
2lhiẹ < *?se-laH 'moon'
(cf. gDong-brgyad rGyalrong sla 'moon', Written Tibetan zla-ba 'moon', Written Burmese la 'moon')
11.7.2.23:57: YI ROMANIZATION 5: R
In part 3 of this series, I wrote,Yi syllables cannot end in consonants even if they are written with consonants.
I listed four pseudoconsonants in part 3: the tonal letters -t, -x, -p and the doubling marker -w. I left out a fifth pseudoconsonant of a third type: the vowel quality indicator -r.
In Tangut reconstructions such as Gong Hwang-cherng's, -r represents retroflexion of the preceding vowel. I write Tangut retroflexion as a superscript -ʳ to avoid confusion with a final consonant -r. All seven of Gong's basic Tangut vowels had retroflex counterparts:
However, only two Yi vowels may precede -r, and neither is retroflex: -yr and -ur. Descriptions of these vowels vary:uʳ eʳ iʳ aʳ əʳ ɨʳ oʳ (in Tangraphic Sea order*)
Andrew West: "retracted"
Wikipedia: ur is a raised bilabial trill [ʙ̝]; no IPA listed for -yr
Esling 2002 and Lama 2002: "tense"
The last interpretation brings to mind the tense vowels in several Tangut reconstructions. In such reconstructions, Tangut lax vowels have tense counterparts, and similarly according to Esling and Lama, the five Yi lax vowels have five tense counterparts (listed here in Yi romanization):
| Lax | -i | -y | -e | -o | -u |
| Tense | -ie | -yr | -a | -uo | -ur |
I have been using a subscript dot to indicate tenseness in Tangut. The table could be rewritten in Tangut-style notation as
| Lax | -i | -y | -e | -o | -u |
| Tense | -ị | -ỵ | -ẹ | -ọ | -ụ |
One might expect tense vowel syllables to have similar characteristics. However, Andrew's table of possible Yi syllables shows two different patterns of tonal distribution among tense vowel syllables:
| Lax/Tense | Vowel \ Tone | -t | -x | -Ø | -p |
| Lax | e | all possible | |||
| i | |||||
| o | |||||
| u | |||||
| y | |||||
| Tense | a | ||||
| ie | |||||
| uo | |||||
| ur | not possible | possible | not possible | ||
| yr | |||||
-ur and -yr can only occur with the unmarked or -x tones whereas all other vowels, lax or tense, can occur with all four tones. I don't think the absence of -urt, -urp, -yrt, -yrp is due to chance. My guess is that -ur and -yr have different, more restricted origins than the other tense vowels:
tense a, ie, uo < lax *e, *i, *o + R, Rt, Rp
tense ur, yr < lax *u, *y + R (but not Rt, Rp)
R is an unknown conditioning factor for tenseness. Rt and Rp combine that factor with the unknown sources of the -t and -p tones (presumably laryngeals: *-ʔ and *-h?). Perhaps
lax *o + Rt, Rp > uot, uop (rather than urt, urp)
lax *y + Rt, Rp > iet, iep (rather than yrt, yrp)
This hypothesis could be confirmed if there are word families with the patterns
Cuot ~ Cuop ~ Cur(x)
Ciet ~ Ciep ~ Cyr(x)
which could go back to *Cu + R(t/p) and *Cy + R(t/p). (Andrew calls -x a "secondary" tone, implying that it should not be reconstructed in pre-Yi.)
In modern Yi, a following tense syllable can be the 'R' factor triggering tenseness in a preceding syllable: e.g., Lama quotes Chen et al. (1985; respelled in Yi romanization):
This reminds me of my proposal for emphatic harmony in Old Chinese:hlep 'moon' (lax)** + pha 'half' (tense) = hlap (tense) + pha (tense) 'half moon'
emphatic + nonemphatic = emphatic + emphatic
埋 *mʌ-rə > *mʌ-rə > *mɛ > mai 'bury' (phonetic 里 *rəʔ)
nonemphatic + emphatic = nonemphatic + nonemphatic
膚 *pɯ-ra > *pɯ-ra > *puo > fu 'skin' (phonetic 盧 *ra)
*In Gong's reconstruction of the rhymes of the Tangraphic Sea, -ej/-ij rhymes (group VII: R34-40) are between -ə/ɨ rhymes (group VI: R28-33) and -əj/ɨj rhymes (group VIII: R41-43). However, the retroflex group VII rhymes -eʳj/-iʳj (R77-79) precede the retroflex group I -uʳ rhymes (R80-81). The reason for this unusual placement is unknown.
**7.3.00:15: The Tangut cognate of the Yi lax vowel word hlep 'moon' is
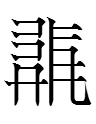
2lhiẹ < *?se-laH 'moon'
(cf. gDong-brgyad rGyalrong sla 'moon', Written Tibetan zla-ba 'moon', Written Burmese la 'moon')
with a tense vowel which may have been conditioned by a presyllable.
Pre-Tangut *a has a variety of reflexes which may have been conditioned by different presyllabic vowels: e.g.,*Ci-Ca > Ci (= Gong's Cji)
*Ce-Ca > Cie (= Gong's Cjij)
*Cɯ-Ca > Cɨə (= Gong's Cjɨ)
The above changes cannot account for all reflexes of *a. Perhaps there were several waves of *a-shifts with different outcomes from similar inputs: e.g., *Cɯ-Ca > Cie in one stratum but Cia in another.
11.7.2.3:27: YI ROMANIZATION 4: W²
A double post on a doubling mark is appropriate. (Here's the first.)
Thanks to Andrew West for leading me to his 12-page article on the modern Yi script's doubling mark
ꀕ
which resembles the w of Yi romanization atop two vertical strokes. If you can't view the character, install the free Nuosu SIL font. (ꆈꌠ/諾蘇 Nuosu is another name for the Yi. More on names for the Yi here.)
Strictly speaking, I should refer to Liangshan Yi since as Andrew explained,
The dialects of Yi vary considerably, and are not generally mutually intelligible. The Northern dialect, which is also known as the [凉山] Liangshan ("Cool Mountain") dialect because it is spoken throughout the region of the Greater and Lesser Liangshan Mountains, is the largest and linguistically most coherent of these dialects.
[...]
In order to improve literacy in Yi, in 1956 a scheme for representing the Liangshan dialect using the Latin alphabet that was introduced. Then in 1974 a standardized form of the traditional script used for writing the Liangshan Yi dialect was devised, and officially promulgated in 1980. [...] It is important to note that the standardized Liangshan Yi script is only suitable for writing the Liangshan Yi dialect, and is not intended as a unified script for writing all Yi dialects. Standardized versions of other Yi scripts do not yet exist.
I don't know anything about non-Liangshan Yi dialects, so the term Yi in these posts refers solely to modern standard Liangshan Yi. Andrew's article gives examples of traditional Yi script variation: e.g., one version of the doubling mark looks like 3=. You can see it and other variant doubling marks on p. 3 of his PDF. I wonder what the origins of those marks are.
The origin of the Japanese doubling mark 々 for Chinese characters is uncertain. The Japanese use of W as an abbreviation of Jpn daburu 'double' from English reminds me of Yi w, though the two symbols have independent origins.
I also don't know where the use of " as a ditto mark came from, though I did find this etymology of ditto:
The word ditto comes from the Tuscan language, where it is the past participle of the verb dire (to say), with the meaning of "said", as in the locution "the said story".That article introduced me to the abbreviation do. which I've never seen before:
In legal documents, the use of ditto marks, the abbreviation do. or the word “ditto” is often forbidden by law or regulations.
Is this because such usage may be ambiguous?
Perhaps " represents 'twice' in the same way that 二 'two' does. 二 'two' has functioned as a doubling mark in China.
Why does Chinese 二 have what appears to be a second codepoint in Unicode?
The Tangut doubling mark resembling Z may be derived from Chinese 二 plus a ノ at the bottom right.
The Khmer doubling mark ៗ is called leek too 'number two'* and it just occurred to me that it may be derived from the Khmer digit ២ '2'. These characters are the sources of the Thai doubling mark ๆ may yamok (lit. 'stick twin'; < Skt yamaka 'twin') and the Thai digit ๒ 'two'.
In pre-1972 Indonesian and Malay orthography, the digit 2 was the doubling marker.
*Khmer too 'two' is from *doo, which like leek 'number' (< Skt/Pali lekha 'writing') must be of Indic origin (and hence cognate to English two), though it doesn't match any Sanskrit or Pali form of 'two'. The closest match is Pali du- 'two' in compounds with a short o, not a long oo. *doo looks like Hindi दो doo 'two' though Hindi didn't even exist when the word was borrowed. Could *doo be borrowed from some Middle Indo-Aryan language other than Pali?
11.6.30.23:23: YI ROMANIZATION 3: W
Although the Yi language has no [w], it is written with the letter w. Yi w has a double function - including a doubling function:
At the beginnings of syllables: w- = [ɣ]
even though w- = [w] in Mandarin, so Yi learners of Mandarin and vice versa must be careful
This sound could have been romanized as, say, gh-, but w- wasn't being used for any other consonant and is a simpler one-letter spelling.
At the ends of syllables: -w = a copy of the preceding syllable: e.g.,
vatw = [va va] 'OK?' (cf. nonrepeated vat 'OK' which is not a question)
cf. Mandarin 好不好 hao bu hao? 'Is it OK?' with hao 'good' doubled plus bu 'not'; Yi has no 'not'
In Unicode, the Yi character for w is inexplicably called 'Wu' despite the absence of [w] in Yi.
Yi syllables cannot end in consonants even if they are written with consonants. This is why the -t in vatw [va va] is silent. It is a tonal letter signifying the tone of the preceding vowel:
-t: high level tone
-x: mid rising or mid-high level tone
-p: low falling tone
no tonal letter: mid level tone
Hence Yi vat, vax, vap, va are all [va] with different tones. I don't know the reasoning behind the choice of -t, -x, -p. (Could they be the first letters of Yi words describing the tones: e.g., 'high', 'mid', and 'low'?*) I assume the unmarked mid level tone is the most common. I wonder how hard it is to switch from tonal spelling to an orthography with nontonal, consonantal -t, -x, -p: e.g., English vat really has a [t] at the end.
When -w is added to a syllable without a tonal letter, that syllable is pronounced with the -x tone, but the repeated syllable retains the original mid level tone:
mid level + -w = [mid rising + mid level]
This tone change avoids two mid level tone syllables in a row.
For more examples of -w, see this lesson on Andrew West's site.
*6.30.23:36: Perhaps -t, -x, -p were chosen partly because they are not possible final consonants in Mandarin. The only final consonants in Mandarin are -n and -ng. Choosing -n and -g as tonal letters would confuse Yi-speaking learners of Mandarin.
Yi drops final consonants in borrowings from Mandarin: e.g.,
Md Beijing [pejtɕiŋ] > Yi bip ji [pi tɕi]
Md Sichuan [sɿ tʂhwan]> Yi syp chuo [sɿ tʂhɔ]
Note that Yi -y is a vowel [ɿ] after a consonant and that Yi -uo is a single vowel [ɔ]. I think of [ɔ] as being halfway between a and o, so I would have spelled it as ao or oa, but I suspect uo might reflect a dialectal or earlier pronunciation [wɔ] parallel to [jɛ] for Yi ie.
11.6.29.23:36: YI ROMANIZATION 2: MG
Pinyin romanization was designed for standard Mandarin which hasunaspirated voiceless stops: [p t k]
aspirated voiceless stops: [ph th kh]
but no voiced stops: [b d g]. In Pinyin, the letters b d g which aren't needed for [b d g] represent unaspirated [p t k], freeing the letters p t k to represent aspirated [ph th kh].
The letters p t k b d g have the same functions in Yi romanization. However, Yi, unlike Mandarin, also has [b d g]. Since Yi b d g represent [p t k], those letters cannot be also used for [b d g] without causing confusion. Hence doubled bb dd gg represent Yi [b d g].
One might think that Yi ng stands for n [n] + g [k] but its phonetic value is actually a single consonant [ŋ], as in Mandarin Pinyin.
Can you guess what the Yi initial letter combination mg- stands for? Hint: there are no other m + consonant combinations in Yi spelling. The answer is on Andrew West's "Yi Phonetic Alphabet" page.
What does mg- stand for in Tagalog? The answer is in my post on Meroitic.
11.6.28.23:01: YI ROMANIZATION 1: HX
Although I often link to Andrew West's work on Tangut, he also has written web pages on the language of the 彝 Yi people of China. The Yi have their own script whose current standardized form consists of 1,164 glyphs - one for each syllable - and a repeat symbol that I'll blog about later. Michael Everson has posted a chart of Yi syllables and their glyphs. The romanization used in that chart is based on Pinyin for Mandarin: e.g., h represents IPA [x], not [h]. Mandarin has no [h] distinct from [x], but Yi does. Since h represents [x] in both Pinyin and Yi romanization, Yi [h] is romanized as hx.
hx not only has an unusual phonetic value but also has an unusual position in Andrew's table of Yi consonants. Why is hx in the voiceless nasal column with hm and hn if it's not a nasal? My guess is that hx was historically a nasal. Yi hxe [hɯ] 'fish' corresponds to Old Chinese 魚 *ŋa and Written Tibetan nya 'id' (and Taiwanese hi < *hŋa < *s-ŋa?).
The e : a : a correspondence is also in 'five':
I wonder if h is accompanied by nasalization like Thai h-. James Matisoff wrote,Yi nge [ŋɯ] : Old Chinese 五 *ŋaʔ : Written Tibetan lnga (and Tangut ŋwə)
To my knowledge, [Mary] Haas was the first to describe the allophonic nasalization that occurs in Siamese syllables with laryngeal initials (ʔ- and h-) and low vowels, especially -a, as in hâa [hâaN] 'five', ʔaw [ʔawN] 'take'.
Thai haa 'five' was borrowed from Old Chinese (cf. the *hŋa that may be the source of Taiwanese hi) so the nasality may be a remnant of its original initial. (However, no initial nasal can be reconstructed for Proto-Tai *ʔaw 'take'.) Matisoff wrote a paper on this phenomenon entitled "Rhinoglottophilia: the mysterious connection between nasality and glottality". I haven't read it yet, though I just discovered this 1987 response by Sprigg.
Far from East Asia, *-s- sometimes became *-h- which then became -ŋh- in Avestan: e.g.,
See Jackson (1892: 43) for details. This is the only instance of *h becoming nasal rather than the other way around as in Yi and Taiwanese and Chinese in general*. Are there other cases?Avestan vaŋhuš : Skt vasus 'good'
*A nasal-to-h shift explains many instances of a nasal phonetic in sinographs with back fricative initials: e.g., in Cantonese,
午 ŋ (< OC *ŋaʔ) is phonetic in 許 hɵy (< OC *hŋaʔ)
(Sound changes have obscured the relationship between Mandarin 午 wu and 許 xu [ɕy] < *xy.)
11.6.27.23:57: ANDREW WEST'S ONLINE TANGRAPHIC SEA: FILLING IN FORMULAS
Here are the answers to last night's questions. No knowledge of Tangut was needed - just sharp observation.
1. What do the second and fourth tangraphs (LFW 3936 and 2705) in the four-tangraph formula mean?
=
This formula can be simplified to
X=A
B
3936 indicates that tangraph X is made out of the left side of the preceding tangraph A.
2705 indicates that tangraph Y is made out of the right side of the preceding tangraph B.
If English words had such formulas, here's what the formula of an might look like:
an = at 3936 in 2705
i.e., an is made up of the left side of a(t) plus the right side of (i)n.
2. This formula doesn't have 2705 at the end because the third tangraph supplies more than its right side.
=
3. The fourth tangraph (LFW 1602) indicates that all of the preceding tangraph is used to make the tangraph on the extreme left. An English parallel:
ago = at 3936 + go 1602
i.e., ago is made up of the left side of a(t) plus all of go.
4. This formula has 3936 at the end to signify that the left side of the preceding tangraph is used to make the tangraph on the extreme left. 5258 in second position signifies that the left side and upper right side of the preceding tangraph is used to make the tangraph on the extreme left.
=
5. The second and fourth tangraphs (2750 and 0737) in this formula indicate that the top and bottom of their preceding tangraphs are used to make the tangraph on the extreme left.
=
6. The second tangraph (5555) in this formula indicates that the center of its preceding tangraph is used to make the tangraph on the extreme left.
7. The first two tangraphs doing in this formula are the sources of the parts of the left side of the the tangraph on the extreme left. This formula has three source tangraphs followed by 2705.
=
=
8. The missing LFW numbers in this formula are
i.e.,
=
1602
3936
11.6.26.23:26: ANDREW WEST'S ONLINE TANGRAPHIC SEA: QUESTIONS OF CONSTRUCTION
Each tangraph (Tangut character) entry in the Tangraphic Sea has a four-character formula describing how the character was (supposedly) constructed. You can see this formula in the "Construction" column of Andrew's online version of the Tangraphic Sea.(You'll need these fonts to view it.) Let's look at the first formula for the tangraph in row 5.131:
Many formulae contain the same second and fourth tangraphs (LFW* 3936 and 2705):
1. What do those two tangraphs mean? You can figure out the answers without knowing any Tangut at all.X=A
2. Why does this formula for the tangraph in row 5.143 lack the common fourth tangraph LFW 2705?
3. What does its fourth tangraph (LFW 1602) mean?
4. Why does the formula for the tangraph in row 5.132 has LFW 3936 at the end instead of second position? And what is the function of the tangraph (LFW 5258) in second position?
5. What are the functions of the second and fourth tangraphs (LFW 2750 and 0737) in the formula for the tangraph in row 6.171?
6. What is the function of the second tangraph (LFW 5555) in the formula for the tangraph in row 6.142?
7. What are the first two tangraphs doing in this formula?
8. Finally, can you supply the LFW numbers for the missing tangraphs in this formula?
Answers tomorrow.
*LFW stands for Li Fanwen, author of a 2008 Tangut-Chinese dictionary. LFW XXXX represents the four-digit code number for a tangraph in his dictionary. You can find the LFW numbers for tangraphs in Tangraphic Sea by consulting Andrew West's online index which requires a third font in addition to the two needed for the text.
















{kind=link}