Home
10.5.1.23:50: SEARCHING
FOR THE ANCIENT AND SPECIAL
I've been trying to come up with a cute name for David
Boxenhorn's Tangut Search program. Last night, I realized
that Tan sounds like Mandarin 探 tan
'search', so I was stuck at 探gut. (Gut searching?) The only gut
thing I could think of was 글 gŭl
'writing' as in hangul. But the final consonant doesn't match, and
Korean has nothing to do with Tangut. This afternoon, I came up with
探古特
Md Tangute
'search ancient special'
and then realized that the last two graphs are also in the existing word
唐古特
Md Tanggute
'Tangut'
with 唐 Tang 'Tang Dynasty' instead of 探 tan
'search'.
David's
program has three-letter alphacodes for tangraphic elements. One can
try to form existing words out of these letter sequences, though I
haven't succeded yet. (Element names that match existing words:
e.g., fan, don't count.) I thought it'd be
neat to give
Tangut Search an alphacode-based name, but there is no tangraph with
the alphacode tangut.
There are no alphacodes ending in -t.
I wonder why, because -s and -u (but not -v, -w, -y, or -z)
appear
as third letters in alphacodes. (Finally looked at the source code.
There are no alphacodes ending in stops other than -k.)
However, there are four tangraphs with an element tan:
| Tangraph |
Alphacode |
Reading |
Rhyme |
Rhyme.tone |
Gloss |
Notes |
 |
diotan |
dʒiaa |
24 |
2.21 |
(a surname) |
dʒ- is normally not
in a grade IV rhyme like R24*. Is this name of foreign origin?
The Tangraphic Sea analysis derives tan
from ソ丨 plus 丰 bor from cuobordex thiõʳ
R98 2.83 'to wave; to shake' (describing the Jaa family?).
ソ
丨 is from the 隹-like component of diotan's homophone diobishon 'male',
based on Chn 雄 'male'. Hence dioソ丨 is phonetic in diotan. |
 |
tangex |
bi |
11 |
1.11 |
grow; develop |
tan is from tantua
gex is from the right of foudex dʒu R2 2.2 'person'
atop the bottom right of basciadim mieʳ R79
2.68 'person' |
 |
tandim |
ŋeʳw |
93 |
1.87 |
to fear; to dread |
tan is from tangex
dim is from baepikdim ziẹ R64
1.61 'to hit; to touch; to fit exactly' |
 |
tantua |
bi |
11 |
1.11 |
first half of bi-vəiʳ 'abundant' |
tan is from tandim
tua is from the left side of tuadex vəiʳ
R82 1.77, the second half of bi-vəiʳ 'abundant'. |
tan in diotan may have nothing to do with the tan in the last
three tangraphs.
The sources of tan in the last three tangraphs form a closed
circle:
tangex < tantua
< tandim < tangex
Although tan may be phonetic in tangex and tantua (both bi
R11 1.11), there is no phonetic or semnatic similarity between tandim (ŋeʳw
R93 1.87) and the other two. So why does tandim contain tan?
The semantic functions of dim in tandim and the two
abbreviations of 'person' in tandim are also unclear.
*5.2.16:00: Li Fanwen's
(1986: 196) table of possible Tangut syllables excludes dʑǐâ
(equivalent to my dʒiaa), even though he
reconstructed dʑǐâ for diotan on p. 391.
But he also reconstructed ȵǐâ (which is in
his table) for diotan and

cirpancok 'glutinous rice'
but not for

cirgemcok 'marsh; bog'
on p. 390 even though all three belong to the same homophone group in Homophones
(38B44-46).
Their fanqie is


hingom 'clear away' + halbaequn (transcription tangraph)
Sofronov 1968: ni̭e + ndɪ̭a
LFW 1986: ȵɩe + dǐa (sic;
should be dǐâ)
Gong: nji + djaa
(the 1997 edition of Li Fanwen's dictionary has dʑji
as well as nji; the 2008 edition only has nji)
This site: ni or dʒi
+ diaa
hingom is in the fourth chapter of Homophones
for 'retroflex'-initial syllables, but the three tangraphs whose
initial is represented by hingom are in the seventh chapter for
palato-alveolar-initial syllables. Why wouldn't a fanqie
initial speller and the tangraphs with that initial be in the same
chapter of Homophones?
Li Fanwen (1986: 294-295) reconstructed palatal (not
retroflex!) ȵ- for most syllables in chapter four
and has no reconstructions for the remaining syllables.
Homophones contains no fanqie.
The fanqie for diotan and cirgemcok are in
the Mixed Categories volume of Tangraphic
Sea (18B22-31). There is no fanqie
for cirpancok, but its fanqie should be the
same as diotan and cirgemcok since they are in the same homophone group
in Homophones.
Perhaps Tangraphic Sea and Homophones
represent slightly different dialects of standard Tangut:
|
Tangraph
|
|
|
| Alphacode |
hingom |
diotan, cirpancok, cirgemcok |
|
Tangraphic Sea
|
n- (all members of the same fanqie
chain)
|
|
Homophones
|
n- (chapter IV)
|
dʒ- (chapter VII)
|
It's hard to believe that n- would
alternate with dʒ-.
Li Fanwen's reconstruction of palatals for all four tangraphs seems
more plausible, but how can it be reconciled with the fact
that
hingom's initial fanqie speller

tolgaidil: nɨə R30 1.29 'skirt'
has the initial fanqie speller

dexbiobaebescin: ni R11 2.10 'to listen;
to hear'
(cognate to niu 'ear', Old Chinese 耳 *nəŋʔ
'ear')
which is in chapter three
(dentals) of Homophones, not four
('retroflexes')?
Could Homophones preserve a three-way
contrast lost in the dialect of Tangraphic Sea?
|
Tangraph
|
|
|
|
| Alphacode |
dexbiobaebescin |
hingom |
diotan, cirpancok, cirgemcok |
|
Tangraphic Sea
|
n- (all members of the same fanqie
chain)
|
|
Homophones
|
n- (chapter III) |
ɲ- (chapter IV)
|
dʒ- (chapter VII)
|
I reconstruct a palatal ɲ- for hingom
following Li Fanwen (1986) but using an IPA symbol instead of ȵ-.
hingom belongs to R10 which is a grade III rhyme associated with
palatals rather than dentals.
10.4.30.23:59: WHICH
WAY WATER?
When I looked up

jux: reʳw R93 2.78 'ladder;
stairs; steps'
in Li Fanwen's 2008 Tangut dictionary on Thursday night, I saw

biuduudexcok: nəu R1 1.1
across it in the adjacent column. By sheer coincidence, it
containst the graph for 'black' that
I've been blogging about lately.
Its Tangraphic Sea analysis is
= +
+
biuduudexcok = cirzaa
+ duudexcok
nəu = top (sic!)
of zɨəʳ
'water' + all of nɨaa 'black'
(in Tangut noun + adjective order!)
What does biuduudexcok mean? Select the
blank space below for the answer.
'mud; mire; sludge'
Notice that cir is replaced by biu in biuduudexcok.
I suspect "top" should be "left", since cir is equated with biu in
 =
= +
+
biuhanfoi = cirgar + biohanfoi
ləu = left of niọ
'lubrication; oiliness' + bottom of ləu
'storehouse; warehouse'
What does biuhanfoi mean?
'moist; smooth; juice'
and the top of 'water' is fam (see below), not biu.
Similarly, cir is replaced by cen in wincen
(and fam + dos = win):
 =
= +
+
wincen = famdosdux + cirzaa
pa = diu
'have' + zɨəʳ 'water'
(in un-Tangut verb + object order instead of object + verb)
What does wincen mean? Select the blank space below for the
answer.
'wave'; loan from Middle
Chinese 波 *pa 'wave (since the Tangut were inland)
There are at least five different abbreviations of zɨəʳ
'water' in Tangraphic Sea:
|

1. biu |

2. fam |

3. cir |
0. cirzaa |

4. cen |
|
|

5. bil |
The only part of cirzaa which might not be used as an
abbreviation is 干 bel,
the bottom left of zaa. (Perhaps one or more of the
lost analyses in the second volume of Tangraphic Sea
contain bel < 'water'.)
Only one instance of fam < 'water' is known:
 =+
=+
famhordex = cirzaa + hordex
mia = top of zɨəʳ
'water' + all of vəi 'ripe; cooked'
What does famhordex mean? Select the blank space below for
the answer.
'river' which has nothing
to do with 'ripe'!
fam appears in 145 other tangraphs, not including components
which incorporate fam like zaa on the right side of 'water'.
Three instances of bil < 'water' are known:
 =
= +
+ +
+
famdiibil = famdaiher + foudex +
cirzaa
lã = top of ləụ
'stone; rock' + right of dʒu 'person' +
bottom right of zɨəʳ
'water'
What does famdiibil mean? Select the blank space below for
the answer.
'aerolite' which has
nothing to do with water!
 =
= +
+ ++
++
balcuubaebilcin = cirvaigii + giifexbaebul
+ cirzaa + bumdexcin
xe = top left of niooʳ
'water, dew' + bottom center of miuu 'deep pool' +
bottom right of zɨəʳ
'water' + right of ʃwa 'river'
What does balcuubaebilcin mean? Select the blank space below
for the answer.
'sea'; borrowed from
Tangut period northwestern Chinese 海 *xe (since the
Tangut were inland; the
Sea of Tangraphic Sea is a
native word cuojoi = ŋiõ)
Note how cir (not from 'water'!) is abbreviated as
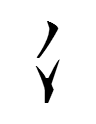
bal
and how giifexbaebul is reduced to a single vertical line!

bae
 =
= +
+
biubilceubil = biubilceugar +
cirzaa
riʳ = frame of mɛ
'cheese; fermented milk' + bottom right of zɨəʳ
'water' (合編甲 23.134)
What does biubilceubil mean? Select the blank space
below for
the answer.
'juice; soup'
bil appears in 261 other tangraphs, not including components
which incorporate bil like zaa on the right side of 'water'.
In Tangraphic Sea equations
cir, biu, and
cen
are equivalent. They may be considered to be allographs of
a single element whose shape is determined by position:
cir: left or center (260 tangraphs; abbreviation of 'water'
in at least 19)
biu: top or top right (9 tangraphs; abbreviation of 'water'
in at least 1)
cen: right (47 tangraphs; abbreviation of 'water' in at
least 3)
The 'water' figures are based on analyses in Tangraphic
Sea. The actual figures may be doubled if the lost second
volume of Tangraphic Sea is ever found.
cir is probably based on 氵, one of three allographs of Chinese
水 'water' in combinations:
氵: left (default)
氺: bottom
水: bottom and elsewhere
There are minimal pairs in sinography differing only in the
placement of 'water':
江 Md jiang 'river' : 汞 Md gong
'mercury'
泊 Md bo
'anchor a boat', po 'lake' : 泉 Md quan
'spring;
source'
One might think that X + 氺/水 graphs were created after the
combination 氵 + X was already used, but that is not usually
the case; e.g, 氵 + 將 does not exist, so I don't know
why 水 is at the bottom of 漿 'thick liquid'.
Similarly, one might expect minimal pairs in
tangraphy differing only in the placement of 'water' abbreviations.
Was biuduudexcok created because

cirduudexcok
with cir in default left-hand position already
existed?
cirduudexcok even has the same two source tangraphs as biuduudexcok:
=+
cirduudexcok = cirzaa
+ duudexcok
nɨaa = left of zɨəʳ
'water' + all of nɨaa 'black'
What does cirduudexcok mean? Select the blank space below
for the answer.
'deep, black'; cognate to
its homophone nɨaa 'black'
On the other hand, an abbreviation of 'water' was placed on
the right side of
wincen
even though there is no

cirwin
with an abbreviation of 'water' on the left.
'Water' itself contains cir on the left, but where does its
cir - or any of its other parts - come from? Unfortunately, the
analysis for it and

cirzuo: ʒɨu R2 2.2 'fish'
which contains the same components in a slightly different
arrangment are lost.
What determines which part of a tangraph is abbreviated? Why
wasn't 'water' just abbreviated in one or two ways to make it
recognizable? What
determines where that part goes in a new compound tangraph?
5.1.14:51: Maybe biu is for liquids which aren't water. Here
are
all nine tangraphs with biu:
| Tangraph |
Alphacode |
Reading |
Rhyme |
Rhyme.tone |
Gloss |
Notes |
 |
vaobiufil |
jooʳ |
103 |
1.94 |
to weave; to knit |
Only tangraph with biufil
Phonetic vaobiu from vaobiuceubil (see below) |
 |
vaobiuceubil |
jooʳ |
103 |
1.94 |
cyst |
biu from biubilceubil 'juice; soup' |
|
biuduudexcok |
nəu |
1 |
1 |
mud; mire; sludge |
biu from cirzaa 'water' |
 |
biuhangol |
ləu |
1 |
2.1 |
juice |
No analysis known
Cognate to biuhanfoi via *-H
suffixation > rising tone? |
|
biuhanfoi |
ləu |
1 |
1.1 |
moist; smooth; juice |
biu from cirgar 'lubrication;
oiliness' |
|
biubilceubil |
riʳ |
84 |
2.72 |
juice; soup |
biu from biubilceugar 'cheese;
fermented milk' |
|
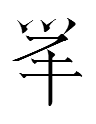
biubilceugar |
mɛ |
35 |
1.34 |
cheese; fermented milk |
biu from biubilceubil 'juice; soup' |
 |
biufal |
tsõ |
56 |
1.54 |
soup; broth |
No analysis known |
 |
biuguxdiadea |
ʃɔ̃ |
57 |
2.48 |
otter |
No analysis known
guxdiadea without biu is a homophone ʃɔ̃
'gray,
ashy color' (phonetic?)
Why 'liquid' instead of 'water'? |
10.4.29.23:59: TANGUT
SEARCH V. 3
I got a new version of it from David
Boxenhorn yesterday, but I fell asleep before I could try it
out!
It enables me to set the size of tangraphs in the results for
my searches. Larger is better. Pairs like


dexjux and gesjux
are difficult to distinguish at smaller sizes
though they're still easier to distinguish than this
trio. (One is easy to tell apart, but I needed Photoshop to
figure out the difference between the remaining two.)
The absence or presence of a dot is all that
distinguishes dexjux and gesjux which have completely different
readings:
dexjux: bi
R11 2.10* 'below; down'
gesjux: lyu
R3 1.3** 'low'
dexjux
may have dex ('person' as an independent tangraph) on the left because
its Chinese translation equivalent 低 has 亻 'person' on the left.
I
thought ges in gesjux might be dex plus a diacritic dot rather than an
element commonly identified as 'earth'. However, the Tangraphic
Sea analysis of gesjux identifies gesgir 'earth' as the
source of its left side.
= +
+
gesjux = gesgir + dexjux
lu 'low' = left side of lɨə̣
'earth' + right side of bi 'below, down'
'Earth' is semantically appropriate for 'low'.
The Tangraphic Sea analysis of dexjux is
unknown, but I would not be surprised if it included gesjux as the
source of its right side:
=(...) (...)+?
(...)+?
dexjux = (...)dex(...) + gesjux?
One might think that the common right side of dexjux and gesjux
jux: reʳw R93 2.78
by
itself would mean 'low' but it means 'ladder; stairs; steps' as an
independent tangraph and may be based on 弟, the phonetic of Chn 梯
'ladder'. Why write 'down'-graphs with 'ladder'? Conversely, is
'ladder'
an abbreviation of a 'low' graph, and if so, why? (The Tangraphic
Sea analysis of jux is unknown.)
4.30.00:25: Although 'ladder' makes no semantic sense as an
element in 'low' graphs, perhaps the logic for its choice went
something like this:
1. The Chinese graph for 'ladder' is 梯
'ladder'.
2. Our graph jux for reʳw 'ladder' is
based on its right side: 弟.
3. 弟 is nearly homophonous with 氐 'root, foundation, base'.
4. The Chinese graph for 'low' combines 氐
with 亻 'person': 低.
5. Therefore our graph dexjux for bi
'below; down' combines jux, based on a near-homophone of 氐,
with dex, our equivalent/derivative of 亻.
Tangraphs are based on abbreviations of sinographs (弟 <
梯) as well as other tangraphs.
*4.30.0:50: Li Fanwen
(2008: 612) lists the reading of dexjux as bji
2.10 in Gong Hwang-cherng's reconstruction. The underlining indicates a
long vowel. However, 2.10 is R11 which has a short vowel, so I
reconstruct dexjux as bi, equivalent to GHC's bji
sans underlining.
**4.30.2:10: Li
Fanwen (2008: 612) lists the reading of gesjux as ljwu
1.3 in Gong Hwang-cherng's reconstruction. GHC reconstructs a four-way
contrast between
| -ju R2, R3 |
-jwu R2, R3 |
| -u R1, R4 |
-wu R1 (but not R4) |
Although this looks neat, does any attested language have such
a contrast? Also, it does not differentiate between R1 and R4 or R2 and
R3.
I reconstruct a seven-way distinction:
|
Grade |
less labial |
more labial |
| R1 |
I: nonhigh |
-əu |
-wəu |
| R2 |
III: high nonpalatal |
-ɨu (or -u?) |
-u (or -wu?) |
| R3 |
IV: high palatal |
-iu (or -ju?) |
-yu (or -ɥu or
just -y?) |
| R4 |
II: centralized |
-ʊ |
(none) |
I think all seven rhymes came from a pre-Tangut *-u
and were conditioned by different preceding consonants and/or
presyllables:
|
Grade |
less labial |
more labial |
| R1 |
I: nonhigh |
low vowel presyllable *Cʌ- |
labial preinitial
(and in at least some cases prefix) *P- |
| R2 |
III: high nonpalatal |
(high vowel presyllable *Cɯ-) +
postalveolar initials |
| R3 |
IV: high palatal |
(high vowel presyllable *Cɯ-) +
labial, dental, alveolar, velar initials |
| R4 |
II: centralized |
back (uvular?) (pre)initial *Q-? |
(*-wʊ merged with
*-ʊ?) |
Note that R2 and R3 initials are not in completely
complementary distribution. Exceptions to the basic pattern (e.g., bɨu
R2) may be loanwords or conditioned by preinitials.
Tangut Grade II rhymes may have had pharyngealized vowels like
Hongyan
Qiang (whose /iˁ/ resembles [ɛ] but approaches the centrality
of [ə]) or velarized vowels in Puxi
rGyalrong. Just as earlier *-w- "may
have given rise to a backing of the nucleus in Hongyan" (Evans
2006: 114), a pre-Tangut back consonant may have conditioned
the lowering of *u.
10.4.27.23:57: THE
ALPHACODE AS A TANGUT B SURROGATE
David
Boxenhorn's
tangraphic element alphacodes are a dream come true. Four years ago, I
experimented with naming tangraphic elements using letter sequences,
but I never got around to creating a full system.
I can use such sequences as pronounceable substitutes for
unknown Tangut B sound values. For example,

dexduudexcok and duudexcok
'night' and 'black'
would have Tangut B readings that were homophonous except for
(a prefix?) 'dex-':
dex-duudexcok 'night' (black thing?) = dex- (nominalizer?) +
duudexcok 'black'
(There is no morphological relationship between
the Tangut A readings kõ 'night'
and nɨaa 'black'.)
Are
there any other examples of dex- as a nominalizing prefix? Using
David's search engine, I could look up "^dex" and see if there are any
other examples of nouns written as 'dex' + adjective. Unfortunately, I
don't have time to look at all 555 dex-graphs. I tried looking up a few
adjectives to see if they had dex-prefixed versions, but couldn't find
any noun-adjective pairs.
I did, however, find this unusual pair:


pə R28 1.27 'big; thick; head' (dexdiodal)
pə R28 1.27 'little livestock' (diodal)
They are homophonous yet have somewhat opposite meanings and
cannot be cognate.
They remind me of the pair


bɨə R31 1.30 'tall, high' (bukgak; gak is
also an independent tangraph for the cognate word bie
'high')
bɨə R31 1.30, first half of bɨə-bi
'below' (bukjux)
that Gong Hwang-cherng found.
4.28.1:14: The Tangraphic Sea analyses of
the pə tangraphs above are circular:
= +
+
dexdiodal = dexwun + diodal
pə 'big; thick; head' = left of pe
'firstborn' + all of pə 'little livestock'
pə 'head' and pe
'firstborn' are probably cognate (cf. Chinese 頭生 'headborn' for
'firstborn').
pə 'litte livestock' is presumably phonetic.
=+
diodal = dexdiodal + dexgoldal
pə 'little livestock' = center
of pə 'big; thick; head' + right
of jiw 'achievement' (why?)
Which came first, dexdiodal or diodal? Similar questions could
be asked
about the A and B tangraphs whose derivations follow this pattern:
A = B + C
B = A + D
such as the high/low pair I just mentioned:
=+
bukgak = bukjux + feigak
bɨə 'high' = left of bɨə
(first half of 'below') + right of so
'tall; high'
The analysis of feigak is unknown, but it wouldn't surprise me
if it were
feigak = (...)fei(...) + bukgak
=+
bukjux = bukgak + dexjux
bɨə (first half of 'below') = left of bɨə
'high' + right of bi (second half of
'below')
The analysis of dexjux is unknown, but it wouldn't surprise me
if it were
dexjux = bukgak + bukjux
10.4.26.23:51: THE BEST
ARTICLE ON TANGUT WRITING EVER
... is Andrew
West's, not mine, and certainly not this post.
I confess that I was one of the "others" Andrew is referring
to below (emphasis mine):
[...] unlike most Chinese radicals, Tangut
radicals do not have a single fixed meaning, and so giving
names to them (as Nishida and others have done) is at best not very
useful, and at worst misleading.
I use names because it is inconvenient to constantly insert
graphics. At the moment I think using David
Boxenhorn's alphacodes avoids the problem of erroneous
semantic assocations. Thus I'd say that

na 'night' (dexbeldex)
at first glance consists of three elements arbitrarily named
dex, bel, and dex instead of PERSON, SURROUND, and PERSON.
However,
I think names like PERSON and SURROUND have some value as they
represent hypotheses about their referents' origins (as opposed to
their referents' functions within a given
tangraph).
The element dex (PERSON) represents the Tangut word dzwio
'person' as an independent tangraph. It may
be derived from a four-stroke variant of Chinese 人 'person' that I
can't find in Unicode or the Taiwanese variant dictionary, though it is
in Grinstead (1972: 56). I have seen that variant in modern times but
don't know if it was in use in the northwest of China during the Tangut
period.
The element bel (SURROUND) may be derived from the
cursive form of the phonetic 韋 of Chinese 圍 'surround'. The
modern
simplification 韦 of 韋 is based on that cursive form.
The Tangraphic Sea analyzed na
'night' as
= +
+
dexbeldex = dexbelpax + dexduudexcok
left of na (first half of na-raʳ
'tomorrow') + left of kõ 'night'
dividing it into two
|

|
|
| dexbel < dexbelpax |
dex < dexduudexcok |
instead of three parts:
kõ 'night' in turn was analyzed as
=+
dexduudexcok = dexbeldex + duudexcok
left of na 'night' + all of nɨaa
'black'
i.e., as
|
|
|
| dex < dexbeldex |
duudexcok < duudexcok |
In short, the two tangraphs for 'night' are supposedly derived
from each other.
And
'black' was derived from ... can you guess?
=(?)+
duudexcok = ? + dexduudexcok
or dexduudexcok
Unfortunately, part of the equation is missing from Tangraphic
Sea, so it's not clear whether 'black' should be split into
|

|

|
| duudex < (...)duudex(...) liọ
'how' |
cok < dexduudexcok |
or into
|
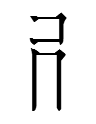
|

|
| duu < (...)duu(...) |
dexcok < dexduudexcok |
(There is no independent tangraph duu.)
or even
|
|
|
|
| duu < (...)duu(...) |
dex < (...)dex(...) |
cok < dexduudexcok |
My guess is the second or third analysis since liọ
'how' has no obvious semantic or phonetic relationship with nɨaa
'black'.
I
assume that dex was created for 'person' before any compounds with dex
were created. But what is dex doing in the tangraphs for
'night' and 'black' in the first place? In more abstract terms, how do
we get from X for A to combinations of X for B which has no
obvious semantic or phonetic similarity to A? What determines the
method of abbreviation? Why aren't characters abbreviated in a
consistent manner? dexduudexcok can be abbreviated either as dex or as
(dex)cok or even as dexduu, the left and center of

swie 'clear, obvious' (dexduupak)
And what determines the placement of abbreviations? Why place
the abbrevaition of dexduudexcok on the left of dexduupak
but on the right of dexbeldex?
10.4.25.23:50:
NIGHT FLOW TOMORROW?
I
think I already blogged about this Tangut word

na-raʳ 'tomorrow'
that came up in last
night's post, but I don't mind
covering the same topics again because I might come up with something
new, especially now that I've got a second, even more powerful version
of David
Boxenhorn's tangraphic search engine. Thanks, David!
The meaning of 'tomorrow' can't be easily guessed from the
dictionary analyses of its components:
=+
na- = left and center of na
'night' + left of dzị 'to cross' (海 22.231)
(Li Fanwen 2008 has a mistranslation of the analysis as 夜左過全 instead of 夜左過左.)
=+
-raʳ '= right of na(-raʳ)
+ center of raʳ 'to flow, leak, pass' (合編甲� 23.021)
I thought 'tomorrow' might be from 'night (na)
flow
(raʳ)': i.e.,
what follows after the night flows away. But I feel that's contrived.
Is there any language with a similar compound word for 'tomorrow'?
The element

'surpass' (alphacode pax; Nishida radical 241;
< 戉, phonetic of Chn 越)
is shared by the tangraphs for both halves of na-raʳ
'tomorrow' and is presumably semantic if my 'night flow' etymology is
correct.
The right half of the second half of na-raʳ
'tomorrow'
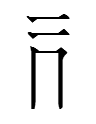
(no known meaning; alphacode dai; Nishida radical 104)
is phonetic and appears in other tangraphs pronounced raʳ.
Could it be derived from the Khitan small script character  ra? The strokes (丿一
丨) can be rearranged into a ㄇ shape and the horizontal line at the top
could be doubled. Even if that hypothesis is wrong, the possibility of
Khitan influence on tangraphy should be investigated.
ra? The strokes (丿一
丨) can be rearranged into a ㄇ shape and the horizontal line at the top
could be doubled. Even if that hypothesis is wrong, the possibility of
Khitan influence on tangraphy should be investigated.
Is there a more plausible Chinese source for it?
Did 罗 (a simplification of 羅 Late Middle Chinese *la)
already exist by the 11th century when tangraphy was created? The top
element 罒 could have been reduced to 二. The bottom element 夕 could have
been rotated 45 degrees counterclockwise minus one
stroke to
form ㄇ.
'majestic, glorious' (alphacode: dexbex)
is a shared element in the homophones
na(-raʳ) 'tomorrow' (alphacode: dexbelpax)
and
na 'night' (alphacode: dexbeldex)
which is read as pi by itself and means
'majestic, glorious'. I think dexbex is a graphic calque of
Chn 偉 'great' =
人 'person' (cf. PERSON dex) +
韋 'leather' which is also in 圍 'surround' (cf. 干 SURROUND
bel, probably a simplification of 韋 - did the Chinese simplication 韦
already exist in the 11th century?)
'Majestic'
has nothing to do with 'tomorrow', so I would expect dexbel to be
phonetic in dexbelpax and dexbeldex. Yet those two tangraphs are
pronounced na, not pi. Was
dexbel chosen because pi or even something like *wi
(cf. 偉 Late Middle Chinese *wi) was a
Tangut B word for 'night' (scenario A)? Or was na a
Tangut B word for 'majestic' - the translation equivalent of Tangut
A pi (scenario B)?
Scenario A
| Gloss |
Alphacode |
Tangut A |
Tangut B |
| majestic |
dexbel |
pi |
? |
| night |
dexbeldex |
na |
pi or wi? |
| 1st half of 'tomorrow' |
dexbelpax |
(pi
or wi?) |
(Could the Tangut B word for 'tomorrow' also be 'night-flow': *pi
... or *wi ... with a Tangut B word for
'flow'?)
Scenario B
| Gloss |
Alphacode |
Tangut A |
Tangut B |
| majestic |
dexbel |
pi |
na? |
| night |
dexbeldex |
na |
? |
| 1st half of 'tomorrow' |
dexbelpax |
? |
In either scenario, dexbel is a double-function
phonetic. Japanese writing conains a few double-function
phonetics.Japanese 國字 kokuji (made-in-Japan
characters) on occasion have phonetics based on native Japanese
readings (訓 kun) as well as Sino-Japanese
readings (音 on): e.g., 升 is a
phonetic for both the on reading shou
and the kun reading masu:
| Graph |
Semantic |
Phonetic |
Gloss |
On |
Kun |
| 升 |
(升 cannot be
decomposed.) |
1.8 liters |
shou |
masu |
| 枡 |
木 'wood' |
升 |
measuring box |
(none) |
| 昇 |
日 'sun' |
rise |
shou |
nobo- |
枡 'measuring box' has no on
reading because it is a kokuji. Similarly,
some tangraphs may not have had Tangut B readings because they were
devised to write Tangut A words without Tangut B equivalents. I assume
all tangraphs had Tangut A readings which are recorded in
Tangut dictionaries.
Although there is no good evidence for Tangut B, is there any
other way to explain why 'night' and the first half of 'tomorrow'
incorporate 'majestic', a semantically and phonetically
different tangraph?
Tangut
fonts by Mojikyo.org
Tangut radical font by Andrew
West
All
other content copyright
©
2002-2010 Amritavision

{kind=link}