

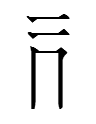
4689 'bright, glittering'
5014 'to go; fast, quick' (the name of R105 in Tangraphic Sea)
The final rhyme in the Tangraphic Sea (rhyme 105 / level tone rhyme 97) is one of the most mysterious.
There is no Tibetan transcription evidence for it.
Only a single Chinese transcription 月 exists for one or both of the R105 tangraphs
4689 'bright, glittering'
5014 'to go; fast, quick' (the name of R105 in Tangraphic Sea)
with a glottal initial (Sofronov 1968 II: 54).
4689 was used to transcribe 越 in the Tangut translation of the Forest of Categories (Gong 2002: 445).
The fanqie for 4689 and 5014 is
2298 1ʔwiəəʳ (meaning unknown) + 5099 'Sanskrit transcription tangraph' (rhyme 105/1.97) = 1ʔ- + R105
2298 could stand for some initial like zero, glottal stop, j-, or w-, all of which might fit the Chinese evidence (月 and 越). I think Gong's reconstruction of the Tangut period northwestern Chinese readings for those sinographs would be *jwa, which matches his R105 -jwa from Li Fanwen (1997: 3) and Gong (2003: 104). But Gong already reconstructed R19-20 as -jwa. How could R105 also be -jwa? (Let's not even go into how both R19 and R20 could be -jwa.)
Perhaps R105 -jwa is a typo for -jwar which is in the entries for R105 tangraphs in the body of both editions of Li Fanwen's dictionary. R105 follows the retroflex rhymes R77-103, so it would not be surprising if R105 was also retroflex (even though R104 was almost certainly not retroflex since it existed solely to transcribe Chinese rhymes, and Tangut period northwest Chinese did not have retroflex vowels).
However, Gong already reconstructed R87 as -jwar. Why weren't
4689 and 5014 1·jwar (Gong's mid dot = glottal stop; = my 1ʔwiaʳ)
treated as homophones of the rhyme 87/1.82 tangraph
5470 1·jwar (= my 1ʔwiaʳ) 'to be tired, work hard'
(Why does this tangraph contain pux 'surname' on the right?*)
in Tangraphic Sea or Homophones? Odder still, 4689 and 5014 comprise a homophone group in Tangraphic Sea, but are distinct from each other as well as from 5470 in Homophones, which classified all three as having unique readings.
The Tangut rhyme tables known in Chinese as 五音切韻 Dissected Rhymes of the Five Sounds cannot help us since the tables for R103-105 are absent. Nishida (1983: 173-174) spectulated that they may have never existed, but reconstructed a table with only two different syllables for R105:
4689 and 5014 ʔuạ (?)̣

5099 šuạ (?)
Nishida's tentative tense -uạ is quite close to Arakawa's (1999) lax -ua and Li Fanwen's (1986: 189) -ǐuạ.
According to Nishida (1983: 174), 5099 transcribed Sanskrit śvā with a long vowel. This is surprising if long vowels and tenseness cannot coexist as in Gong's reconstruction. Moreover, Sanskrit had no tense vowels, so why not transcribe Sanskrit śvā with a tangraph for šwa? Nishida (1964: 124-127) did not reconstruct such a syllable, but if šwa existed, it would belong to R18. Unfortunately, Nishida gives no context for the transcription of Skt śvā.
Could śvā be a typo for śva (though I'd expect a macron to be accidentally omitted rather than added)? Li Fanwen (2008: 806) listed one example of 5099 for Skt śva in what might be a transcription of dhaneśvarāya 'to the treasure lord'.
Next: Does the treasure lord hold the key to rhyme 105?
*5470 'to be tired, work hard' looks like it should be a surname because it contains pux 'surname', but it isn't:
=
+
5470 1ʔwiaʳ 'to be tired, work hard' (pekpux) =
4675 2rieʳ 'toil' (pek; semantic) +
4464 1lɨə̣ 'discourse' (puxpik)
What does 'discourse' have to do with being tired? 'Discourse' has a circular analysis that provides a clue:
=
+
4464 1lɨə̣ 'discourse' (puxpik) =
4444 1lɨə̣ 'and' (puxdex; phonetic) =
5592 1kaaʳ 'balance' (pikbaehii; semantic? Something desired in discourse? The Mojikyo font's version of this tangraph isn't very balanced!)
4444 1lɨə̣ 'and' (puxdex) =
4464 1lɨə̣ 'discourse' (puxpik; phonetic) =
4465 1lɨə̣ 'toil; hard labor' (puxtas; dex is part of tas; phonetic)
4464 and 4465 have very similar shapes and identical readings. I suspect the correct analysis of 5470 is
5470 1ʔwiaʳ 'to be tired, work hard' (pekpux) =
4675 2rieʳ 'toil' (pek; semantic) +
4465 1lɨə̣ 'toil; hard labor' (puxtas; phonetic)
10.7.16.22:12: UNGRADED TANGUT VOWEL DISTRIBUTION
Which vowels and vowel qualities don't go together in Tangut? The rhyme table below is in my simplified romanization with -' for 'length' (in Gong's and my reconstruction; it could have been some other distinction) and -q for tenseness:
| Plain | Tense | Retroflex | ||||||
| Basic | 'Long' | Nasal | 'Long' nasal | Basic | Nasal | Basic | 'Long' | Nasal |
| -u | -u' | (-un) | -uq | -ur | ||||
| -i | -i' | -in | -iq | -ir | -ir' | |||
| -a | -a' | -an | -aq | -ar | -ar' | |||
| -y | -y' | -yq | -yr | -yr' | ||||
| -e | -e' | -en | -eq | -eqn | -er | |||
| -ew | -ew' | -ewr | ||||||
| -iw | ||||||||
| -o | -o' | -on | -on' | -oq | -or | -or' | -orn | |
-un is only in recent Chinese loans. Earlier Chinese loans have -u' < *-uŋ. Perhaps some *-uN merged with *-oN.
Four rhymes stand out as suspicious loners: -iw, -on', -eqn, -orn. Are they mistakes or sole survivors of lost rhyme types that were once more fully populated? An earlier rhyme system may have looked like this:
| Plain | Tense | Retroflex | ||||||
| Basic | 'Long' | Nasal | 'Long' nasal | Basic | Nasal | Basic | 'Long' | Nasal |
| *-u | *-u' | *-un | *-un' | *-uq | *-uqn | *-ur | *-ur' | *-urn |
| *-i | *-i' | *-in | *-in' | *-iq | *-iqn | *-ir | *-ir' | *-irn |
| *-a | *-a' | *-an | *-an' | *-aq | *-aqn | *-ar | *-ar' | *-arn |
| *-y | *-y' | *-yn | *-yn' | *-yq | *-yqn | *-yr | *-yr' | *-yrn |
| *-e | *-e' | *-en | *-en' | *-eq | *-eqn | *-er | *-er' | *-ern |
| *-ew | *-ew' | *-ewq' | *-ewr | *-ewr' | ||||
| *-iw | *-iw' | *-iwq' | *-iwr | *-iwr' | ||||
| *-o | *-o' | *-on | *-on' | *-oq | *-oqn | *-or | *-or' | *-orn |
Other *-Vw-type rhymes may have also existed: e.g., *-aw, *-yw, etc.
I doubt there ever were any *-wn-type rhymes like Portuguese -ão because:
- Tangut -w is from *-k and *-w- I know of no languages with codas like *-kŋ, *-kn, *-km
- I know of no cases of Tangut -Vw corresponding to Chinese *-VwN
I have projected the absence of tense 'long' rhymes back into pre-Tangut, though perhaps internal reconstruction may imply their earlier existence. A 'long' ~ tense alternation may go back to an earlier 'long' ~ 'long' tense alternation.
7.17.16:51: Here are similar gradeless tables for Gong and Arakawa's reconstructions:
Gong
| Plain | Tense | Retroflex | |||
| Basic | Long (3) | Nasal (5) | Basic | Long (8) | |
| -u | -u' | (-un) (6) | -uq | -ur | |
| -i | -i' | -in | -iq | -ir | -ir' |
| -a | -a' | -an | -aq | -ar | -ar' |
| -y (1) | -y' | -yq | -yr | -yr' | |
| -ij | -ij' | -ijq | -ijr | ||
| -yj | (4) | -yjq | (4) | ||
| -iw (2) | -iw' | (7) | -iwr | ||
| -o | -o' | -oq | -or | -or' | |
| -ow | -ow' | (7) | -owr | ||
1. I rewrote Gong's ə/ɨ as y for ease of comparison.
2. -iw and -ow have similar distributional properties.
3. No scare quotes since Gong is more certain about their length than I am. I use the -' notation for ease of comparison with my reconstruction above and Arakawa's below.
5. The nasal vowels form a neat un-in-an triangle.
No unusual long, tense, or retroflex nasal vowels.
6. -un is only in Chinese loanwords.
7. Tense *-Vwq rhymes presumably merged with their plain *-Vw counterparts.
8. These may be four survivors of a much larger earlier rhyme class. *-ur', *-ijr', *-iwr', -owr' may have merged with their short counterparts. If there was no short *-yjr due to an accidental gap, there probably was no long *-yjr'.
Arakawa
Unlike Gong and I, Arakawa reconstructed Grades I and III in terms of a length distinction. Hence there is no length in the gradeless table below. Arakawa's Grade II has a -y- corresponding to Gong's -i- and my lowered vowels. Unlike Hashimoto and I, neither Arakawa nor Gong reconstructed a Grade IV.
I have two almost empty columns, but Arakawa has six whereas Gong has none:
| Plain | Tense | Retroflex | ||||||||
| Basic | -' | -" | Nasal | Basic | -2 | -'2 | Nasal | Basic | -2 | -' |
| -u | -u' | (-un) (5) | -uq | -ur | ||||||
| -i | -i' | -in | -iq | -ir | ||||||
| -a | -a' | -an | -aq | -ar | -ar' | |||||
| -y (1) | -y' | -yr | ||||||||
| -e | -e' | -en | -eq | -eq2 (6) | -eq'2 (7) | -enq | -er (8) | -er2 (9) | ||
| -eu (2) | -eu' | |||||||||
| -o | -o' | -o" (4) | -on | -oq | -onq | -or | ||||
| -ua (3) | ||||||||||
Notes:
1. I rewrote Arakawa's capital I as y for ease of comparison.
2. I could rewrite this as -ew for ease of comparison, but decided to keep it as a diphthong to show that Arakawa's system has only two types of diphthongs, -Vu and -uV.
3. This is Arakawa's reconstruction of the rare rhyme 105 which only occurs with the level tone in the readings of
4689 'bright, glittering'
5014 'to go; fast, quick'
5099 'Sanskrit transcription tangraph'
R105 was given as -jwa in the introduction to Li Fanwen (1997: 3) and Gong (2003: 104) but as -jwar in the main text of Li Fanwen (1997, 2008). The introduction of Li Fanwen (2008: 21) lists no reconstruction for rhymes 104 or 105.
I doubt that R105 could have been -jwa(r) since that would overlap with Gong's R19-20 -jwa and R87 -jwar. I have reconstructed it as -ya with a high front vowel but am reluctant to have a single rhyme with y.
Sanskrit did not have -ua, -jwa(r), or -ya, so either these reconstructions are wrong or 5099 represented a Sinified Sanskrit syllable (and in that case, a retroflex vowel is unlikely since Tangut period northwestern Chinese had no retroflex vowels). I'll look at 5099 more closely in my next post.
4. Is -o" supposed to be a typeable version of ö [ø]? It is equivalent to Gong's -ow' and my -on' (both in gradeless notation).
5. -un is only in Chinese loanwords.
6. I don't know how -eq2 differs from -eq. Does Arakawa's -2 consistently indicate the same unknown distinction? Arakawa's -eq(')2 rhymes (76-79) mostly correspond to Gong's and my retroflex rhymes (77-79) though all three agree that 76 was tense.
7. There is no -eq' without a 2 corresponding to -eq'2.
8. Arakawa's -er corresponds to my -ewr and Gong's -iwr. Arakawa's -eu has no retroflex counterpart.
9. Arakawa paired R101 -yer2 with R100 -yIr, which looks identical to his R83 -yIr. Could he have meant R100 to be yIr2 sharing -r2 with R101 -yer2? If he did, then my table should have an -yr2 (= gradeless notation for Arakawa's Grade II -yIr2).
Hashimoto
As far as I know, no one has ever used the 1965 reconstruction by the prominent Sinologist Mantaro J. Hashimoto, and Hashimoto never wrote about Tangut again. Nevertheless I thought it would be interesting to compare it with the other three. Like Arakawa, Hashimoto thought Tangut grades were correlated with length:
| Grade | Hashimoto | Arakawa |
| I | long | short |
| II | short | -y- + short |
| III | -j- + short | long |
| IV | -j- + long | (none) |
Hashimoto reconstructed a seven-vowel system with ä [æ] as a basic vowel, whereas it is the Grade II version of a in my reconstruction and is absent from Gong and Arakawa's reconstruction:
| Front | Central | Back | |
| High | i | u | |
| Mid | e | ə (= y below) | o |
| Low | ä | a |
He did not reconstruct tense or retroflex vowels. Instead, his system is rich in final glides and glide-nasal sequences. His system is extremely tidy. A simple constraint against high vowels combining with glides (= nonsyllabic high vowels) can account for all eight gaps.
| Basic | -j | -N | -jN | -w | -wN |
| -u | -uN | ||||
| -o | -oj(N) (2) | -oN | -oj(N) (2) | -ow | -owN |
| -e | -ej | -eN | -ejN | -ew | -ewN |
| -i (1) | -iN | ||||
| -ä | -äj | -äN | -äjN | -äw | -äwN |
| -a | -aj | -aN | -ajN | -aw | -awN |
| -y | -yj | -yN | -yjN | -yw | -ywN |
Notes
1. I have rewritten Hashimoto's ə as y for ease of comparison.
2. Hashimoto was not certain about the presence or absence of -N in his rhymes 97 and 98 (= rhymes 104 and 105 in most other reconstructions).
ConclusionAt a glance, Hashimoto's system is the neatest. It has no random gaps or mostly empty columns. Gong's is second neatest, folllowed by mine and Arakawa's.
However, neatness is not a sufficient criterion for judging reconstructions. Other criteria include:
- matching transcriptions of Tangut in other languages (Tibetan and Chinese)
- matching Tangut transcriptions of other languages (Sanskrit and Chinese)
- matching Tangut phonological alternations (see Gong's writings on this subject)
I have not yet fully tested Hashimoto's system, but I don't think it fits the other evidence. I'll provide concrete examples in my next post.
10.7.15.23:48: THE GOLDEN GUIDE: LINES 61-62: TANGRAPHS 301-310
61: All pure name tangraphs except for 294. Why recycle 'exchange' instead of creating a special tangraph for the first syllable of Lon-names? Was 'exchange' originally a modifier: 1lõ-X = 'the exchanged X clan'? What would 'exchange' mean in such a context?
| Tangraph number | 301 | 302 | 303 | 304 | 305 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2891 | 5454 | 2120 | 5885 | 3120 |
| My reconstructed pronunciation | 0dʒ-? | 2khɛw | 1ʃɨaʳ | 1lõ | 2tsi |
| Tangraph gloss | first half of the surname Jikhew | the surname Khew | the surname Shar | to exchange; first syllable of surnames | the surname Tsi |
| Word | the surname Jikhew | the surname Lontsi | |||
| Translation | Jikhew, Shar, Lontsi, | ||||
301: 2891 has the unflattering phonetic 'insect', an abbreviation of 3568:
+
2891 0dʒ-? 'first half of the surname Jikhew' (jiopux) =
3568 0dʒ-? 'a kind of insect' (jiopak; phonetic) +
2888 2mə 'surname' (dexpux; semantic)
Homophones indicates that 3568 and 2891 are homophones (37B28-37B31). Apart from that fact, nothing else can be said for certain about their readings. I don't know of any fanqie or transcriptive evidence.
Sofronov (1968 II: 403) did not reconstruct readings for either tangraph.
Others reconstructed an initial voiced affricate for reasons that are unclear to me. Presumably their choice is based on the fact that 3568 and 2891 are in the alveopalatal section of the Mixed Categories volume of the Tangraphic Sea which contains all dʒ-initial tangraphs for some unknown reason. However, a few tangraphs in that section contained voiceless initials, so tʃ- tʃh- ʃ- are also possible initials.
Li Fanwen (1986: 385) reconstructed both as 0dʑẽ, equivalent to my 0dʒie. But if it were 1dʒie or 2dʒie, why wasn't it in the 2dʒie ~ 1dʒie homophone group (39A61-39A67)?
Li Fanwen (2008: 577, 474) lists the readings of 3568 and 2891 as 0dzjẽ and 0dźe. Neither is possible in Gong's reconstruction to the best of my knowledge, so both may contain typos. Gong's system has no rhyme -jẽ and does not permit Gong's Grade II/III initial dź- before Gong's Grade I rhyme -e.
Kotaka's site has the reading 0ji in Arakawa's system which seems unusual since Arakawa usually has -yi or -i: after j-. The distribution of rhymes before alveopalatals in Arakawa's reconstruction is odd to me: why jyi and ji: rather than jyi and jyi: or ji and ji:?I tentatively follow Kotaka and romanize 3568 as Ji, leaving the exact rhyme unspecified in my reconstruction.
302: The left radical (pie) of 5454 is a phonetic for 2khɛw which is also in 5338 and 5385. Why isn't the 'surname' radical (pux) of 2888 on the right side?
303: 2120 has a circular analysis:
+
2120 1ʃɨaʳ 'the surname Shar' (dexbarhul) =
2888 2mə 'surname' (dexpux; semantic) +
2017 1ʃɨaʳ 'impressive and dignified manner' (barhul; phonetic)
=
2017 1ʃɨaʳ 'impressive and dignified manner' (barhul) =
2120 1ʃɨaʳ 'the surname Shar' (dexbarhul) -
2120 1ʃɨaʳ 'the surname Shar' (dexbarhul)
I presume 2017 predates 2120, not the other way around.
304: 5885 has part of 2888 'surname' in its analysis, suggesting that it was originally created as a surname tangraph and was recycled to represent a homophonous verb:
+
5885 1lõ 'to exchange; first syllable of surnames' (guxberdex) =
5914 2lọ 'two; second' (guxber; phonetic; gux is 'small' and ber is also in 'two' below)
2888 2mə 'surname' (dexpux; semantic)
305: The dex 'person' of 3120 may be from 2888 'surname', but the rest (circor; cir = 'water') is not found in any tangraph, implying that cir and cor are from two different sources.
62: Finally a surname that is semi-recognizable! Can you guess which one I'm referring to?
| Tangraph number | 306 | 307 | 308 | 309 | 310 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 0536 | 5761 | 3889 | 0493 | 3870 |
| My reconstructed pronunciation | 1phæ | 2lɨi | 2biee | 2siə | 1pi |
| Tangraph gloss | the surname Pha | second syllable of surnames | the surname Be; first syllable of surnames | the surname Sy | the second syllable of the surname Sypi; to close (loan from Chn 閉) |
| Word | the surname Phali | the surname Sypi | |||
| Translation | Phali, Be, Sypi. | ||||
306: 0536 (wuoces) has wuo 'bird', but its analysis does not reveal any obvious connection to birds. Were the Pha related to the Ghyr? Why create a surname tangraph from a verbal suffix?
+
0536 1phæ 'the surname Pha' (wuoces) =
2235 1ɣiəʳ 'the surname Ghyr' (dexwur; wur is the right-hand variant of wuo)
4601 2nia 'second person singular ending' (jiaces)
307: 5761 has yus, a radical associated with implements also in
1752 2kwạ 'hoe' (beeyus)
3661 2ko 'pick, pickaxe' (dexyus; why is dex 'person' on the left?)
5436 1dʒɨị 'sickle' (yuscin)
yus contains the 'metal' radical tex atop bil (function unknown).
What is the function of pax (possibly 'to cross'?).
Were the -li clans known for their skill with some implement?
7.16.3:48: The analysis of 5436 indicates that yus is indeed a composite radical:
=
+
5436 1dʒɨị 'sickle' (yuscin = texbilcin) =
4995 1ʃɨõ 'iron' (texbilbelbil; abbreviated as tex without bil in other tangraphs) +
2716 1rieʳ 'skillful' (gaedumcin)
308: 3889 (voadex) has voa, a phonetic for 2biee, and dex, probably an abbreviation of 2888 'surname'.
309: Li Fanwen (2008: 84) identified 0493-3870 as Sypi, the Tangut equivalent of 鮮卑 Xianbei < Old Chinese *serpe. (The mismatching vowels need an explanation.) The Tangut imperial family claimed descent from the Tabghach (拓跋 Tuoba), a clan of the Xianbei. However, the Tangut imperial surname was
2ŋwəi-1mi (see line 27)
not Sypi. Sypi reminds me of surnames like English, Irish, French, Deutsch, etc.
The right side of Sy (dex) is probably from 2888 'surname', but the function of the left side (ful) is unknown.
1597 2siə 'new' (fulherpak; cognate to Chn 新?)
has the left side of Sy as phonetic.
310: The analysis of 3870 is completely baffling:
3916 is as odd a choice as a source tangraph for a surname as 4601 'second person singular ending' above.
+
3870 1pi 'the second syllable of Sypi' (dolhul) =
3916 2si 'nominalizer; perfective suffix' (dolgoi) +
4027 1niəə 'two' (berhul)\
10.7.14.23:55: THE GOLDEN GUIDE: LINES 59-60: TANGRAPHS 291-300
59: This line and line-60, like 57-58, have the structure (disyllabic surname) + (monosyllabic surname) + (disyllabic surname).
| Tangraph number | 291 | 292 | 293 | 294 | 295 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 0874 | 4872 | 2389 | 5574 | 2837 |
| My reconstructed pronunciation | 1dẽ | 2lɨẽ | 2võ | 2vɨi | 1bəu |
| Tangraph gloss | the surname Den | the surname Len | the surname Von | the surname Vi | the surname Bu |
| Word | the surname Denlen | the surname Vibu | |||
| Translation | Denlen, Von, Vibu, | ||||
291: The nasality of the vowel of 0874 1dẽ is extremely dubious. I have only reconstructed it because Gong grouped that Grade I rhyme (41) with the Grade II rhyme 42 and the Grade III-IV rhyme 43 which are more likely to be nasal. Arakawa reconstructed these rhymes somewhat differently:
| Rhyme number | Gong's grade | Gong's reconstruction | My grade | My reconstruction | My simplified romanization | Arakawa's grade | Arakawa's reconstruction |
| 41 | I | -əj | I | -ẽ | -en | III | -e:' |
| 42 | II | -iəj | II | -ɛ̃ | I | -en | |
| 43 | III | -jɨj | III/IV | -ɨẽ, -iẽ | II | -yen |
Maybe I should romanize 0874 as De without nasalization. I can't delve into this problem any further now. I just want to express my doubts.
2834 1de in the analysis of 0874 suggests an -e-like vowel for 0874 and/or a relationship between the De and Den clans:
+
0874 1dẽ 'the surname Den' (hervea) =
0600 1dẽ 'a kind of grass' (herveagem; phonetic)
2834 1de 'the surname De' (gaiqem, not gaivea with one more stroke; phonetic?)
0600 with gem 'grass' on the right surely predates 0874 rather than the other way around.
The Tangraphic Sea definition for 0874 ends with
2phiu 1ɣɛ̣ 1niəə
'rising tone two'
I have no idea what that means. How many other definitions have such phrases? There are only two level tone 1dẽ: 0874 and 0600 (see above).
292: 4872 (dulbaacon) has no known analysis. Since dulbaa and baacon do not occur elsewhere, it may be a single unit or a combination of parts (dul, baa, con) from three different tangraphs.
Were the Denlen related to the Den and/or the Len, assuming the latter two were independent surnames?
I have been assuming that any tangraph with
1mɨəʳ 2mə
'tribal surname'
(Are these words related to each other and to 0856 2məʳ 'basic'?)
as clarifiers in Homophones could be an independent surname. I may be wrong. Perhaps surname components also had the same clarifiers.
293: Li Fanwen (2008: 394) included this analysis for 2389 from the combined Tangraphic Sea/Homophones. I assume the parentheses indicate a modern scholar's guess based on surviving fragments of a tangraph. Were the Von somehow related to the Tson?
)+
2389 2võ 'the surname Von' (baefaldex)
1476 2tsõ 'the surname Tson' (falbaefal; semantic?) +
2888 2mə 'surname' (dexpux; semantic)
294: What does 'tail' have to do with the Vi?
+
5574 2vɨi 'the surname Vi' (hanhie) =
5071 1vɨi 'to spend, dispatch, benefit from' (handao; phonetic)
5677 1miee 'tail, end' (haebaehie; semantic?)
295: is often an abbreviation of 1918 mi 'not', but it is a phonetic for 1bəu in 2837 and three other tangraphs (2362, 2366, 2371). I am surprised that 2888 is not abbreviated even though its distinctive right side would be sufficient to indicate a surname (cf. 5489 in line 55).
+
2837 1bəu 'the surname Bu' (ciadexpux) =
2366 1bəu (ciaqundex; phonetic) +
2888 2mə 'surname' (dexpux; semantic)
60:
| Tangraph number | 296 | 297 | 298 | 299 | 300 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3284 | 2637 | 3676 | 2127 | 0177 |
| My reconstructed pronunciation | 2lɨa | 1dəəu | 2ʃɨə | 1lhiə | 1raʳ |
| Tangraph gloss | transcription tangraph | slave | the surname Shy; first half of the surname Shyha | the surname Lhy | patriarchal clan; surname |
| Word | the surname Ladu | the surname Shy | the surname Lhyrar | ||
| Translation | Ladu, Shy, Lhyrar | ||||
296: None of the other tangraphs containing the right side (toa = bixdex) of 3284 (dextoa) sound like Lhy, so what nonphonetic function could toa serve?
The dex of 3284 is probably from
2888 2mə 'surname' (dexpux)
297: 2637 1dəəu 'slave' was borrowed from Tangut period northwestern Chinese 奴 *ndu 'slave' (without a long vowel). Were the Ladu descended from the slaves of a La clan? If not, why pick a negative tangraph for -du when other homophonous tangraphs were available: e.g.,
5149 1dəəu 'to store up'
'Woman' on the left of 2637 is reminiscent of 女 'woman' on the left of 奴 'slave', but what is the function of 2thie?
+
2637 1dəəu 'slave' (dexbasdeobae) =
3168 1miəə 'woman' (dexbixhascin; oddly no 'female' radical) +
3836 2thie 'transcription tangraph' (basdeobae)
298: Were the Shy related to the something-Li?
3676 2ʃɨə 'the surname Shy' (dexpax) =
2888 2mə 'surname' (dexpux) +
5761 2lɨi 'second syllable of some surnames' (yuspax)
299: The analysis of 2127 surprisingly doesn't contain 2888. Why extract dex 'person' from 'send' instead of 2888 'surname'? What is the function of bamgur = qau? Is it short for a name containing 2mʊ?
+
2127 1lhiə 'the surname Lhy' (dexbamgur) =
0559 1ʃwɨõ 'to send' (bokbaejio)
0310 2mʊ 'transcription tangraph' (qaugescok)
Compare the bottom right of bamgur and qau to the bottom right of woe and woa.
300: 0177 is a phonetic-semantic compound:
+
0177 1raʳ 'patriarchal clan; surname' (daidexdal) =
2474 1raʳ 'to flow' (dexdaidex; phonetic) +
2338 1ɣiəʳ 'surname' (geobambilcok; semantic)
7.15.2:33: 2338 doesn't even contain dal. cok has one less stroke. If 0177 really were derived from 2338, why add one stroke to cok, making cok look like dal?
 >
>
cok > dal
Neither radical has an obvious derivation. dal could be from one of 80 tangraphs and cok could be from one of 223 tangraphs.
dai
is a phonetic for raʳ (was it a randomly chosen shape or derived from a sinograph or khitanograph?) but the origins of dex and dal in 0177 are unknown.
0177 cannot be from dai plus 2064 1woʳ 'to stand up' (dexdal)
since 2064 has no phonetic or semantic resemblance to 0177.
10.7.13.22:26: THE GOLDEN GUIDE: LINES 57-58: TANGRAPHS 281-290
57: Although neither Kychanov (2006: 492) nor Li Fanwen (2008: 229) list 1369 'moon' as a monosyllabic surname, I assume it must be one here if this line is parallel in structure to 58. If not, then 283-285 are 'Vydzon of the Moon'.
| Tangraph number | 281 | 282 | 283 | 284 | 285 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3623 | 4031 | 1369 | 1989 | 5164 |
| My reconstructed pronunciation | 1ʔie | 2giuu | 2lhõʳ | 2vɨə | 1dzõ |
| Tangraph gloss | the surname Ye | lucky | moon; first syllable of surnames | the surname Vy | the surname Dzon |
| Word | the surname Yegu | the surname Vydzon | |||
| Translation | Yegu, Lhorn, Vydzon, | ||||
281: The surnames 3623 1ʔie 'Ye' and 5287 1vəi 'Vi' are derived from each other
3623 (dextem) <> 5287 (temdex)
and their dex are from
2888 2mə 'surname' (dexpux)
Were the Ye and Vi related clans? No other tangraphs have tem.
I romanize 3623 as Ye instead of E since
members of its homophone group (1139, 1245) were transcribed with Tibetan y- (Nishida 1964: 127, Tai 2008: 214)
a member of its homophone group (1101) transcribed Sanskrit ye (Nishida 1964: 127, Grinstead 1972: 184)
282: 4031 has a circular analysis. I don't understand what 'emperor' has to do with 'lucky'
+
4031 2giuu 'lucky' (giojei) =
0775 1giuu 'transcription tangraph' (bosgio; phonetic) +
2349 1ziə̣ 'emperor' (geojei; semantic?)
=
0775 1giuu 'transcription tangraph' (bosgio) =
1586 1ɣɛ̣ 'sound' (bostal; indicating transcription) +
4031 2giuu 'lucky' (giojei); phonetic
283: 1369 'moon' has no known analysis. It looks like 'light' (Grinstead 1972: 15) shared with
2814 2lhị 'moon' (cognate to 1369 2lhõʳ 'moon'?)
plus a vertical line plus what might be an abbreviation for 'sun' (see Andrew West's blog for more on this radical).
284: Were the Vy regarded as 'basic', and in what way?
+
1989 2vɨə 'the surname Vy' (cirbiijam) =
2590 2vɨə 'outside motion prefix' (cirbiijon; phonetic; why does this contain cir 'water'?) +
4017 1tʃɨi 'basic' (geijam; semantic?)
285: Were the Dzon an illustrious clan closely related to Lyby, the ancestor of the Black-Headed Tangut?
+
+
5164 1dzõ 'the surname Dzon' (yakdal) =
5031 1bə 'second half of Lyby, ancestor of the Black-Headed Tangut' (biobalbaeduucin) +
1332 1de 'to pass on' (jaljiu) +
2132 2ʔiew 'achievement' (dexgoldal)
58: Is the ordering and grouping of surnames significant: e.g., are the clans in each line related to each other?
| Tangraph number | 286 | 287 | 288 | 289 | 290 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3341 | 2439 | 1264 | 4737 | 3772 |
| My reconstructed pronunciation | 2khə | 1phəi | 2kiʳ | 2ma | 2ʃɨo |
| Tangraph gloss | the surname Khy | second half of the surname Khyphi | the surname Kir; two | to apply, daub | sweat |
| Word | the surname Khyphi | the surname Masho | |||
| Translation | Khypi, Kir, Masho. | ||||
286: The analysis of 3341 is unknown, but I think it's a semantic-phonetic compound:
3341 2khə 'the surname Khy' (dexbaxbeebel) =
2888 2mə 'surname' (dexpux) +
1335 2khə 'macaque' (baxbeebel; phonetic)
287: Were the Khe related to the Khyphi?
2439 has a circular analysis:
=
2439 1phəi '2nd half of the surname Khyphi' (diadeadex) =
3094 1khie 'the surname Khe' (diadea) +
2888 2mə 'surname' (dexpux)

3094 1khie 'the surname Khe' (diadea) =
2439 1phəi '2nd half of the surname Khyphi' (diadeadex) +
1046 1khie 'ashen' (hinbur, not hindea!)
3094 must predate 2439 despite its analysis.
Note that bur and dea are not identical. This may cast further doubt on the analysis, though the homophony of 3094 and 1046 makes me want to think bur/dea are a phonetic for 1khie. The only other khie tangraph with a similar radical is
=
4213 1khie 'a kind of tree' (boxdiadea) =
4250 1si 'wood' (boxdexdexcok; semantic)
3094 1khie 'the surname Khe' (diadea; phonetic)
Both bur and dea occur in right-hand position, so bur cannot be considered to be a right-hand variant of dea.
288: 1264 (no analysis available) clearly consists of a reduplication of the radical fai to presumably reflect its meaning 'pair'. What fai represents by itself is unknown.
289: 4737 (no analysis available) and 3772 could be a surname based on a phrase 'applied sweat' (!?). Why weren't new tangraphs created for these syllables? What determines whether a name gets new or recycled tangraphs?
290: 3772 is a semantic-phonetic compound:
+
3772 2ʃɨo 'sweat' (cirwoe) =
3529 2nɔ̣ 'fluid' (cirdexpel; semantic) +
5872 2ʃɨọ 'to cover' (woadex; phonetic)
woe is a right-hand variant of woa that is unique to 3772.
woa appears in only one other tangraph:
3777 demonstrates that the upward hook of woe is not obligatory in right-hand position.
=
+
3777 1piụ 'to love, adore' (jiiwoa)
2596 1piụ 'power, might' (jiidil; phonetic) +
5872 2ʃɨọ 'to cover' (woadex; semantic? smother with love?)
10.7.12.23:57: THE GOLDEN GUIDE: LINES 55-56: TANGRAPHS 271-280
55: I'm not sure whether 274 is a common or proper noun. Is 273-274 'Lon people' or is 274 a surname that happens to sound like the word for 'person' (or is derived from it; cf. the surname Mann)? The Tangraphic Sea (72.152) does not define it as a surname. Nor do Kychanov (2006: 452) and Li Fanwen (2008: 370).
There is a surname Person which isn't what it seems to be.
| Tangraph number | 271 | 272 | 273 | 274 | 275 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5489 | 1072 | 3554 | 2230 | 0357 |
| My reconstructed pronunciation | 2riuʳ | 1diụ | 1lɨõ | 1vị | 1liaa |
| Tangraph gloss | a syllable in surnames | a syllable in surnames | a transcription tangraph; the surname 梁 Lon | person | the surname La |
| Word | the surname Rurdu | ||||
| Translation | Rurdu, Lon, Vi, La, (or Rurdu, Lon people, La) | ||||
271: 5489 looks like 'hand' plus 'surname'. Its analysis is unknown, but I think it's a phonetic-semantic compound:
+
5489 2riuʳ 'the surname Rur' (pikpux) =
5736 2riuʳ 'to brew, ferment' (pikhan) +
2888 2mə 'surname' (dexpux)
272: Why doesn't 1072 contain the 'surname' radical pux (like 5489 above) instead of the almost meaningless radical dex 'person'?
+
1072 1diụ '' (famdosdex) =
0930 1diu 'to have' (famdosdux; phonetic) +
2888 2mə 'surname' (dexpux)
273: Why would a transcription tangraph be a semantic compound? Was the maternal regent 梁 1lɨõ (Lon) clan or Liangzhou regarded as the 'heart of the gods'?
+
3554 1lɨõ 'a transcription tangraph' (balpam) =
2518 2niee 'heart' (dexbalgea) +
5144 ʃɨõõ 'god' (pamjau)
274: 2230 belongs to a circular derivation chain:
+
2230 1vị 'person' (dexfou) =
2541 2dzwio 'person' (qaldex; semantic) +
0545 1dʒwɨu 'person' (foudex; cognate to 2541?; semantic)
=
0545 1dʒwɨu 'person' (foudex) =
2230 1vị 'person' (dexfou) +
5320 2dʒwɨu 'aerolite; lightning' (weidii; phonetic)
Note the implicit equation of dex 'person' with the subtly different dii.
Nie and Shi translated the fourth tangraph in line 55 as 千, implying a reading like tshiẽ rather than 1vị. But I can't see what tangraph they mean and can't find a similar-sounding surname tangraph resembling 2230.
275: Was the La family known for its poetry and related to the Me? If they were poets, did they specialize in praise and/or eulogies?
+
+
0357 1liaa 'the surname La' (bumbaebum) =
0347 1khə 'poetry' (bumbum) +
2919 2mie 'the surname Me' (baedexfak) +
0837 1liaa 'to praise, eulogize' (boabumcin; phonetic)
56: This line is definitely just a list of names, so if 55 is parallel, then 274 should also be a name.
| Tangraph number | 276 | 277 | 278 | 279 | 280 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2067 | 0703 | 5314 | 4712 | 1258 |
| My reconstructed pronunciation | 2si | 2dzii | 2ʔia | 2ʔiuʳ | 1tõ |
| Tangraph gloss | the surname Si | to conceal | the surname Ya | the surname Yur | the surname Ton |
| Word | the surname Sidzi | ||||
| Translation | Sidzi, Ya, Yur, Ton. | ||||
276: 2067 has no known analysis. It is probably a semantic-phonetic compound:
?
2230 2sị 'the surnmae Si' (dexzao) =
2541 2dzwio 'person' (qaldex; semantic) +
0545 2si 'mother' (zao = fexbaafir; phonetic; based on Chn 母 'mother'?)
277: Why wasn't the second half of Sidzi written with a unique character? Were the Sidzi regarded as the 'hidden Si' or those who hid the Si?
+
+
0703 2dzii 'to conceal' (bulbaeqol) =
5447 2do 'allative case postposition' (paibulcin; semantic) +
0275 2bii 'to cover' (feabaedao; semantic) +
0250 1bəị 'sand' (qiecok; semantic; the rare qol [4 tangraphs] and the more frequent qie [31 tangraphs] are not identical)
Note that 5447 should follow a noun, not precede it, so 5447 0275 0250 'to cover sand' does not constitute a grammatical Tangut phrase. I would expect 0250 5447 0275 'sand to cover'.
0703 2dzii can transcribe the Sanskrit syllable je [ɟee] (Grinstead 1972: 150). The Tangut dz- : Skt j- correspondence is expected since Tibetan and Chinese also borrowed from a variety of Sanskrit with alveolar affricates instead of palatals. But the mismatch in vowel heights (Tangut -ii : Skt -e [ee]) is hard to explain.
278: By my principles of romanization, 5314 2ʔia should be A sans the Grade IV medial -i-, but I"ll romanize it as Ya since its Chinese transcription 也 had *j- and it transcribed Chinese *j-syllables and Sanskrit ya (Nishida 1964: 127; Gong 2002: 444). Although there should be no initial j- in my reconstruction - a carryover from Gong's - I suspect that Tangut had such an initial and will include it in romanization whenever supported by transcriptive evidence.
The left side is probably a phonetic from Tangut period northwestern Chinese 羊 *jõ 'sheep' and the right side is dex 'person'. Hence it represents the people whose name sounds like 'sheep' in Chinese.
279: 4712 has no known analysis. It consists of a horned hat bio (from where?) plus the homophonous phonetic 2006 2ʔiuʳ 'upbringing' (cirzakcok):
+
?
I romanize it as Yur rather than Ur since its level tone near-homophone was transcribed as 余 with *j-
(Nishida 1964: 128).7.13.0:57: The phonetic of 2006 in turn must be
3042 1ʔiuʳ 'to breed' (cirzak)
The presence of 'water' in 2006 and 4712 is a carryover from this phonetic and does not mean that the Yur family or 'upbringing' had anything to do with water. But what does 'to breed' have to do with water?
280: Were the Ton somehow connected to one or more Lhe-clans?
1258 1tõ 'the surname Ton' (fouyeo) =
0545 1dʒwɨu 'person' (foudex) +
3230 2lhiẹ 'first half of Lhe-surnames' (dexyeo)
10.7.11.23:56: THE GOLDEN GUIDE: LINES 53-54: TANGRAPHS 261-270
53: If 263-264 and 265 aren't surnames, then this line has the structure
Possessor 1 (Possessor 2 (261-262) + Possessed 2 (263-264)) + Possessed 1 (265)
| Tangraph number | 261 | 262 | 263 | 264 | 265 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3664 | 2134 | 1547 | 4299 | 5307 |
| My reconstructed pronunciation | 1tʃɨə | 1zwị | 2xəĩ | 1lã | 1ɣwɪ |
| Tangraph gloss | first half of the surname Chyzwi | nephew | first half of Hinlan | second half of Hinlan | power; force |
| Word | the surname Chyzwi | Hinlan (= 賀蘭 Helan) | |||
| Translation | The power of Hinlan of Chyzwi, | ||||
261: 3664 and 5320 contain dii, not dex 'person':
+
3664 1tʃɨə 'first half of Chyzwi' (diihal) =
5320 2dʒwɨu 'aerolite; lightning' (weidii) +
3693 (reading unknown) 'close; near' (dexbelhal)
Were the Chyzwi associated with a lightning god as well as Hinlan?
262: Why wasn't a special tangraph created for the second half of Chyzwi? Why recycle the tangraph for 'nephew'? Were the Chyzwi descended from a nephew of a Chy clan?
+
+
2134 1zwị 'nephew' (dexvascok) =
0597 1ɣɨə 'mother's brother' (zasdex) +
0549 2diõ 'sister' (vasdex) +
2107 1tsəiʳ 'land; soil' (giigircok)
And what does 'land' have to do with nephews?
263: 1547 2xəĩ only shares an initial with *xɔ which would have been the pronunciation of 賀 He- of 賀蘭 Helan in the Tangut period. Could 賀蘭 *xɔlã̃ be a Sinification of a Tangut 2xəĩ-lã rather than the other way around? There was no *-əĩ in Tangut period northwestern Chinese.
What did Helan have to do with the Chyzwi?
The bottom of 1547 (geojux; 'sage' plus 'ladder') is unique.
264: 1547 is in the analysis of 4299 which has box 'wood' on top. box is similar in shape to 艹 'grass' atop the 蘭 -lan of Helan.
+
+
4299 1lã 'second half of Hinlan' (boxgiijux) =
4171 1dəụ 'field; vast' (boxdaidex) +
3333 2məəi 'god' (dexgiibil; gii can be short for 'waist; bird; sun') +
1547 2xəĩ 'first half of Hinlan' (famgeojux)
4171 is appropriate as a component of a placename.
Does 3333 indicate that Helan was divine?
265: If 5307 'power' is a surname, it would be analogous to English Strong (but not Power which can be cognate to poor but never cognate to power).
5307 looks like 'hand' (pik) + 'sage' (geo) but has a different analysis:
+
53071ɣwɪ 'power' (pikgeo) =
5459 kɨəə 'to supervise' (pikyos; phonetic and even semantic - the powerful oversee?)
5306 1dzwiə 'emperor' (paigeo; semantic)
54: I presume the structure is roughly similar to that of 53: a chain of possession:
Possessor 1 (Possessor 2 (Possessor 3 (266-267) + Possessed 3 (268)) + Possessed 2 (269)) + Possessed 1 (270)
I like how the English translation of this couplet has alliteration: 'The power ... the pleasure ...'
| Tangraph number | 266 | 267 | 268 | 269 | 270 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2472 | 3201 | 1530 | 3058 | 2480 |
| My reconstructed pronunciation | 1gwiə | 2di | 1mia | 2ziəəʳ | 1bɛɛ |
| Tangraph gloss | firm, solid | complete | river | water | entertainment; amusement; happy; pleasure; joy |
| Word | the surname Gwydi | ||||
| Translation | The pleasure of the waters of the river of the Gwydi. | ||||
Why was Gwydi written with recycled nonname tangraphs? Was the name a compound 'Firm-complete'?
266: 2472 must predate 1365, despite its analysis:
+
2472 1gwiə firm; solid' (dilqundex) =
3786 2rəiʳ 'shield' (dilqun; semantic) +
1365 2ʃɨu 'firm, solid' (famdilqundex; semantic)
267: The analysis of 3201 is unknown. The unhelpful dex 'person' is on the left.
268: What does 'ripe' have to do with 'river'?
1530 1mia 'river' (famhordex) =
3058 2ziəəʳ 'water' (cirzaa; fam < top of zaa) +
0632 1vəi 'ripe' (hordex)
Is the bottom right of 'river' an abbreviation of a phonetic
2436 2miaa 'fruit'
said to be the source of the right side of 'ripe'?
Is the river of the Gwydi the Yellow River running through Helan? What did the Gwydi have to do with this river?
269: I thought I already recently wrote about 'water', but Windows Vista can't find earlier posts about it. It has 'water' on the left and is clearly related to 2ʒɨu 'fish' which I presume is derived from it:
3058 2ziəəʳ 'water' vs. 3057 2ʒɨu 'fish'
Ah, found the post I was looking for by searching for 'fish': "Which Way Water?"
2480 appears in the various Tangut birthday wishes throughout my blog.
+
2480 1bɛɛ 'entertainment; joy' (dexweadex) =
0522 1dʒɨẽ 'quiet' (qisdex; semantic?)
5288 2khie 'happy; cheerful' (weadex; semantic)







































