11.7.9.23:59: KHITAN SMALL SCRIPT 4: ONE DOUBTFUL DOT
In Kane 2009, the Khitan small script (KSS) character for 'north' (or 'above') consistently appears as 一̣ which looks like Chinese (and Khitan large script!) 一 'one' with a subscript dot tinier than a normally sized dot (丶) in Chinese and Khitan writing. I didn't notice this dot until last night when I was writing part 3. I revised part 1 to include the dot. But this afternoon I noticed that this KSS character (001 in Kane* and Starikov's numbering systems) appears without a dot in Starikov's Материалы по дешифровке киданьского письма (1970: 34). Starikov wrote on p. 54 that 001 is identical in form to the Chinese character 一 'one', confirming that it has no dot. I have revised parts 1 and 3 in accordance with Starikov.
At one point I considered regarding the noncharacter 一̣ as an graph
with a horizontal line symbolizing something above (i.e., north
of) something else (the dot). But since there is no dot, I wondered if
the horizontal line is an abbreviation of the Khitan large script
character ![]() for 'north'. However, I know of no other cases of small
script characters derived from the slightly older large script.
for 'north'. However, I know of no other cases of small
script characters derived from the slightly older large script.
If 001 truly had a dot, the dot would have to disappear in the combination ('polygram' in Starikov's terminology) 009
which Kane regarded as a "contraction of ![]() 2.001 'above,
upper' and the plural ending
2.001 'above,
upper' and the plural ending ![]() <d>, so 'the upper ones, the
superiors'." (2- indicates a KSS character. "[C]ontraction" may imply
the deletion of the dot, but I think Kane is referring to the lack of
space between 001 and <d>.) Kane also translated it as 'first
wife, senior wife', 'ancestors' ("i.e., 'those above' or 'those who
have gone before'"), and 'northern administration, the administration
in the upper region'. Note that even though <d> is a plural
ending, some of these translations are singular. Perhaps 'first wife'
and 'administration' are grammatical plurals like Sanskrit daaraas
'wife' (a masculine plural!) or they contain a <d> suffix
distinct from the plural suffix <d>.
<d>, so 'the upper ones, the
superiors'." (2- indicates a KSS character. "[C]ontraction" may imply
the deletion of the dot, but I think Kane is referring to the lack of
space between 001 and <d>.) Kane also translated it as 'first
wife, senior wife', 'ancestors' ("i.e., 'those above' or 'those who
have gone before'"), and 'northern administration, the administration
in the upper region'. Note that even though <d> is a plural
ending, some of these translations are singular. Perhaps 'first wife'
and 'administration' are grammatical plurals like Sanskrit daaraas
'wife' (a masculine plural!) or they contain a <d> suffix
distinct from the plural suffix <d>.
7.10.2:00: Toward the bottom of the second row from the left in the memorial tablet for the Khitan emperor Daozong is a three-element polygram with 001 'north' atop 254 <d> and 222 <ń>:
'of the upper ones'
Kane (2009: 135) identifies 222 ![]() in final
position as a genitive plural ending <iń>. (Does any 'Altaic'
language have final palatals?)
in final
position as a genitive plural ending <iń>. (Does any 'Altaic'
language have final palatals?)
222 may have been read as <ńi> in initial position: e.g., in
<ńi.qo> 'dog' (cf. Written Mongolian <noqai> - with the vowels seemingly reversed!)
According to Kane (2009: 61),
Other graphs [besides 222] may also have this characteristic [of initial CV- ~ final -VC readings], but the evidence at the moment is scanty.
7.10.3:57: Toward the bottom of the fifth column from the right of the Daozong memorial tablet graphic is the character sequence
hoŋ
di
'north, upper' (clearly written without a dot)
na
móde
hoŋdi is 'emperor' from Chinese 皇帝. Although disyllabic Khitan words are usually written within a single square in the KSS (e.g., móde later in the same line), hoŋ and di are written separately.
I have no idea what na and móde mean. The last word is fully visible in this image on the University of Tokyo website.
*7.10.1:10: Kane 2009's numbering system is based on that in Research on the Small Khitan Script (1985) apart from the addition of 379 and 380. Although 380 is the highest number in Kane 2009, Sun Bojun et al.'s (2010) "Preliminary Proposal for Encoding Khitan Characters in UCS" lists 69 more KSS characters such as
干王廿丨刂巾儿凡生伕쇼汁汷ㄅ厶
(which all look like Chinese radicals or characters except for 쇼 resembling a hangul letter combination; of course, hangul postdates Khitan and its combinatory principles may have been influenced by the Khitan small script)
and others I can't simulate in Unicode for a total of 449. (The encoding proposal only contains 448 KSS characters since it excludes Kane's 380, though it includes Kane's 379 as J-0096.)
What if a literate Chinese person asked a literate Khitan person for directions and got what looked like 一十 'one ten' for an answer? No Chinese unfamiliar with the Khitan script would guess that 一十 mean 'northwest', especially since the Chinese compound has the directions in the reverse order: 西北 'west-north'.
In part 1, I mentioned how 001 一 'north', the first Khitan small script (KSS) character in Andrew West's online version of Kane's 2009 list, looks like Chinese (and Khitan large script!) 一 'one'. Chn 北 'north' looks completely different, and it's unlikely that the creator(s) of KSS abbreviated it as 一. Is it possible that the unknown Khitan word for 'north' was pronounced like Chn 一 *iʔ 'one' or some other Chinese character containing a prominent horizontal line? None of the proposed readings (umar-a, ümere, umə, xoina, xoi, aru) based on Mongolian sound like *iʔ.
(7.9.00:33: The first syllable of ümere does sound like Chn 于 *ü whose first stroke is 一, but I'm grasping for straws. A single straw: 一. Horizontal strokes are so common in sinography that it's too easy to come up with a derivation like this.)
040 十 'west' may be derived from 001 一 'north'. (Or is the direction of derivation the other way around?) 040 十 looks like Khitan large script 十 'ten' and Chn 十 *ʃiʔ 'ten', which sounds like none of its proposed readings based on Mongolian: ör (Chingeltei), hörene (Toyoda 1992), uru (Ji Shi), xoru (Aisin Gioro 2004).
Kane (2009: 126) raised the possibility that 040 十 may mean 'south'. Note that 040 十 looks like the top of Chn 南 *nam 'south' which looks exactly like Khitan large script 南 'south' (see below).
(7.9.00:23: The discrepancy between 'west' and 'south' reminds me of how Japanese nishi 'west' corresponds to Okinawan nishi 'north' rather than Okinawan iri 'west'.)
294 小 'south; tribe' looks like Chn 小 'small'. Kane (2009: 70) suggested, "Perhaps one graph was used for two separate but homophonous words." Did both words sound like Chn 小 *siau or a sinograph containing a 小-like shape: e.g., 尚, 堂, etc.? It's even possible that 小 'south' and 小 'tribe' are abbreviations of different sinographs with 小-like shapes.
I do not know whether 294 小 represents the same word as
~
247-093 <te.gẻ> ~ 254-093 <de.gẻ>
interpreted by Ji Shi as 'down, under, lower, below' (Kane 2009's translations of Chn 下?) and Chingeltei as 'south'. (<gẻ> is a placeholder and is not intended to be an actual Khitan reading.) Kane (2009: 46) pointed out that "there are no words for 'south' like <de.gẻ> in other Altaic languages." <te ...> ~ <de ...> doesn't sound like the suggested Mongolian-based readings emüne (Toyoda 1992) and əmu (Aisin Gioro 2004) for 294 小.
072I do not know whether 072 represents the same word as 105-236
![]()
![]() <ud.ur>
'east', written with two KSS characters. Toyota 1992
proposed that 105 大 by itself was dorona 'east' and Ji Shi
proposed that 105-236 was doru. Neither reading fits the
phonetic values of 105 and 236 in
other contexts.
<ud.ur>
'east', written with two KSS characters. Toyota 1992
proposed that 105 大 by itself was dorona 'east' and Ji Shi
proposed that 105-236 was doru. Neither reading fits the
phonetic values of 105 and 236 in
other contexts.
Kane (2009: 43) lists 072 ![]() 'east' as an "allograph" of 101
'east' as an "allograph" of 101 ![]() deu
'younger brother'. Does this imply that 072 sounded like deu?
Ji Shi and Toyoda's do- is close to deu.
deu
'younger brother'. Does this imply that 072 sounded like deu?
Ji Shi and Toyoda's do- is close to deu.
The Khitan large script (KLS) characters for the four directions are either very similar or identical to their Chinese equivalents:
| |
Khitan small script | Khitan large script | Chinese |
| east | 東 | ||
| west | 西 | ||
| south | 南 | ||
| north | 北 |
KLS 216 'east' has an extra stroke, KLS 'north' has a single horizontal stroke instead of two strokes, KLS 'west' might have a hook added to the bottom of its penultimate stroke, and KLS 'south' looks the same to me.
KLS 171 北 looks exactly like Chinese 北 'north' but is a phonogram for śaŋ, a transcription of Chinese 尚.
11.7.7.23:59: KANE 2009'S LIST OF KHITAN SMALL CHARACTERS (PART 2)
Thanks to Andrew West for pointing out that Khitan 379 qudug 'happiness' may be a borrowing from Turkic*: cf. Hphags-pa Uyghur quthluq (and modern Uyghur قۇتلۇق qutluq - note the obligatory damma diacritics for u atop و). Its graph, however, is probably from a cursive form of Chinese 福 'good fortune' as Andrew and Kane (2009: 68) independently proposed. I initially suspected a connection as well last night but rejected it because I thought the bottom right parts of 379 (ホ) and 福 (田) didn't match, though the left sides did match. However, I have now seen cursive forms of 福 vaguely resembling 379 on p. 557 of the 1974 edition of 高塚竹堂 Takazuka Chikudou's 書体字典 Dictionary of Character Forms. Although 福 consists of a semantic component 礻 and a phonetic component 畐 in Chinese, it was borrowed as a whole into the Khitan Small Script (KSS).
A number of KSS characters (220-238) have a structure like 福. They look like Chinese
亻 'person' (semantic) + (semantic/phonetic)
combinations: e.g., 222 伏. Is their shared left-hand component 亻 significant? The readings and/or meanings of some of these graphs are unknown, but the remainder do not share any phonetic or semantic lowest common denominator that might be signified by . Hence I call the KSS element 亻 a 'mannequin' - something that looks like a 亻 'person' but isn't. Each KSS graph with a 亻 'mannequin' may have its own story independent of the others. Here are a few guesses:
222 伏 ɲ: derived from Chinese 犬 'dog', whose Khitan translation was ɲiqo, plus a 亻 'mannequin' (to tell the reader not to read it as 'dog'? - but adding it makes KSS 伏 look like Chinese 伏 *fu 'to bend over'!).
225 付 bi: sounds almost like Early Middle Chinese 付 *bü, but EMC was spoken centuries before the invention of Khitan writing in the 10th century, so the phonetic similarity may be coincidental.付 was pronounced *fu in the 10th century northern Chinese known to the Khitan.
226 ü: a simplification of Chinese 偉 *wi. Cf. Korean variation between [ü] ~ [wi] for 위.
233 仉 kú: derived from Chinese 仇 *khiu; also cf. its possible variant 178 几 ku, derived from Chinese 几 *ki (or an abbreviation of 233?).
*I think it's more likely that a Turkic -tl- was simplified to a Khitan -d- than the reverse.
11.7.6.23:59: KANE 2009'S LIST OF KHITAN SMALL CHARACTERS (PART 1)
is now online at Andrew West's site. No Khitan font is needed to see the 380 characters.
What is the Khitan Small Script (KSS), and why did the Khitan have a 'large' as well as a 'small' script?
The KSS superficially resembles Chinese: e.g., 001 (first in the list) 'north' looks like Chn 一 'one'. However, as that example indicates, one cannot assume a KSS character has the same meaning as the Chinese character it resembles.
Some characters are more complex than their Chinese translation equivalents, and vice versa: e.g.,'one': 026 乇 (3 strokes; nonmasculine*) vs. Chn 一 (1 stroke)
'west': 040 十 (2 strokes) vs. Chn 西 (6 strokes)
A few have no single Chinese character equivalent: e.g.,
155 乙 'fifty'
266 乂 'sixty'
300 冂 'eighty'
('Seventy' and 'ninety' are unknown, but I bet they were also written with single KSS characters.)
Moreover, most KSS characters have no meanings. They are phonetic symbols whose origins are often obscure**: e.g., 019 丙 represents the diphthong iu even though its Chinese lookalike 丙 and its derivatives (炳柄邴 ...) were pronounced *piŋ, not *iu. Other examples of KSS phonograms that don't sound like their Chinese lookalikes:
105 大 ud : Chn 大 *ta106 太 uŋ : Chn 太 *thai
169 欠 qó : Chn 欠 *khiam
171 久 da : Chn 久 *kiu
175 各 êŋ : Chn 各 *koʔ
There are KSS characters with no known phonetic or semantic value: e.g., 024 而. Kane has given them pseudophonetic values with question mark-like diacritics to indicate that they are not true readings: e.g., 024 is called ẻr because it resembles Mandarin 而 er 'and' even though it probably
- sounded nothing like Md 而 er
- had a meaning unrelated to Md 而 'and'
Most KSS characters have low stroke counts relative to Chinese, but 379 qudug 'happiness' has ten strokes. Why is it so complex? Its left side resembles 335 ia and its right side resembles 277. Could 379 be a two-syllable sequence 335 qu (another reading of ia?) + 277 dug? There is no known KSS character for dug, but there is a character 246 qu (resembling the bottom of 277!). If 335 had a second reading qu, when would qu be written as 246 and when it would be written as 335?
Next: Mannequins.
*7.7.1:22: 026 乇 'one' also has a dotted counterpart 027. Wu Yingzhe 2005 proposed that the dot indicates grammatical gender (i.e., masculinity). This use of dots has no parallel in Chinese writing.
**7.7.2:17: In some cases, KSS phonetic symbols might be derived from Chinese characters: e.g.,
021 mó < Chn 貊 or 陌 *moʔ? (Probable source of Md mo; other evidence indicates a now-extinct reading *maiʔ.)
149 子 ju, 150 ja, 152 ji, 153 ji < Chn 子 *tsz
Khitan j may have been unaspirated [tʃ] which is close to Chn unaspiratred *ts. KSS characters for alveolar affricates were only used to write Chinese words, implying that Khitan had no native *ts or *dz.
But what are the right-hand elements of 150, 152, and 153?
178 几 ku and/or 334 g < Chn 几 *ki (but vowels don't match!)
These two KSS logograms may have Chinese origins:
328 hoŋ (1st half of hoŋdi 'emperor' < Chn 皇帝) < Chn 皇 'emperor' (minus 日 and with the top dot fused to the vertical stroke of 王), 主 'master' (with a fused top dot), 王 'king' (with an elongated vertical stroke)?
037 di (2nd half of hoŋdi 'emperor' < Chn 皇帝) < Chn 主 'master' (with the top dot fused to the vertical stroke of 王 beneath an added horizontal line?), 王 'king' (with an elongated vertical stroke beneath an added horizontal line?), or a modification of 帝 influenced by 王/主/皇?
11.7.5.23:59: I WISH I NU
why the Tangut syllables that Gong Hwang-cherng reconstructed as 1nu (= my 1nəu)
are in two different homophone groups in both Tangraphic Sea (which Andrew West is slowly putting online) and Homophones:
Tangraphic Sea, Rhyme 1
Homophone Group 6
=
+
Fanqie: 1nəu = LFW3226 1niəə + 1tsəuHomophone Group 7
=
+
Fanqie: 1nəu = LFW4027 1niəə + 1təuHomophones, Chapter III
Note that the first tangraph is not in Tangraphic Sea.
Homophone Group 146
The fanqie have mysteries of their own.
First, the initial spellers
LFW3226 and 4027
are listed as having the same initial fanqie speller in Tangraphic Sea:
LFW0616
so they should represent the same initial (n-).
Second, the final spellers
LFW0415 and 2247
are part of a Tangraphic Sea fanqie chain leading back to the same final speller 4845
0415 < 3031 + 3909; 3909 < 1506 + 4845
2247 < 5300 + 4845
so they should represent the same final. They even belong to the same Tangraphic Sea rhyme (1.32).
Yet spellers representing the same initial and the same final can add up to two different syllables. How is that possible?
*7.6.00:32: Li Fanwen's (1986) annotated Homophones numbers homophone groups. The first three 1nəu tangraphs are at the end of a group of six tangraphs between groups 144 and 146. I could call this group 145, but I'd rather split it into 145a and 145b because it clearly contains two groups:
145a: 1niõõ (Tangraphic Sea rhyme 1.57)
145b: 1nəu (Tangraphic Sea rhyme 1.1)
I suspect the circle that was supposed to divide these two groups was omitted by accident.
7.6.00:42: Then again, it's also possible that 145a-145b were a single homophone group in the Homophones dialect but not the Tangraphic Sea dialect.
11.7.4.21:45: КАПІТАН АМЕРИКА
is not the Ukrainian title of Captain America: The First Avenger. In Ukraine, the movie is simply Перший месник Pershyj mesnyk 'First Avenger'. The New York Times explains:
In the end, the studios decided that Captain America would keep his name in all but three countries: Russia, Ukraine and South Korea.
Why the change in those places? Spokeswomen for Marvel and Paramount declined to comment. But people with knowledge of the decision, speaking on the condition of anonymity to avoid a conflict with the studios, cited reasons of culture and politics in addition to brand awareness.
The cold war kept the comic book version of Captain America from putting down roots in Russia and Ukraine as he did elsewhere in the world, these people said. But anti-American sentiment was also a factor.
The studios ultimately decided too much ticket revenue was on the table in Russia and Ukraine, both fast-growing movie markets, to take a risk over the title.
Let's look at the title that wasn't used: Капітан Америка Kapitan Ameryka. It contains both of the i-type vowels of Ukrainian:
і [i] (equivalent to Russian и [i] despite the different Cyrillic letter which was also once used in Russian)
и [ɪ] (not [i] as in Russian; transliterated as y, but not like Russian ы [ɨ] y; is Ukrainian the only Slavic language with [ɪ]?)
Vasmer derived Russian kapitan from Italian capitano. I presume the Ukrainian word has the same origin (but with Russian as an intermediary?).
The correspondence
inItalian i : Ukrainian i
is straightforward. But what about the correspondenceIt capitano : Uk kapitan
other languages' i : Ukrainian y
in
other languages' America ~ Amerika : Uk Ameryka
Could the y [ɪ] reflect the [ɪ] in the English pronunciation of America? I don't think so, because English [ɪ] also corresponds to Uk i after r: e.g.,
Eng Chris Evans : Uk Kris Evans (not Krys) (name of the actor playing Captain America)
Eng Arizona : Uk Arizona (not Aryzona)
Eng Eric Clapton : Uk Erik Klepton (not Eryk)
Eng Marilyn Monroe : Uk Merilin Monro (not Merylyn)
Eng Meryl Streep : Uk Meril Strip (not Meryl)
(Spellings found in the Ukrainian Wikipedia.)
English [ɪ] was borrowed as Uk i even when it was spelled as y in Marilyn and Meryl.
Why is Ameryka an exception to this pattern? Is it a spelling pronunciation of Russian Америка Amerika which looks like it should be pronounced Ameryka in Ukrainian? Or are Kris, Arizona, and Erik spelling pronunciations based on English whereas Ameryka was borrowed by ear?
Ukrainian and English [ɪ] are not identical. The latter is backer than the former.* Ukrainian [Do Ukrainian native speakers equate English [ɪ] with their [ɪ], or do they think English [ɪ] is more like their [i]?
The Ukrainian vowel system is asymmetrical:
| i | u |
| y [ɪ] | (no [ʊ]!) |
| e | o |
| (no ě [æ]!; see below) | a |
How many other languages have such a six-vowel system? Or an [ɪ] without a corresponding [ʊ]?
Manchu may have had [ʊ] without a corresponding [ɪ].
*Shevelov (1993: 949) described Ukrainian и y [ɪ] as "central front", contrasting it with "central back" Russian ы y [ɨ]. Ukrainian y is a merger of earlier *i and *y combining characteristics of both its sources: it is backer than *i but fronter than the old central or back *y.
Ukrainian i is from low (!) front *ě (a.k.a. jat) and back rounded (!!) *o followed by a jer.I wrote about the unusual shift of *o to i in March.
I don't know how *ě rose to i without merging with e. Perhaps *ě
- broke to *[jæ]
- raised its second component: *[jæ] > *[jɛ] > *[je] > *[jɪ] > *[ji]
- simplified to [i]
11.7.3.23:48: YI ROMANIZATION 5: 無ꀕ WU WU
The first wu of the title is Mandarin 無 'there is no ...'
The second wu is the Unicode name of the Yi syllable iteration mark from part 3 of this series:
ꀕ
In his article on this mark, Andrew West wrote,
[T]he hypothetical syllable WU that the name of U+A015 [the Unicode codepoint for ꀕ] suggests is blank in the table [of possible standard Yi syllables].
Since w- in Yi romanization represents [ɣ], wu would be [ɣu].
When looking at gaps in tables of possible syllables (or consonants or vowels), I always ask myself, 'Is this gap accidental or meaningful?'Speakers of a language have no obligation to 'fill up' tables like those at the bottom of Andrew's page on Yi romanization. For example, the syllable ggi [gi] occurs with only three out of four tones:
ggit, ggi, ggix
There is no ggip with the p-tone. But I bet the Yi could pronounce ggip if they wanted to. I suspect that ggip is an accidental gap because similar syllables do exist in the table:
syllables with voiced obstruent initials: bbip [bi], ddip [di], etc.
syllables with velar stop initials: gip [ki], kip [khip]
If those syllables are possible, then ggip should be theoretically possible, even if its slot is currently empty.
However, the absence of groups of syllables is probably meaningful. The wu-gap is part of a whole set of gaps. The (historically) velar initials
hx- [h] (< *hŋ-), ng- [ŋ], h- [x], w- [ɣ]
never occur with the vowels
-u, -ur, -y, -yr
Moreover, the other velars
g- [k], k- [kh], gg- [g], mg- [ŋg]
also can't occur with -y and -yr.
I conclude that there is a general constraint against syllables of the type Ky(r). If any such syllables ever existed, they might have become Zy(r)-syllables: e.g.,
*gy [kz] > zy [tsz]
*ky [khz] > cy [tshz]
*ggy [gz] > zzy [dzz]
*mgy [ŋgz] > nzy [ndzz]
*hŋy [hŋz] > *hxy [hz] > sy [sz]?
*ngy [ŋz] > nzy [ndzz]?
*xy [xz] > sy [sz]
*wy [ɣz] > ssy [zz]
If some Yi Zy(r)-syllables correspond to K-syllables in other Sino-Tibetan languages, I may be on the right track.
I suspect that earlier *Hu(r)-syllables have developed labial initials*:
*hŋu(r) > hmu(r)
*ŋu(r) > mu(r)
*xu(r) > fu(r)
*ɣu(r) > vu(r)
Do any Yi labial -u(r)-syllables correspond to K-syllables in other Sino-Tibetan languages?
*In Cantonese, *xu has become fu (e.g., 虎 'tiger') and syllabic ŋ is shifting to syllabic m (e.g., 五 'five').









{kind=link}
{kind=link}
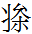{kind=link}
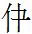{kind=link}
{kind=link}
{kind=link}
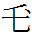{kind=link}
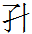{kind=link}
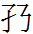{kind=link}
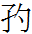{kind=link}
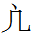{kind=link}
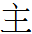{kind=link}
{kind=link}