:42: WHITE OX 10.3
𘬈𘭌𘲐𘰯𘭧𘯙𘲺
? uni ai par sair ? nyair
'white ox year, ten month three day'
1. Today is the sixty-fifth anniversary of the Japanese movie 空飛ぶ円盤恐怖の襲撃 Flying Saucers: Attack of Terror. The label on this film container has some interesting variants and simplifications:
variants of 年, 画, 沢, 円
𬮦 with PRC-style simplification of 門 as 门
监: PRC-style simplification of 監
擊: simplified as 𨊥 but without the horizontal stroke over 凵
2. Two days ago I was surprised to see Nanzhao referenced in a GI Joe
wiki entry on the Oktober Guard.
3. Yesterday I learned about the new TV series 境界戦機 Amaim
Warrior at the Borderline. I would never have guessed that Amaim
is read as アメイン Amein in Japanese.
4. Yesterday I discovered that 聖闘士星矢 Saint Seiya is built into the Windows 10 Japanese IME. Somebody at Microsoft is a manga/anime fan. Probably quite a few somebodies.
21.5.31.23:59:
WHITE OX 4.20
𘬈𘭌𘲐𘲂𘭧𘬂𘲺
? uni ai ? sair juri nyair
'white ox year, four month twenty day'
1. Thanks to 戴忠沛 Tai Chung-pui for letting me know that my SEALS 2021 keynote talk "The
Prehistory of Pyu" is up on YouTube along with many
other talks.
2. Last night I was hesitant to commit to a Late Old Chinese reading of 吐谷渾 'Tuyuhun'.
Since the 90s I've belonged to the six-vowel school of (Early/Middle) Old Chinese:
| *i |
*ə |
*e |
| *e |
*a |
*o |
But over the years I've changed my mind about how to bridge the gap between that system and the more complex vowel system of Middle Chinese. (There were, of course, no homogeneous 'Old Chinese' or 'Middle Chinese' languages; the ideas here are intended as approximations of features common to bodies of dialects in different periods.)
In late 2000, Axel Schuessler convinced me that the Late Old Chinese
vowel system was the product of 'warping' or 'bending'.
In what Pulleyblank called type A syllables, what I call 'higher
series' vowels bent into mid + high vowel diphthongs:
| Early Old Chinese |
*i |
*ə |
*u |
| Late Old Chinese type A syllables |
*ei |
*əɨ |
*ou |
| Late Old Chinese type B syllables: no change |
*i |
*ə |
*u |
In what Pulleyblank called type B syllables, what I call 'lower
series' vowels bent into high + nonhigh vowel diphthongs:
| Early Old Chinese |
*e |
*a |
*o |
| Late Old Chinese type A syllables: no change | *e |
*a |
*o |
| Late Old Chinese type B syllables |
*ie |
*ɨa | *uo |
But things get complicated after that.
The Early Old Chinese rhyme *-un in Middle Chinese became something like *-on, judging from Sino-Korean and Sino-Vietnamese [on]. (And probably Sino-Japanese [oɴ] < *-on as well, but the case for that is more complicated.)
Exactly how did that happen? The details may have varied from dialect to dialect. Here's a scenario that occurred to me yesterday:
Early Old Chinese *-on became Middle Chinese *-wan.
Phonetically, *-on might have been *[ɔˁn] if lower series vowels were like those of modern Khalkha. *[ɔˁn] broke to *[ɔˁɒˁn] and then shifted to *[wɑˁn], eventually losing its pharyngealization at some point: *[wɑn].
Perhaps *-un in type A syllables underwent a similar series of changes: *[ʊˁn] > *[ʊˁɔˁn] > *[wʌˁn] > *[wʌn] (corresponding to Schuessler's *-uən which I used yesterday).
Later, *[wʌn] became *[on], and later still, *[wɑn] similarly became *[ɔn] in Liao Chinese.
I considered the possibility that *-un in type A syllables became *-oun (phonetically *[ɔˁʊˁn]?).
Maybe I can combine my two proposed shifts of type A *-un (> *[ɔˁʊˁn] and > *[ʊˁɔˁn]) using metathesis:
If type A *-on underwent the same sorts of changes:*[ʊˁn] > *[ɔˁʊˁn] > *[ʊˁɔˁn] > *[wʌˁn] > *[wʌn]
*[ɔˁn] > *[ɒˁɔˁn] > *[ɔˁɒˁn] > *[wɑˁn] > *[wɑn]
Type A *-in and *-en did not undergo similar changes:
*[iˁn] > *[eˁiˁn] > *[eˁn] > *[en] (not *[jɛn], at least not at the Late Old Chinese or Middle Chinese stage)
*[eˁn] > *[en] (not *[jæn], at least not at the Late Old Chinese or Middle Chinese stage)
See Svantesson (2003: 155) on the
pharyngealization of the Khalkha lower series vowels /a u o/. I think
two-series vowel systems are an areal feature of much of the 'Altaic'
contact zone and Chinese and Tangut but not the rest of Sino-Tibetan.
David Boxenhorn has called into question whether pharyngealization is
necessary for Old Chinese as I once thought, but I'm reconstructing it
here anyway to push the parallel with Khalkha to the limit.
3. Last night I saw a commercial for Srixon [ʹsɹɪksan]. I was
surprised by initial [sɹ] in an English brand name. Tonight I learned
that Sri- is from the acronym SRI for Sumitomo
Rubber Industries Ltd. It's Japanese/English and has nothing to do
with Sanskrit śrī.
4. The Wikipedia article on Sanskrit śrī lists versions in many languages. One is Chế, the "Vietnamese transcription of honorific name prefix used among the Cham ethnic minority." That makes me wonder
how close the Vietnamization is to the modern Cham form
how close the modern Cham form is to the Sanskrit original
what changes occurred between the borrowing into Cham and the modern Cham form
5. What is the origin of the name Cantinflas? Is the resemblance to Fortinbras coincidental?
6. How old is the Korean expression 파이팅 phaithing / 화이팅 hwaithing from English fighting? I'm guessing it postdates the Korean War.
7. The Cantonese expression 加油 'add oil' is a lot newer than I would have thought.
8. I didn't know about Finnish sisu until today.
9. Tonight I learned the
kanji spellings 越歴 and 越歴機 for Japanese エレキ ereki 'elekiter' < Dutch
elektriciteit
(which 平賀源内 Hiraga
Gennai Japanized as ゐれきせゑりていと <wirekiseweriteito>, presumably
[irekiseːriteito] - why [i] and [eː] for Dutch [eː] and [i]?)
21.5.30.23:59: WHITE OX 4.19
𘬈𘭌𘲐𘲂𘭧𘰯𘬪𘲺
? uni ai ? sair par is nyair
'white ox year, four month ten nine day'
1. Yesterday I realized that the Late Old Chinese transcription 吐谷渾 *tʰɔʔ juok ɣuən now pronounced Tǔyùhún in Mandarin might have represented an original [tʰɔjɔʁɔn] in Tuyuhun.
The
Wikipedia article on the Tuyuhun says,
When the Chinese pilgrim monk, Songyun [宋雲 Song Yun], visited the region in 518, he noted that the people had a written language, which was more than a hundred years before Thonmi Sambhota is said to have returned from India after developing a script for writing the Tibetan language.
And yesterday I finally got to see that written language. But I
would like to see the original quotation. Although an endnote
cites Yeshe
De Project Staff (1986), I can't find any mention of the Tuyuhun in
the Google Books preview for that book, not even under their Tibetan
name འ་ཞ་ Ha-zha [ɣaʑa] (which doesn't sound Para-Mongolic).
2. Tonight KGMB reran Rap's Hawaii (1981) almost forty years after it originally aired here. It was neat to see Pidgin in closed captions, though some of the dialogue was 'corrected' into standard English, mistranscribed, or simply left out.
21.5.29.17:39:
WHITE OX 4.18
𘬈𘭌𘲐𘲂𘭧𘰯𘬌𘲺
? uni ai ? sair par nyêm nyair
'white ox year, four month ten eight day'
1. Back in 1996, Alexander Vovin introduced me to Juha Janhunen's 1994 hypothesis of the Parhae script as the parent script of both the Khitan large script and the Jurchen (large) script.
In March of this year, I learned of Alexander Vovin's "Two Newly Found Xiōng-nú Inscriptions and Their Significance for the Early Linguistic History of Central Asia" (2020) which made me realize that there could be a 'Xiongnuic' or 'Greater Sinitic' family of northern Chinese-based scripts including the lost Northern Wei script as well as the barely attested Parhae script and the much better attested the Khitan large script and the Jurchen (large) script.
And today 戴忠沛 Tai Chung-pui brought to my attention this
sample of what appears to be a heretofore unknown 吐谷渾 Tuyuhun script
at the grave of 慕容智 Murong
Zhi (650-691).
Maybe I am missing the obvious, but I don't see any exact matches
with Parhae, Khitan, or Jurchen characters at first glance other than
the fifth character in line 1, a lookalike of the Khitan large script
phonogram <ha>.
I do, however, think the first two characters at the top right
(which recur in the second line on the left) might be equivalent to
Chinese 周國 'Zhou state' referring to 武則天 Wu Zetian's Zhou
dynasty (690-705). The second of those characters is like the
Khitan large script character 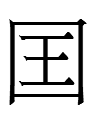 <STATE> with an extra horizontal stroke.
<STATE> with an extra horizontal stroke.
The first character in the second line is similar to the Khitan
large script phonogram  <pa> and Jurchen
<pa> and Jurchen  <pa>.
<pa>.
The fourth character in the second line is similar to the Khitan
large script phonogram 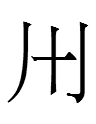 ,
possibly <ri> or <li>, corresponding to 里 *li in
Chinese transcription.
,
possibly <ri> or <li>, corresponding to 里 *li in
Chinese transcription.
The ninth character in the second line is similar to the Khitan
large script character  <gun> used to write the Sino-Khitan equivalent of Liao Chinese 軍 *gün
'army'.
<gun> used to write the Sino-Khitan equivalent of Liao Chinese 軍 *gün
'army'.
2. How did I not see Arakawa
Shintarō's translation of Viacheslav Zaytsev's landmark 2012 paper
on Nova N176
until today?
21.5.28.23:59: WHITE OX 4.17
𘬈𘭌𘲐𘲂𘭧𘰯𘲧𘲺
? uni ai ? sair par ? nyair
'white ox year, four month ten seven day'
1. Are there no desiderative verb forms in the Digital Corpus of Sanskrit, or am I doing something wrong? I couldn't find any desiderative forms of √bādh 'drive off' (more on this below), √gam 'go', or √kr̥ 'do'. I also can't find the other secondary verb forms: causatives and intensives.
2. According to Goldman and Sutherland's Devavāṇīpraveśikā (1987: 305-306) the desiderative stem of Sanskrit ā-roots is formed as follows:
partial reduplication of the root with i replacing ā
no change in the root itself (apart from sandhi rules)
suffixation of -sa- or -iṣa-
Examples:
√jñā 'know' > ji-jñā-sa- 'want to know'
√snā 'bathe' > si-ṣṇā-sa- 'want to bathe'
√khād 'chew' > ci-khād-iṣa- 'want to chew'
So in theory
√bādh 'drive off' > bi-bāt-sa- or bi-bādh-iṣa- 'want to drive off'
dh devoices to t before voiceless s
But according to Whitney (1885: 106), the verb has two possible desideratives, the unsurprising bi-bādh-iṣa- and the surprising bī-bat-sa- with a long vowel in the reduplication and a short vowel in the root. Goldman and Sutherland (1987: 308) mention the derived noun bī-bat-sā 'loathing' without commenting on its unusual form.
Another stem with a long vowel in its reduplication is mī-māṁ-sa- 'investigate' (with an idiosyncratic meaning) from √man 'think'. √man has an irregular lengthening of its vowel in the desiderative like a few other an and am-roots, whereas as far as I know the shortening of a in bat is unique.
5.29.0:09: n becomes ṁ before s: hence man + -sa- = maṁ-sa-.
5.29.16:39: Monier-Williams says the desiderative of the
desiderative of √man is mi-mā-m-iṣa- 'want to
investigate' with a regular short vowel in mi- and the third (!)
copy of the root reduced to -m-. How many other Sanskrit verbs
have desideratives of desideratives? Is it possible to write rules for
the formation of such tertiary forms?
21.5.27.23:57: WHITE OX 4.16
𘬈𘭌𘲐𘲂𘭧𘰯𘭬𘲺
? uni ai ? sair par ? nyair
'white ox year, four month ten six day'
Today I learned about the CJK TV series Strangers6. The Chinese Wikipedia has some strange katakana spellings for the names of Korean actors:
| Hanja |
romanization |
Chinese Wikipedia |
romanization |
expected katakana |
romanization |
| 趙在炫 |
Cho Chae-hyŏn |
ジャン・ハンソン | Jan Hanson |
チョ・ジェヒョン |
Cho Jehyon |
| 崔珉 |
Chhoe Min |
チェ・グィファ | Che Gwifa |
チェ・ミン | Che Min |
| 柳承莞 |
Yu Sŭng-wan |
チュ・グィジョン | Chu Gwijon |
ユ・スンワン |
Yu Sunwan |
| 金炳宣 | Kim Pyŏng-sŏn | キム・ビョンスン | Kimu Byonsun | キム・ビョンソン | Kimu Byonson |
| 李秀英 | Yi Su-yŏng | イ・ソジョン | I Sojon | イ・スヨン | I Suyon |
5.29.16:20: I suspect that in a couple of cases, the katakana was based on English-based romanizations (EBR): e.g.,
sŏn > EBR sun > スン sun
su > EBR soo > ソ so
But I can't explain the others.
2. How
did the Portuguese man o' war get its name?
21.5.26.23:19: WHITE OX 4.15
𘬈𘭌𘲐𘲂𘭧𘰯𘬦𘲺
? uni ai ? sair par tau nyair
'white ox year, four month ten five day'
Sorry, I fell asleep before I could blog last night.
Today I saw the Google Books preview of Eric C. Rath's Oishii: The History of Sushi (2021).
Rath says the kanji 寿司 for sushi "might mean 'felicitious rule' but instead are used solely for their sounds". I was initially surprised by 'felicitious', as 寿 normally represents Sino-Japanese ju 'long life', but I guess he got that from the native Japanese reading kotobuki 'congratulations'.
kotobuki (less commonly kotohogi) is from Old Japanese kətə-pok-i 'word-pray.for.good.outcome-INF'. Both modern forms are irregular. I would expect *kotohoki. Let's look at the irregularities:
-b-: rendaku: voicing at a morphemic boundary
-u-: possibly reflecting raising of pre-Old Japanese *o in medial position
I just learned from Wiktionary that Kotobuki as a surname can also be spelled 琴吹 <HARP BLOW>.
Back to sushi:
The word also has two logographic spellings, and tonight I learned from
Wikipedia
that they are regional: 鮨 was the Edo spelling and 鮓 was the
Osaka spelling. How many such regional spellings are there? (And has
there been any investigation of regional patterns in nôm spelling?)
According to one hypothesis that dates to at least the end of the seventeenth century, the Japanese word 'sushi' was derived from the word sui, meaning 'sour tasting'.
I wonder how many readers would think that sui somehow got a -sh- inserted into it to become a noun. Of course that's not what actually happened. The reality is somewhat the other way:
the adjective originally had an attributive form su-ki
and a final predicative form su-shi (the source of the noun): su-ki
X 'sour-tasting X' vs. X su-shi 'X is sour tasting'
su-ki became su-i via lenition
su-i came to be used for final predication as well as attribution
Rath ends that last sentence I quoted with a reference to a footnote
that I can't see in the preview. Perhaps it explains that the noun sushi
was from an old form su-shi of the modern adjective su-i.
The noun sushi is somewhat analogous to male -shi names derived from adjectives: e.g., Yasushi < yasu-shi 'at.ease-shi'.
-shi is usually regarded as a final predication suffix, but its early Old Japanese ancestor -si can also be an attributive suffix, and the attributive can function as a nominalizer: e.g.,
na-si-ni
not.be-ATTR-LOC
lit. 'in not being' = 'because there is no' (Kojiki song 23)
na-si there takes the locative as if it were a noun.
For further discussion of Old Japanese -si, see Vovin's grammar (2020: 406-411).
I regard names of the type Yasushi as vestiges of -si
as a nominalizer.
Next: The accent of sushi.
21.5.24.22:48:
WHITE OX 4.13
𘬈𘭌𘲐𘲂𘭧𘰯𘯙𘲺
? uni ai ? sair par ? nyair
'white ox year, four month ten three day'
Sorry, another interruption in my series on the Khitan small script character 𘲧 <SEVEN>: Last night I found John Kupchik's "Austronesian lights the the way: The origins of the words for 'sun' and other celestial vocabulary in Old Ryukyuan" (2021) which debunks something I believed in for a long time: the derivation of Proto-Ryukyuan *tenda 'sun' (> Okinawan tida) from premodern Sino-Japanese 天道 tendau 'id.'
I already knew about a phonetic problem with that etymology: the
irregular, sui generis correspondence of SJ -au to PR *-a
instead of PR *-au.
But Kupchik also notes a semantic problem: Sino-Japanese 天道 'heaven-road' did not shift in meaning to 'sun' until the late 16th century, long after Proto-Ryukyuan broke up. So the resemblance between *tenda and tendau is coincidental.
21.5.23.23:56: WHITE OX 4.12
𘬈𘭌𘲐𘲂𘭧𘰯𘲝𘲺
In brief, the pros and cons of reading the Khitan small script character 𘲧 <SEVEN> as dir (Kane 2009: 193):? uni ai ? sair par ? nyair
'white ox year, four month ten two day'
d-: matches the d- of Khitan 𘳄𘮿 <da.313> 'seventh', Proto-Mongolic *dol/u.xa/n 'seven' and *dal.a/n 'seventy' (Janhunen 2003: 17) and Jurchen dalhon 'seventeen'. Also matches the unaspirated *t- of the Liao Chinese transcription 迪烈 *tiʔliêʔ for the name 𘲧𘰭 <SEVEN.n>. (Liao Chinese had no *d-, so *t- was the best approximation. It is even possible that Khitan d was phonetically [t]; if so, then the Liao Chinese transcription perfectly matched the Khitan initial.)
-i-: matches the *i of the Liao Chinese
transcription 迪烈 *tiʔliêʔ but I would expect -a- on the
basis of the other evidence above. (Proto-Mongolic *o in *dol/u.xa/n
is due to irregular labial assimilation with the following *u; contrast
with *dal.a/n 'seventy' which retains the original *a
and lacks a labial vowel triggering assimilation.)
-r: does not match Proto-Mongolic *-l- or Jurchen -l-. Kiyose (1977: 133), however, reconstructs Jurchen 'seventeen' as darhon with *-r-. The Ming Chinese transcription of Jurchen 'seventeen' has 爾 <r> which could represent either syllable-final -l or -r since Ming Chinese had no *-l. See Kane (1989: 115) for examples of 爾 for a Jurchen liquid - presumably *-l - corresponding to Manchu -l.
Next: More on the problem of the vowel of Khitan 'seven'.
20.8.15.23:59: WHITE RAT 6.26
? qulugh ai ? sair tau nyair
'white rat year, six month, twenty six day'
Today is the seventy-fifth anniversary of the 玉音放送 Jewel Voice Broadcast that ended World War II.
I don't know what the Khitan word for 'seventy-five' was, and I fear I never will know. But at least I know how to write it.
In the Khitan large script, 'seventy-five' is
<SEVENTY tau>
<SEVENTY> is a logogram whose reading is unknown. One could guess that it was like Janhunen's (2003: 16) Proto-Mongolic *dala/n 'seventy', but I always fear the 'sorok scenario' in which an expected, inherited numeral has been replaced by a completely different numeral¹.
<SEVENTY> is obviously graphically related to
<FIFTY> <SIXTY> <EIGHTY>.
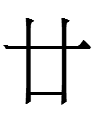
<tau> 'five' is identical in shape to Chinese 五 'five'.
The logic of the <FIFTY>-<EIGHTY> characters built around 仒 is unknown.
The Jurchen large script is commonly thought to be derived from the Khitan large script, yet the Jurchen characters
900
<SEVENTY FIVE> nadanju shunja
bear no resemblance to the Khitan large script characters for 'seventy' and 'five' or to anything in Chinese. Did the Jurchen arbitrarily decide to deviate from the Khitan model? Or is Juha Janhunen right in hypothesizing that the Jurchen large script is not derived from the Khitan large script?
The Jurchen large script character <SEVENTY> vaguely resembles
<SEVENTY>
in the Khitan small script, but the, um, small degree of similarity is probably a coincidence since there doesn't seem to be any other overlap between the Jurchen large script and the Khitan small script.
Unfortunately, only a few characters of the Jurchen small script survive, and none of them have known functions or resemble any of the above characters for 'seventy':
No one knows if the Jurchen small script had logograms for the tens
like the other three scripts. In theory, nadanju 'seventy'
could have been written as <SEVEN ju>.
¹In Old East Slavic, sorokŭ 'forty pelts' replaced četyredesęte 'forty', so Russian and Ukrainian sorok and Belarusian sorak 'forty' are not cognate to Polish czterdzieści, Serbo-Croatian četrdeset, etc.
20.8.14.23:54: WHITE RAT 6.25
? qulugh ai ? sair tau nyair
'white rat year, six month, twenty five day'
Today on the Discovery Channel I saw bits of Alien
Sharks featuring frilled sharks
(among other types of sharks).
What is the etymology of Japanese 羅鱶 rabuka 'frilled shark'? -buka is the combining form of 鱶 fuka 'large shark', but what is 羅 ra? Is it Sino-Japanese 羅 ra 'net'? Or is 羅 ra a phonogram for something else? In any case, no native Japanese word can begin with r-.
fuka 'large shark' has nothing to do with the Chinese
morpheme 'dried fish' (Mandarin xiǎng, Cantonese soeng2,
etc.) that 鱶 originally represented. Why did the Japanese write their
native word for 'large shark' as 鱶 'dried fish'?
20.8.13.23:59: WHITE RAT 6.24
? qulugh ai ? sair ? nyair
'white rat year, six month, twenty four day'
1. Long ago I thought the Taiwanese car company Yue Loong was Mandarin Yuelong
(tones unknown). But it was actually 裕隆 Yùlóng 'abundant' +
'eminent'. And it's been Yulon in English since 1992.
I had heard of Yulon's sub-brands but didn't know their Mandarin names until yesterday:
In theory the Mandarin names could be spelled in generic phonograms to be closer to the English names (e.g.,
勒克斯健 Lèkèsījiàn 'bridle' + 'overcome' + 'this' +
'healthy'
托比 Tuōbǐ 'hold in palm' + 'compare'
), but the actual names have better semantics.
2. Until yesterday, Yulon was the only Taiwanese automaker I had
ever heard of. I learned of 福特六和 Ford Lio Ho when I saw a
reference to
its Mazda Isamu Genki (< Japanese 勇 Isamu [a male name]
+元気 genki 'good spirits'). I can't find a Chinese version of
that name. Was Isamu Genki only written in Roman letters?
How was Isamu Genki pronounced in Mandarin (which doesn't have
the syllables gen or ki)?
Not counting the Mazda part: 馬自達 Mǎzìdá, whose z is [ts], not [z]. Normally Japanese names retain their original kanji in Mandarin pronunciation: 松田 Matsuda would become Sōngtián. However, in this case, Matsuda 'Mazda' was phonetically transcribed, probably because the car brand is written in katakana (i.e., without kanji) as マツダ. Windows 10's IME's first option for Matsuda is マツダ. The surname 松田 comes second. I suppose the car brand is more common. But in Google, マツダ has 58.1 million results whereas 松田 has 69.6 million results.
8.14.0:49: I just learned that in Hong Kong, 'Mazda' is Cantonese 萬事得 Maan6 si6 dak1 'ten thousand' + 'affair' + 'get'. 萬事得 clearly wasn't coined with Mandarin in mind since it is pronounced Wànshìdé in Mandarin.
Conversely, the Mandarinization 馬自達 still works in Cantonese: Maa5
zi6 daat6 isn't far from Matsuda.
3. I had first heard of the マツダ・シャンテ Matsuda Shante Mazda Chantez as a child, long before I studied French. Now I can see that Chantez is a second person plural present indicative verb form.
8.14.22:12: And now I wouldn't pronounce the final -z. I
would have when I was ten and didn't know the katakana spelling, much
less French.
4. Tonight I had basa for
dinner. I had eaten that fish before but had never heard of its name
which is from Vietnamese ba sa
(in turn from Khmer បាសាក់ <pāsāk'> [ɓaːsak] 'Bassac', also
Vietnamized as Bát Sắc and Ba Thắc).
8.14.20:14: Does the Vietnamization Ba Thắc date from a
period prior to the fortition of *ɕ to th [tʰ]? Was the
name borrowed from a language whose name for the river was something
like *ɓaːɕak? Was that language something other than Khmer
(which has never had ɕ as far as I know), or was it a variety
of Khmer with [ɕ] for /s/?
5. I hadn't heard of a derecho until
today. Midwestern news doesn't get much coverage in Hawaii. I saw the
word in an AP story on p. 4 of the Star-Advertiser.
6. The word featured in today's Star-Advertiser Japan section is 3密 sanmitsu: 'the three C's the public should avoid - closed spaces, crowded places and close contact - to prevent spread of COVID-19'.
8.14.22:50: 密 mitsu < *mit is 'close, dense'. The sanmitsu 'three mitsu' are
密閉 mippei 'sealed' < 密 mitsu + 閉 hei < *pei 'to close'
密集 misshū 'crowding' < 密 mitsu + 集 shū 'collect'
密接 missetsu 'close contact' < 密 mitsu + 接 setsu 'contact'
I don't know how old those compounds are. Even if they postdate the shifts of *-t > -tsu and *p- > h-, they are pronounced with rules dating back to when 密 had *-t and 閉 had *p-.
20.8.12.23:59: WHITE RAT 6.23
? qulugh ai ? sair ? nyair
'white rat year, six month, twenty three day'
1. Last night I was surprised to learn that Malaysia's Proton car brand is a Malayo-Euro hybrid:
PROTON < PeRusahaan Otomobil Nasional
Perusahaan 'industry' is from Malay usaha 'effort' plus the circumfix per- ... -an.
2. A lot of Asian cars have un-Asian model names, but at least some Proton model names are exceptions. Until yesterday, the only Proton I had ever heard of was the Saga, but then I learned of the company's later models:
Saga Iswara < Sanskrit īśvara- 'lord'
Satria < Malay satria 'warrior' < Sanskrit kṣatriya- 'member of the warrior class'
Perdana < Malay perdana 'principal' < Sanskrit pradhāna- 'id.'
Juara < Malay juara 'champion' < Prakrit juāra- 'gambler' < Sanskrit dyūtakara- 'gambler'
3. Until this morning I had forgotten about Asüna, a pseudo-foreign name used by General Motors in Canada. The umlaut has the same 'othering' function in the far more famous pseudo-foreign name Häagen-Dazs. I finally learned the origin of that name tonight:
Reuben Mattus invented the phrase "Häagen-Dazs" in a quest for a brand name that he claimed was Danish-sounding; however the company's pronunciation of the name ignores the letters "ä" and "z"; letters like "ä" or digraphs like "zs" don't exist in Danish, but the similar words "hagen" and "das(s)" that also correspond to the company's pronunciation of its name mean "the chin" and "outhouse/toilet", respectively, in Scandinavian languages, with "das(s)" being coarse slang derived from German. According to Mattus, it was a tribute to Denmark's exemplary treatment of its Jews during the Second World War, and included an outline map of Denmark on early labels. Mattus felt that Denmark was also known for its dairy products and had a positive image in the United States. His daughter Doris Hurley reported in the 1999 PBS documentary An Ice Cream Show that her father sat at the kitchen table for hours saying nonsensical words until he came up with a combination he liked. The reason he chose this method was so that the name would be unique and original.
4. Tonight I also learned about Häagen-Dazs' extinct sort-of-competitor Frusen Glädjé which has a near-Swedish name.
5. The 'foreignness' of Häagen-Dazs isn't as strong in
Mandarin 哈根達斯 Hāgēn-Dásī.
It's not possible to replicate the flavor of an umlaut or the digraph zs
in Chinese characters. There is nothing unusual about the phonograms
哈根達斯.
6. Tonight I discovered that Wikipedia has a whole article about foreign branding.
LOL: "Au Bon Pain, a bakery cafe with a French name, was founded in Boston."
Superdry's use of pseudo-Japanese has long bugged me. Turns out Superdry is British!
I should have figured Pret a Manger was British too. I used to eat there when I lived in London.
(8.13:0:51: Pret
turns out to have shops in France! I never saw them in Paris or
Lyon.)
The "Roland" name was selected for export purposes, as Kakehashi was interested in a name that was easy to pronounce for his worldwide target markets. The name was found in a telephone directory, and Kakehashi was satisfied with the simple two-syllable word and its soft consonants. The letter "R" was chosen because it was not used by many other music equipment companies, and would therefore stand out in trade show directories and industry listings. Kakehashi did not learn of the French epic poem The Song of Roland until later.
(Added quotation 8.13.0:53.)
20.8.11.23:07: WHITE RAT 6.22
? qulugh ai ? sair ? nyair
'white rat year, six month, twenty two day'
1. Today Kamala Devi Harris became the Democratic nominee for vice-president of the United States. Last week I wrote about Tamil, and by coincidence her mother Shyamala Gopalan is Tamil. The Tamil Wikipedia spells Harris' name in Tamil as
கமலா தேவி ஹாரிஸ்
<kamalā tēvi hāris·>
Tamil has no <d>.
I didn't expect Sanskrit devī 'goddess' to be
borrowed
into Tamil with a final short vowel [i]. Tamil ி <i> looks like
Devanagari long ी <ī> but is short.
I also didn't expect English short [æ] in Harris to be borrowed into Tamil as long [aː].
Oddly Gopalan has no Tamil Wikipedia entry. The Malayalam Wikipedia spells her name as
ശ്യാമള ഗോപാലൻ
<śyāmaḷa gōpalan>
I didn't expect Sanskrit śyāmalā with a dental l
and long feminine ā to be borrowed into Malayalam as ḷa.
Apparently the Tamil spelling of Shyamala Gopalan is
சியாமலா கோபாலன்
<ciyāmalā kōpālaṉ·>
Tamil has no initial clusters, <ś>, or <g>.
Why do Malayalam and Tamil add different nasals to Sanskrit go-pāla-
'cow-protector'?
Topics 2-7 are leftovers from yesterday. I wanted the entry on the late John Okell to
stand alone without the usual date title.
2. What is the etymology of Sanskrit cārvāka-?
3. I was surprised that the English Wikipedia
entry for Mysore didn't include the Kannada spelling
ಮೈಸೂರು
<maisūru>
Is maisūru really from Sanskrit Mahiṣāsura? I
wonder if it's a folk etymology.
4. Rama and Sita were siblings!? They were in some tellings of the Rāmāyaṇa.
I should read AK
Ramanujan's "Three
Hundred Ramayanas: Five Examples and Three Thoughts on Translation"
(1987).
5. Maybe the most important word I encountered
yesterday was Nahḍa
with that most Arabic of sounds, the ḍād.
6. The
Wikipedia article on Naḥda mentioned Rifa`a
al-Tahtawi's تخليص الابريز في تلخيص باريز Takhliṣ al-ibrīz fī
talkhīṣ Bārīz (1834). Why was 'Paris' borrowed with a final -z?
The Arabic Wikipedia's article on Paris is titled باريس Bārīs
with a final s. Is Bārīs a spelling-based borrowing or
was it borrowed before Paris lost its final [s] in French?
7. Yesterday was the thirty-fifth anniversary of the release of the Japanese movie オーディーン 光子帆船スターライト Odin: Kōshi hansen Sutāraito (Odin: Photon Sailer Starlight, 1985). I never paid much attention to the English title until last night when I learned that sailer isn't a misspelling of sailor. Sailer and sailor are two spellings of the same earlier word that have become associated with different (albeit related) meanings.
8. Tonight I learned of Chamberlain's (2018) term Kri-Mol for Vietic from Wikipedia. I recognize Kri, but what is Mol?
The adopted term Kri-Mol, or Kri-Molic captures the earliest essential bifurcation between Mol-Toum (Cheut, Toum-Phong, and Việt-Mường) on the one hand, and Nrong-Theun (Mlengbrou, Kri-Phoong, Thémarou, Atel-Maleng, and Ahoe-Ahlao) on the other. Mol is an autonym used by the Mường, pronounced mɔl or mɔɯ. (Use of Mol also eliminates confusion with the Tai speaking Mường in Nghê An.) (p. 9)
I would add that Mol, unlike the borrowing Mường from Tai, is presumably a native word. (Autonyms aren't necessarily native: e.g., Nihonjin 'Japanese person' contains no Japonic morphemes.)
I confess I never heard of the Toum language until now. It doesn't
have a Wikipedia entry (yet).
And what are Nrong and Theun?
The term Nrong-Theun is derived from the names of rivers, the Theun being the main one. Nrong, a tributary of the Theun, is phonemically /ɲrɔːŋ/ (called the Nam Noy in Lao) and Theun is phonemically /thɤːn/. The Theun flows from south to north, the river name changing to Kading about two-thirds of the way before emptying into the Mekong. 'Theun' is the old French spelling and is retained as it is used universally on maps and in the literature. (p. 9)
I would be more eager to adopt this new term if only Chamberlain provided a justification for it based on shared innovations. What shared innovations characterize his two subgroups Mol-Toum and Nrong-Theun? The word innovation does not appear in his 175-page paper (more like a monograph).
If Chamberlain wishes to replace Vietic with Kri-Mol, why does he use the term Vieto-Katuic?
| Vieto-Katuic |
|||
| Kri-Mol =
Vietic |
Katuic | ||
| Nrong-Theun |
Mol-Toum |
West (Brou) |
East (Katu, etc.) |
(based on Chamberlain 2018: 12)
Why not Kri-Katuic? (Can you tell I'm fond of Kri?) And why not Nrong-Mol and Nrong-Katuic for consistency with Nrong-Theun? Is it a good idea to mix river names (Nrong) with ethnonyms (Mol) and/or language names (Kri is both an autonym and a language name) when naming language clades?
9. Normally Sino-Vietnamese refers to borrowings from Chinese in Vietnamese. Chamberlain (2018: 11) uses the term in a new way (at least for me):
Vietnamese is in reality Sino-Vietnamese (there is no non-Sino variety), originally a coastal creole, with huge numbers of Sinitic vocabulary, 70 percent of the lexicon according to Phan (2010), though with core vocabulary that is essentially Austroasiatic.
If Vietnamese is (was?) a creole, does it make sense to consider it a Kri-Mol language? If Haitian Creole is not a Romance language, then Vietnamese shouldn't be a Kri-Mol language. Yet Chamberlain (2018: 12) places it in his tree under Viet-Muong.
I wrote "was?" above because Chamberlain's phrase "originally a
coastal creole" could be intrepreted to mean 'originally a creole but
no longer a creole' or 'originally coastal but no longer only coastal'.
10. Chamberlain (2018: 162) points out that
'butterfly' is not the best word for comparative phonological purposes as it tends to be subject to expressive and reduplicative forces in many languages. English butterfly and its playful twin flutterby is a good example.
I had never heard of flutterby.
What makes 'butterfly' less stable than other zoonyms? (I guessed zoonym was a real word, and it is!)
11. How have I never heard of Anahita before? I found out about her when looking for the Wikipedia article on Nahḍa (see topic 5).
12. I just learned that Greek Páris is unrelated to the name of the city of Paris which is of Gaulish origin.
20.8.10.23:50: RIP SAYA JOHN
John Okell passed away sometime between the night of August 2nd and the morning of August 3rd. I had no idea he was gone until just now.
I first met him in Thailand five years ago next month. I was a student in his introductory intensive Burmese course - the two greatest weeks in all my years of study of any subject. I never learned so much so fast. I then studied Burmese with him in London and in Burma. Here in Hawaii I have been using his books for the last year to attempt to retain what he taught.
No words of mine can describe the greatness of ဆရာ <charā> [sʰəja˩] 'teacher' John. So I have linked to this Irrawaddy profile which I read shortly after meeting him for the first time and this obituary at Frontier Myanmar.
Thank you, Saya John. I could not have worked on Pyu without what I learned from you.
20.8.3.14:06: WHITE RAT 6.14
? qulugh ai ? sair par ? nyair
'white rat year, six month, ten four day'
1. Today I was surprised to learn that the Sogdian script had a variant of the letter shin (U+10F45 SOGDIAN INDEPENDENT SHIN) to transcribe Chinese 所 (which had an initial *ʂ- in Middle Chinese; modern standard Mandarin s- is irregular).
2. The Sogdian letter ayin (U+10F12) is quite unlike the others in
shape and has no descendant in the Old Uyghur line of scripts leading
to the Mongolian and Manchu scripts. Where have I seen such a spiral
character before? Khmer ៚ គោមូត្រ <gomūtra> [koːmuːt] 'cow urine'
first came to mind, but it has a tail and isn't coiled enough (and in
some fonts isn't coiled at all). I have seen spiral characters in other
Indic scripts, but they too aren't as coined as Sogdian ayin.
3. Today I mailed my Hawaii primary election ballot which had Ilocano instructions for getting a translated version. Ilocano is the third most spoken home language in Hawaii after English and Tagalog if Pidgin is not counted. Wikipedia has an unsourced figure of 85% for Ilocanos in the Filipino population in Hawaii.
Today I learned the term Ilocandia for "the traditional homeland of the Ilocano people".
4. Today I learned that the 'Sea Peoples' are a modern classification for peoples which had Egyptian exonyms. For years I just assumed they were so mysterious that they didn't even have exonyms!
20.7.28.22:48: WHITE RAT 6.8
? qulugh ai ? sair nyêm nyair
'white rat year, six month, eight day'
1. When practicing Tangut today, I came across the character
𘛢
5264 1mer4 'soldier'
with rare left and right-hand components.
The left side 𘩷 (Boxenhorn code wai) is also in
𘛣 5505 1sha3 (transliteration character)
𗞔 4135 1sha3 'incense'
𗶯 5492 1sha3 'imperial carriage'
𗞼 4197 2nu4 'to light a torch'
similar to 4135 'incense' above except for 𘦳 'hand' instead of 𘢶; there is no 'fire' component
There is no obvious phonetic or semantic common denominator shared
by the five characters with <wai>.
The right side (Boxenhorn code dar; I can't find it in Unicode) is
only in one other character:
𗡠
0271 2bi'4 (second syllable of 𗡢𗡠 0702 0271 1to'4 2bi'4 'to seek')
The rare component <dar> is incorrect in the Mojikyo font
versions of 0271 and 5264. Mojikyo 0271 has the more common component 𘡭
<dao> (in 32 characters) instead of <dar>, and Mojikyo 5264
has <dar> with a slanted top stroke and without a right-hand
diagonal stroke.
There is no obvious phonetic or semantic common denominator shared by the two characters with <dar>.
Do you think the graphic etymology in the Tangraphic Sea for
5264 will make any sense out of this? Let's find out tomorrow.
2. Last night I played episode 43 of 科学忍者隊ガッチャマンF Gatchaman F (1979-80) on its fortieth anniversary. The world of Gatchaman is a parallel Earth with different place names. I wonder if anyone has ever compiled all those names and even tried to put them on a map.
One such name that came up in episode 43 was ニュージョーク Nyūjōku, an obvious play on ニューヨーク Nyūyōku 'New York'. In the subtitles, Nyūjōku was rendered with an umlaut as New Jörk. Is the umlaut canonical, or was that just the subtitler's idea? Normally ö corresponds to Japanese e, not o: e.g., Röntgen became レントゲン Rentogen.
I seem to encounter these stand-in names more often in Japanese rather than American fiction. I just heard a reference to the country of パキスター Pakisutā 'Pakistar' in episode 5 of 宇宙戦士バルディオス Space Warrior Baldios (1980-81) which first aired forty years ago today.
20.7.9.23:54: WHITE RAT 5.19
? qulugh ai tau sair par ish nyair
'white rat year, five month, ten nine day'
1. Last night I couldn't post on time because my battery was out of
power and I couldn't recharge. That turns out to have been for the best
since I was able to enlarge the post tonight.
What would the Tangut call a battery? I'm guessing they would borrow the Chinese word 電池 'lightning pond' for 'battery' (itself a borrowing from Japanese) in one of three ways:
1. via direct phonetic borrowing from Mandarin (either standard diànchí or its local equivalent)
2. via conversion into 'Sino-Tangut': the conventional Tangutization of early 2nd millennium Xia Chinese: e.g.,
𗽞𗳶
3666 1456 1then4 1chhi2
a phonetic approximation of Xia Chinese *3then4 'lightning'
and *1chhi3 'pond'.
3. via a calque such as
𗬔𗒈
3665 4707 1lhaq 2jen2 'lightning pond'
which contains the word for 'pond' I wrote about last night.
2. The word featured in this week's Star-Advertiser Japan section is リア充 riajū 'people leading a full life' which is in Windows 10's IME. It's in the English Wiktionary but not the Japanese Wiktionary. The word does, however, have its own Japanese Wikipedia article. The newspaper's definition which I give above doesn't make clear that 'full' means 'in real life'. riajū is an abbreviation of リアル riaru 'real (life)' and 充実 jūjitsu 'fullness'. riajū fits the frequent four-mora formula for Japanese abbrevations. (jū is one syllable but has two moras.)
20.7.8.23:59: WHITE RAT 5.18
? qulugh ai tau sair par nyêm nyair
'white rat year, five month, ten eight day'
I did something unprecedented. I did almost none of my language exercises on Sunday due to an emergency. And I did none on Monday and Tuesday because of my extracted tooth. I wasn't supposed to lie down after the surgery, and I handwrite lying down. I don't have a desk with a chair. So I slept sitting up for two nights in a row and neglected my languages. Today I did nearly four times the usual amount of exercises. I would do even more if I didn't have other things to do.
The Tangut exercises for today included part of the Tangut law code
(3.4.2. punishment for salt crimes). What leapt out at me was character
4707
𗒈
for 2jen2 'pool, pond'.
The Tangut script is supposed to be full of semantic compounds. In theory that should make the script easy to learn. All words in the same semantic field should be written with a common component. And the components of each character should play a part in a neat mnemonic 'story'. But that bears little resemblance to reality.
Here's the 'story' of 4707 according to the Tangraphic Sea:
𗒈=𗓰+𘌩
4707 2jen2 'pool, pond' =
top of 4693 1na1 'deep' (i.e., the grapheme of unknown function which I call the 'horned hat': 𘡊) +
all of 5088 1chhwi3 'salt'
'Deep salt'? That's not what first comes to mind when I think of
pools or ponds. Neither 1na1 nor 1chhwi3 sound like 2jen2,
so 'deep' and 'salt' cannot be phonetic.
What surprises me even more is the absence of the semantic element 𘠣 'water' derived from Chinese 氵 'water'. Compare 4707 with the Chinese character for its Chinese equivalent, 池 <WATER.也>, a transparent semantophonetic compound. (也 is phonetic.)
Conversely, 'water' turns up in Tangut characters for morphemes that have no obvious or inherent connection to water: e.g.,
the demonstrative 𗋕 2019 1tha4
7.9.22:45: then again, Chinese 汝 'thou' also has 氵 <WATER>, but that's because 汝 originally represented the name of a river and was repurposed to represent a homophonous pronoun
the perfective prefix 𗋚 2590 2vy3-
7.9.22:49: the Tangraphic Sea derives the left side of the demonstrative 𗋕 2019 1tha4 from 2590 which makes no semantic or phonetic sense
𗂧 2937 2lheq4 'country'
7.9.23:01: Did the inland Tangut think of countries as being
bordered by rivers? Oddly only one of three Tangut characters for
'river' words has 𘠣 <WATER>: 𗡴𗲌𗊧. And that character with 𘠣 <WATER> represents a Chinese loanword 1chhwan3
(< Xia Chinese 川 *1chhwan3).
Contrast with Chinese characters for 'river': 河 and 江 both contain 氵 <WATER>, and 川 is a pictograph of flowing water.
What is 'water' doing in those characters? It serves no obvious
phonetic function, as those morphemes have no phonetic common
denominator in Tangut. Those last two words are key.
7.9.22:23: In Old Chinese, 也 was *Cilajʔ, and 池 was *RIlaj (with *I = a higher series vowel other than *i: *u and/or *ə). But the two have diverged considerably in modern languages: e.g., in Mandarin, 也 is yě and 池 is chí. The different rhymes reflect different minor syllable vowels:
Old Chinese *CiCaj > Mandarin ye, -ie
Old Chinese *CICaj > Mandarin -i
Old Chinese *(CA)Caj > Mandarin -e ~ -o ~ -uo ~ wo (depending on initial)
*A could have been *a or perhaps *e or *o
monosyllabic *Caj has the same reflexes as *CAcaj
The Mandarin spellings above are in pinyin and are not phonetic: e.g., -o, -uo, and -wo are all [wo], but [wo] is spelled o after labials, uo after other consonants, and wo by itself.
20.7.7.23:47: WHITE RAT 5.17
? qulugh ai tau sair par ? nyair
'white rat year, five month, ten seven day'
1. Leftover from July 4th: Seeing only the English title of Dream of
the Emperor
led me to think that the Korean TV show was about a Chinese emperor or
one of the two rulers of the short-lived Korean Empire, but in fact the
Korean title is 대왕의 꿈 Taewang-ŭi kkum 'Dream of the Great King'
- specifically 武烈王 King Muyŏl of
Shilla (r. 654-661). Wikipedia's Muyŏl article translates the show
title as The King's Dream.
2. Yesterday I finally learned what oncology was.
And I found its translation equivalents using Wikipedia's left-hand
menu:
Japanese 腫瘍學 shuyōgaku 'swelling ulcer study'
Korean 腫瘍學 chongyanghak (< Japanese)
Chinese 腫瘤學 zhǒngliúxué 'swelling tumor study'
Vietnamese 癰疽學 ung thư học 'cancer (< 'ulcer ulcer') study'
Today I learned the Thai equivalent is วิทยามะเร็ง
<vidyāmaḥrĕṅa> wítthayaamareng 'study [of] cancer'. I'm
guessing มะเร็ง mareng is a loan from Khmer ម្រេញ
<mreña> mrɨɲ 'cancer'. (-ɲ is not a
possible Thai coda.)
3. Today I learned sofa is a borrowing from Arabic صفة ṣuffa 'long seat made of stone or brick' - but not 'sofa'! Wiktionary lists five distinct Arabic words for 'sofa' (the last is Iraqi):
أريكة 'arīka
(etymology unknown)
كنبة kanaba
(< French canapé)
تخت takht (< Persian)
ديوان dīwān
(cf. English divan
from Turkish, < ult. Sumerian 𒁾 dub 'clay tablet' + Old Persian vahana-
'house')
قنفة qanafa (< French canapé)
4. Another English furniture word of Arabic origin is mattress.
5. Wiktionary transliterates the Middle Persian ancestors of dīwan
and takht as <dywʾn'> and
<tʾht'>.
Mackenzie
(1971: xiv) calls <'> an "otiose stroke". Is
<'> truly superfluous like an extra dot in some Chinese character
variants?
6. Inscriptional
Parthian numbers remind me of how I used to avoid
writing certain numbers when I was very young: e.g., '5' is 𐭻𐭸
<4 1> (written from right to left). But the difference is
that Inscriptional Parthian
had no unique symbol <5> whereas I may not have wanted to write 5.
(I'm not certain 5 was on my list of taboo symbols.)
7. How did Proto-Iranian Hwah-
(ʔwah-?) 'dwell' become Middle Persian gyāg 'place'? I've
never seen the sound change Hw- > gy- before.
8. I wonder what it was like to be a Nanjing dialect enthusiast from
the West watching the rise of the Beijing dialect. I can imagine after
reading what Gabelentz
wrote in 1881:
Only in recent times has the northern dialect, pek-kuān-hoá ['northern officer speech'], in the form [spoken] in the capital, kīng-hoá ['capital speech'], begun to strive for general acceptance, and the struggle seems to be decided in its favor. It is preferred by the officials and studied by the European diplomats. Scholarship must not follow this practise. The Peking dialect is phonetically the poorest of all dialects and therefore has the most homophones. This is why it is most unsuitable for scientific purposes.
9. Gabelentz would have been sad to see the Beijing-based standard taught worldwide. Conversely, it is not easy to find modern Nanjing forms despite the prestige of Nanjing in the past. Xiaoxuetang does not list Nanjing forms for 南 'south' and 京 'capital', the two morphemes that make up thename Nanjing. The English Wikipedia's article on the Nanjing dialect doesn't even sketch the phonology or given a single example word, much less a sentence. Fortunately that article does link to a couple of resources on the Nanjing dialect:
The title gives away key differences between Nanjing (Langjin) and Beijing:
Nanjing has merged *n- and *l- into l-: *nan > lang 'south'
Nanjing has merged *-an and *-ang into [ã]: again, *nan > lang [lã] 'south'
Nanjing has i instead of yi
Did the above mergers exist in Gabelentz' time? They would reduce the number of possible syllables in Nanjing.
cnvoicedic.com displays the pronunciations of Chinese characters in Guangyun (but in whose reconstruction?), Southern Min, Cantonese, Chaozhou, Hakka, Shanghainese, Suzhou, 围头 Weitou, 无锡 Wuxi, Nanjing, and the Beijing-based standard.
麻 mrä 'hemp' (level tone; no final tone letter)
马 mräx 'horse' (rising tone; -x)
骂 mräs 'scold' (departing tone; -s)
The use of -r- for Grade II reminds me of my short-lived belief in 1994 that Middle Chinese still had medial -r- (!). I assume -r- in this reconstruction is a notational convention like the tone letters and not a literal medial liquid.
20.7.6.23:30: WHITE RAT 5.16
? qulugh ai tau sair par ? nyair
'white rat year, five month, ten six day'
Today I had my tooth extracted. Before my appointment I looked for cognates of Tangut 𘟗 0039 2korn1 'tooth' using STEDT's 'root canal' tool which was particularly fitting (because the tooth I lost had just undergone a root canal). STEDT derives the Tangut word from Proto-Tibeto-Burman *k(w/y)aŋ 'tusk/molar'.
Even if Proto-Tibeto-Burman (in the sense of an ancestor of all non-Chinese Sino-Tibetan languages) were valid, that etymology seems unlikely given my interpretation of Jacques' (2014) sound changes in Tangut:
| pre-Tangut |
Tangut |
Potential examples |
| *Rkaŋ |
1kor1 |
𘙴𗏬 |
| *Rk[a/o/u/e]mH |
2korn1 |
𘟗𗡹𘁩 |
(There is no Tangut syllable 2kor1 which would have developed from pre-Tangut *Rkaŋh.)
The nasal vowel of Tangut 2korn1 (pronounced something like
[kõʳ]) points to an earlier *-m rather than an earlier *-ŋ.
Perhaps the true cognates of Tangut 2korn1 are those which
STEDT derives from Proto-Tibeto-Burman
*gam 'jaw, chin, molar'. A couple of forms of interest at
STEDT:
'eastern rGyalrong' tə swa kam 'tooth (incisor)' (Sun Hongkai 1991)
'rGyalrong' tə swa rgu 'molar' (Dai 1989)
The language labels are unfortunately not very specific.
kam looks like the pre-Tangut form, particularly if the
pre-Tangut vowel was *a (*RkamH).
rgu has an r- reminiscent of the *R- of the
pre-Tangut form, though I am not certain -gu is cognate to
pre-Tangut *-kVmH.
The swa in both rGyalrong forms is cognate to Tangut 𘘄 0169 1shwi3 'tooth'. Tangut -i is from pre-Tangut *a. Did pre-Tangut *s- palatalize before *i: *swa > *swi > shwi? That can't account for cases of s which did not palatalize before i: e.g.,
𗱂𗳎𗪏𗋃𗚌𗞉𗝦𗝠𗜫
are all read 1si4, not 1shi3. (Initial s- is
associated with Grade IV and initial sh- with Grade III, so 1si3
and 1shi4 do not exist.)
The sequence of the s-k-roots for teeth in both rGyalrong
forms is identical in the Tangut collocation 𘘄𘟗 1shwi3 2korn1 'teeth' in Timely
Pearl 183.
Although I don't think there was a 'Proto-Tibeto-Burman' branch of
Sino-Tibetan, I still find STEDT's proposed cognate sets useful.
20.7.5.23:59: WHITE RAT 5.15
? qulugh ai tau sair par tau nyair
'white rat year, five month, ten five day'
I've long assumed that the dav·ḥ /daʍ/ (dav·ṃḥ /ðaʍ/
with initial lenition) of Pyu
tar· dav·ḥ ~ tar· dav·ṃḥ ~ tdav·ṃḥ ~ tdaṃḥ¹ 'king'
might be cognate to Old Chinese 主 *CItoʔ 'master'. dav·ḥ
can occur without tar·: e.g., yaṁ dav·ḥ 'this ?' (12.3).
Today it occurred to me that if dav·ḥ in Pyu 'king' is a noun like 'master', then tar· dav·ḥ 'king' is a noun-noun compound '?-lord', and tar· in other contexts might be that mystery noun '?'.
7.7.0:31: Some examples of tar· without a following dav·ḥ ~ dav·ṃḥ:
tar· hak· 'good ?' (27.3)
Pyu adjectives follow nouns.
hmiṁ tar· miḥ '? ? ?' (19.1. 30.1)
the longest collocation I can find, not counting instances of tar· before ḅin·ṁḥ + verb
yaṁ dav·ḥ tar· 'this master? [and] ?'
¹7.6.12:56: In theory, a disyllabic form †ta daṃḥ could appear in texts in the abbreviated style (i.e., the script without subscripts), but so far the disyllabic form is only found in texts in the full style with subscripts.
20.4.26.23:52: WHITE RAT 4.4
? qulugh ai ? sair ? nyair
'white rat year, four month, four day'
Fourth month, fourth day, four topics - all from today for once. I hope to revisit my backlog later.
1. Let's play Spot the Hanja!
2. Sino-Korean homophones. The story involving the confusion of 防水 <PROTECT WATER> pangsu 'waterproof' and 放水 <RELEASE WATER> pangsu 'drain' has been disputed.
3. I haven't had furigana fun on this blog in a while. In 光文社 Kōbunsha's short-lived Japanese translation of the American comic book Fantastic Four, Dr. Doom is called 破滅博士 which looks like it should be read Hametsu Hakase 'Dr. Destruction' but has the furiganaドクター・ドゥーム Dokutā Dūmu.
That blog gives me the impression that Dr. Doom lives in a country called 幸福王国 which looks like it should be read Kōfuku ōkoku 'Happiness Kingdom' but has the furigana ラトベリア Ratoberia 'Latveria'. But without seeing a scan of the name in the comic, I can't be sure.
4. Today I learned about לוף <lwp> Luf 'Loof', an extinct kosher version of SPAM. Is Loof really derived from (meat)loaf as Wikipedia says? Although Loof is apparently not being produced anymore, the name might live on as a generic word for canned beef, as it is in this list of IDF terms. That list addresses something I've long wondered about: what is it like for an overseas volunteer to join the IDF and learn Hebrew? (4.27.1:24: This gives me a bit of an idea.)
4.27.0:51: Ghil'ad Zuckermann on Luf:
Meatloaf (pronounced in Israeli luf rather than lof) is what we were forced to eat in the army when there was no kitchen around…
20.3.4.23:59: WHITE RAT 2.11
? qulugh ai ? sair par ? nyair
'white rat year, two month, ten one day'
1. TANGUT ERA NAMES IV
The fourth Tangut era with a known Tangut-language name is
𘓺𗼕𘂀𗴴
0510 2342 5243 0140 1ngwyr1 1lo3 2se4 2lher1 'heaven good.fortune people joy' (1090.2.3-1098.2.3) = 'heaven['s] good fortune [and] people['s] joy'
corresponding to Xia Chinese 天祐民安 *1then4 3u3 1min4 1an1 'heaven help people peace'.
'Heaven' and 'people' are shared by both the Chinese and Tangut names, but the rest doesn't match. Such mismatches are common in Chinese and Khitan-language era names for the Khitan Empire next door.
If 1ngwyr1 1lo3 2se4 2lher1 were the only known instance of 1lo3 and 2lher1, it would be reasonable to guess that they meant 'help' and 'peace' on the basis of the Chinese name, but other contexts that indicate otherwise have also survived.
2. I just started following James
(@jwa_khitan) on Twitter. Three threads:
2a. Khitanology 101.
2b. A new proposal on the origin of the Khitan large script:
I believe the Khitan large script may have its origins not in the Chinese clerical script, as the Liao histories say, but instead in the Chinese cursive and running scripts.
2c. What
is the "N4631" that I refer to from time to time?
3. KOREAN 철 CHHŎL: NATIVE OR SINO-KOREAN?
I thought two Korean words pronounced 철 chhŏl sound like
possible Chinese loans, and Martin et al. (1967: 1593) independently
entertained that possibility over a half century earlier.
3a. 철 chhŏl < earlier chhyŏl 'season' : cf. Sino-Korean 節 chŏl < chyŏl < *tser 'id.'
The trouble is the aspiration which is not in Sino-Korean or Chinese
itself. The word may be compressed from a unrelated disyllabic native
word like *hʌtser or *tsʌher.
3b. 철 chhŏl (no premodern attestations?) 'discretion': cf.
Sino-Korean 哲 chhŏl 'wise'
I can't see why this couldn't be from 哲.
I didn't initially understand why Martin et al. propose 節 'season' as an alternate possible Chinese source of Korean 'discretion'. 節 has many meanings in Chinese. Maybe 'restraint' is the relevant one.
4. What is the etymology of Qom (which has been in
the news because of COVID-19)? The Q- makes me think it's
not originally Persian.
5. Today I saw Manchu faššaha 'exerted' in Roth Li (2010:
87). There are
only a few Manchu roots with -šš-:
ašša- 'to move'
fašša- 'to exert'
gūwaššan 'thin strips of meat'
hoššo- 'to deceive, to entice, to mislead'
I wonder what the history of that rare geminate is.
6. I lived in the UK for four years but had never heard of "home education".
7. I initially thought Fatma- in Fatmawadi was from Fatima, but I dismissed the idea because I couldn't think of an Indonesian-internal reason to drop the -i-. But David Boxenhorn made me reconsider the idea. I now think Indonesian borrowed this disyllabic variant:
The colloquial Arabic pronunciation of the name in some dialects (e.g., Syrian and Egyptian) often omits the unstressed second syllable and renders it as Fatma when romanized.
Did that variant already exist in the speech of the
Arab traders who brought Islam to Nusantara?
8. Today I learned of tourmaline, whose English name apparently originates from Sinhalese. In Chinese, Japanese, and Korean it is the 電氣石 'electric stone', presumably
because it could attract and then repel hot ashes due to its pyroelectric properties.
The Vietnamese Wikipedia calls it tourmalin without the final -e of French and English tourmaline, perhaps to avoid it being pronounced. Why not Vietnamize it further as turmalin (to avoid un-Vietnamese ou) or even something like tunmalin (to avoid un-Vietnamese syllable-final -r)?
20.3.3.23:54: WHITE RAT 2.10
? qulugh ai ? sair par nyair
'white rat year, two month, ten day'
1. TANGUT ERA NAMES III
The third Tangut era with a known Tangut-language name is
𘓺𗪚𗅲𗧯
0510 2865 1910 2135 1ngwyr1 1du2 2tenq4 1e'4 'heaven peace ceremony hold' (1085.12.20-1086.9.10)
corresponding to Xia Chinese 天安禮定 *1then4 1an1 2li4 3ten4 'heavenly peace [and] ceremonial settlement'.
1ngwyr1 1du2 could either be a noun compound 'peace of heaven' or a noun-adjective phrase 'peaceful heaven'.
2tenq4 1e'4 is an object-verb phrase 'holding ceremony'. 1e'4
is not an exact equivalent of Chinese 定 'settle, become/make fixed',
but it is close if one thinks of 'holding' as 'holding in place'.
(3.19.18:42: 1e'4 is not 'hold' in the sense of 'hold a
ceremony'.)
2. Rubi in Japanese are almost always hiragana appended to kanji,
but there are rare creative exceptions:
2a. Page 70 of volume III of 永野護 Nagano Mamoru's
The
Five Star Stories has フォーチュン fōchun 'fortune' as rubi
for 希望 kibō 'hope'. The official English translation simply has
"hope". fōchun
may not merely be 'fortune'; it may also be a reference to the green
planet Fortune scheduled to appear over four thousand years later (the
story is epic in scale).
2b. Page 82 of volume III of
The
Five Star Stories has 同調機 <SAME TONE MACHINE> dōchōki
(a neologism?) as rubi for シーケンサー shīkensā
'sequencer'. The official English translation simply has "sequencer". I
assume a sequencer is some sort of gadget in the giant robots in the
series. (None of these
real-life shīkensā seem to be relevant.)
2c. Page 147 of volume III of The Five Star Stories has シックス shikkusu 'sixth' as rubi for VI世 rokusei 'the sixth' (in names of royalty) in the name コーラスVI世 Kōrasu Shikkusu. I expected the official English translation to have "Colus VI" or "Colus the Sixth", but it has "the sixth heir to the throne of the Colus dynasty". The color page introducing the character in the English edition has "Colus VI".
3-5 are finds from last night:
3. Jesse P. Gates' 2020
documentation of "Ghost's bride", a text in Stau,
possibly one of the closer living relatives of Tangut.
20.3.19.23:03: The very first Stau word in the story, ʁnæ 'long ago' has a potential Tangut cognate 𗂥 1926 2ne4 < *CInejH or *CInaŋH 'in past times'. Could pre-Tangut *C- have been a uvular like Stau ʁ-? The front vowel of Stau ʁnæ makes me think pre-Tangut *CInejH with a front vowel is more likely than *CInaŋH with a nonfront vowel, but on the other hand, pre-Tangut *CInaŋH is closer to Old Chinese 曩 *naŋʔ 'in past times'. Stau as recorded by Gates does not have either -ŋ or -j (and the three codas I found in his text are low in frequency: -n, -r, -v). The history of Stau has yet to be worked out as far as I know, so I don't know whether ʁnæ had a coda, much less which coda it might have had.
4. Andreas and Yadi Hölzl's "A
wedding ceremony of the Kyakala in China: Language and ritual"
(2019) is about "the only extant text" of a "seemingly extinct"
Jurchenic language preserving features lost in Manchu: unpalatalized
dental stops and [p] in the perfective converb. (Ming Jurchen
hadunpalatalized dental stops but had shifted Jin Jurchen p to f,
so its perfective converb was presumably *-fi as in Manchu.
Unfortunately, little of Ming Jurchen verbal morphology has been
documented.)
I can't get over how Kyakala survived into the last century and then
presumably disappeared. How many other languages recently vanished in
China without a trace?
5. Also by Andreas and Yadi Hölzl: "The endangered languages of the Manchus" (2019). Note that "languages" is plural! The big surprise for me was the Lu language of the Manchus of ... Guizhou!? Does Lu still exist?
6. I was oblivious to the French name of アフランシ・シャア Afuranshi Shaa in
富野由悠季 Tomino
Yoshiyuki's serial novel ガイア・ギア Gaia Gia (Gaia Gear)
(1987-1991) until last night. アフランシ Afuranshi is from French affranchi
'freed' (masc. sg. past participle of affranchir).
7. 富野由悠季 Tomino Yoshiyuki's name is a built-in option in Windows 10's IME. Typing in Japanese is so tedious that anything that saves me the effort of typing a two or three kanji (in this case由悠季) helps.
8. I've thought of Manchu -ha/-he/-ho as a perfective
suffix, but it also turns up in bihe with bi 'be'.
Russian быть byt' 'be' is imperfective and has no perfective
counterpart: i.e., no equivalent of bihe (if bihe is
perfective). Maybe Russian is shackling my imagination, but I can't
imagine how Manchu bi 'be' could be perfective. Being isn't an
action and can't be completed.
9. Results of the tenth 創作漢字コンテスト 'kanji creation contest' (via Bitxəšï-史).





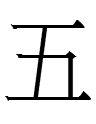








{kind=link}
{kind=link}