



? qulugh ai nai sair juri ? nyair
'white rat year, head month, twenty two day'
20.2.15.23:03: WHITE RAT 1.22
? qulugh ai nai sair juri ? nyair
'white rat year, head month, twenty two day'
1. Listening to the bilingual version of "Before
the Next Teardrop Falls"
this afternoon, I couldn't help but wonder what if the lyrics of that
song served as a future 'Rosetta Stone' for one of its two languages.
Years of working on Pyu have made me see Rosetta Stones everywhere.
2. Tonight while
copying the 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan
Small Script)
hand copy of the
epitaph for Empress 仁懿 Renyi (?-1076) of the Khitan Empire, I was
puzzled by a Khitan small script character that I had never seen
before: 𠈌 in block 2 of line 26. But 𠈌 is in fact two instances of 仌
<o> side by side. Duh. Does <o.o> represent a long vowel?
3. Kiyose (1977: 114) and Jin (1984: 131) read the Jurchen phonogram
transcribing Ming Chinese 千 *cian 'thousand' as cen
(in my pseudo-Möllendorff
notation). I initially read it as ciyan since 千 was later
Manchuized as ciyan, but I reconsidered because that phonogram
also represents the first syllable of the Jurchen verb cognate to
Manchu cendembi 'to check' in the jinshi
monument of 1224 and the Sino-Jurchen vocabulary of the Bureau of
Translators.
I tentatively conclude that Jurchen and Manchu had different
conventions for borrowing northern Chinese *-ian:
Jin and Ming Chinese *-ian > Jurchen -en
Qing Chinese *-ian > Manchu -iyan
Or did they? Did the Jurchen use one phonogram for both native cen and borrowed ciyan?
4. Tonight I heard Jack's Project's "Shy Shy Sugarman". I thought it was odd that Jack - Jack White (born Horst Nußbaum) - would sing in German under a pseudo-English name. The English Wikipedia says
White changed his name to make it easier to deal with English-speaking stars and their managers.
But he was recording under the White stage name as early as 1966, years before he worked with Anglophones in the 80s. Was the idea to make him seem like Peggy March who really was an Anglophone despite recording in German?
March cowrote "When the Rain Begins to Fall" produced by Jack White. Small world.
20.2.14.23:50: WHITE RAT 1.21
? qulugh ai nai sair juri ? nyair
'white rat year, head month, twenty one day'
1. I just noticed a dotted two-stroke version of the hiragana し <si> in Ultraman Leo #45 from forty-five years ago today. The dot is a remnant of the top stroke of the source character 之 whose strokes beneath the dot have been reduced to one. I can type dotless し <si> and 'dotted Z' 𛁄 <si> in Unicode but not dotted し. Now I wonder how many times I saw dotted し but failed to notice the dot.
2. Today I rediscovered ธีระพันธ์ เหลืองทองคำ Theraphan Luangthongkum's "A View on Proto-Karen Phonology and Lexicon" (2019). She reconstructs
'four':
Proto-Northern Karen *litᴰ
Proto-Central Karen *hlwiᴬ
Proto-Southern Karen: *lwiᴮ
'five': Proto-Karen *ŋjatᴰ
Unable to reconcile the northern, central, and southern proto-forms for 'four', she refrained from reconstructing a Proto-Karen word for 'four'.
The *-t forms are unusual in Sino-Tibetan. Sino-Tibetan
words for 'four' and 'five' are typically open syllables: e.g., Old
Tibetan bzhi and lnga. Proto-Karen has *-t in
'seven', 'eight', and 'nine'. I would reconstruct *-t in
Proto-Sino-Tibetan 'seven' and 'eight'. Did *-t spread from
those numerals? If it did, why is Proto-Karen 'six' *khrowᴬ without *-t?
Could *-t really have 'jumped' over 'six' to spread to 'five'
and - in northern Karen - 'four'? Did *-t not take root in
'six' because *khrowt would have had an impossible
double coda? (Other Sino-Tibetan languages have -k or the like
in 'six', so Proto-Karen *-w is unexpected in 'six',
particularly since *-ok is a permissible rhyme in Proto-Karen.)
The *-w- in Proto-Central and Proto-Southern Karen 'four'
might be from an earlier *labial stop like the b- in Old
Tibetan bzhi < *blʲi 'four' or the p- in Pyu
plaṁ /p.lä/ 'four'.
I can't explain the *-j- in Proto-Karen 'five'.
3. Most Vietnamese names are constructed from a limited set of Sino-Vietnamese building blocks. So Vietnamese names that have non-Sino-Vietnamese elements jump out at me - like 潘{廷庭亭}¹X Phan Đình Giót, the name of a hero of 奠邊府 Điện Biên Phủ. His last words were all Chinese loanwords:
決犧牲 ... 爲黨 ... 爲民
Quyết hy sinh… vì Đảng… vì dân
lit. 'determine sacrifice ... for Party ... for people'
'Determined to sacrifice ... for the Party ... for the people'
How is Phan Đình Giót written in Chinese? Semietymologically with a phonetic transcription character for the non-Sino-Vietnamese third syllable? I wouldn't expect a Chinese writer to look up the nom character for Giót: 埣.
I don't know what 埣 giót means or even if it is the Giót in Phan Đình Giót. The character is a semantophonetic compound:
土 <EARTH> + 卒 tốt
nomfoundation.org and hvdic.thivien.net tell me that 埣 is in the word khuôn giót. khuôn (variously spelled² 匡 ~ 困 ~ 囷 ~ 坤 ~ 𣟂) means 'model'. Does khuôn giót refer to a mold for something to do with earth: e.g., clay?
¹I can't tell whether Đình is 廷 court', 庭 'courtyard', 亭 'pavilion', or something else.
²All spellings of khuôn have -n phonetics except for 匡 which has an -ng phonetic 王. I presume 匡 reflects a dialect in which -n backed to /ŋ/.
4. I just downloaded Andrew West's beta versions of
BabelMap and BabelPad
so I can see Khitan small script readings. AVG scared me when it told
me I'd have to wait up to 156 and 154 minutes respectively to have them
checked for viruses, but both were OKed in minutes.
5. I agree with Andrew West on Jurchen
<tai>:
Another possibility is that Jurchen <tai> is a deliberate merging of the two Chinese characters 天 'heaven' and 太 'great', rather than just a random extra stroke added to 太.
<tai> could then be a semantophonetic composite.
6. Tonight I was surprised to learn that Disney Tsum Tsum are called 썸썸 Ssŏmssŏm. The name sounds like a Koreanization of a hypothetical English pronunciation [sʌm sʌm] of Tsum Tsum instead of a direct borrowing from Japanese ツムツム Tsumutsumu (which should correspond to Korean 쓰무쓰무 Ssŭmussŭmu or 쯔무쯔무 Tchŭmutchŭmu).
20.2.13.23:44: WHITE RAT 1.20
? qulugh ai nai sair juri nyair
'white rat year, head month, twenty day'
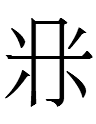
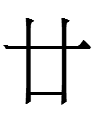
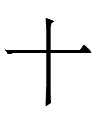
1. The Khitan large script character for 'twenty' looks exactly like Chinese 廿 <TWENTY> (Liao Chinese *ʐiʔ¹?) but represents a completely unrelated word.
If Khitan juri 'twenty' is jur 'two' plus -i, are the other unknown tens also X + -i: e.g., guri 'thirty', duri 'forty', etc.?
¹This is a guess based on the fanqie 人執 *ʐin-tʂiʔ in the Liao dynasty dictionary 龍龕手鑒 Longkan shoujian (The Handy Mirror in the Dragon Shrine, 997).
2.15.14:17: Fanqie need not reflect contemporary pronunciation, so there is no guarantee that 人執 is not a relic.
My undated copy of 辭海 from the 20th century gives the fanqie 日力 rì-lì for 廿 niàn and says 廿 is pronounced like 入 rù. Maybe that makes sense in some Chinese varieties, but it certainly doesn't make sense for modern standard Mandarin. The equation of 廿 and 入 was valid for Middle Chinese in which both were pronounced *ɲip. The fanqie 日力 might be a relic from a post-Middle Chinese period when 日力 was pronounced something like Liao Chinese *ʐiʔ-liʔ representing *ʐiʔ. 日力 cannot be a Middle Chinese fanqie since 力 ended in *-k in Middle Chinese, conflicting with the *-p of 入.
2. After reading Tournadre (2014), I'm going to be using 'Tibetic' the way I use 'Mongolic':
The term "Tibetic" could, however, become a useful replacement for the notion of "Tibetan dialects", which is not appropriate for various reasons.
First, the notion of "Tibetan dialects" implies the existence of a single "Tibetan language". However, the so-called "Tibetan dialects" refer in fact to various languages which do not allow mutual intelligibility.
[...]
Second, these "Tibetan dialects" are spoken not only by Tibetans per se but also by other ethnic groups such as Ladakhi, Balti, Lahuli, Sherpa, Bhutanese, Sikkimese Lhopo, etc. who do not consider themselves to be Tibetans. They do not call their language "Tibetan". In a similar way, we do not talk of Latin Languages but of Romance languages and do not think of French, Portuguese, Italian, Catalan or Romanian as various dialects of Latin.
With the recent descriptions of many new "dialects" or "languages", scholars of Tibetan linguistics have come to realize the incredible diversity of this linguistic area. The representation of a single language is no longer viable and we have to speak of a language family. In fact, the Tibetic linguistic family is comparable in size and diversity to the Romance or Germanic families.
3. Mathieu Beaudouin solved a mystery I've been wondering about for years: the difference between the locative markers 𗅁 2u1 and 𘂤 1kha1 in Tangut. I hope he next investigates how the third locative marker 𘇂 2gu1 ('medessive' in his analysis) differs from 𗅁 and 𘂤 ('inessive' and 'interessive' in his analysis).
2.14.0:34: Wiktionary doesn't have entries for medessive and interessive yet. Here's a set of flash cards for 'essives' excluding medessive.
2.17.23:12: I don't know what medessive means.
4. Last night I learned about a "security video feeds streaming
platform" called 황새울 Hwangsaeul. 황새 hwangsae is Korean for
'stork'. 새 sae is 'bird', but what is 황 hwang which
sounds like Sino-Korean? I can't think of any appropriate Sino-Korean
morpheme hwang: e.g., 黃 hwang 'yellow' doesn't make
sense since storks aren't yellow. This
site (from which I got the description of Hwangsaeul that I quoted)
says,
Hwangsaeul itself means "stork's nest". It is the street in Seongn
am where SK Telecom offices were located.
But ul doesn't mean nest (which would be 둥지 tungji). Martin et al. (1967: 1246) define ul as 'fence, hedge, enclosure; outer rim of shoes'. So I'm not sure what Hwangsaeul means.
2.15.23:12: Martin et al. (1967: 1246) also list a native Korean word 울 ul for 'trillion' which is surprising to me since I would have thought all Korean higher numerals were borrowed from Chinese: e.g., 兆 cho 'trillion'.
울
'trillion' is not in Naver's monolingual dictionary.
5. Until I read this Wiktionary entry today, it never occurred to me to link mum's the word with mummer, much less mime. Are m-words sound-symbolic for silence because one can make an [m] sound while keeping one's llips shut?
6. Can one receive a heads up for something positive? I
don't get that impression from this Wiktionary entry.
7. I've wondered about Amy Klobuchar's
surname. It turns out to be Slovene even
though ch is pronounced as in French in American English
(despite the un-French K-!).
2.14.0:22: The
Slovene Wikipedia says her great-grandfather's name was Klobučar
with č [tʃ].
8. While copying the Sino-Jurchen
vocabulary of the Ming dynasty bureau of translators, two graphic
etymologies occurred to me.
8a. The Jurchen phonogram
<giyan>
may be cognate to Chinese 更. The use of <giyan> for giyan
[kʲɑŋ] might be a carryover from the Parhae script that coexisted with
Late
Middle Chinese since Pulleyblank reconstructed the Late Middle Chinese
reading of as *kjaːjŋ.
Kiyose and Jin read <giyan> as <giyen> [kʲən] in
my pseudo-Möllendorff
notation, but if what might be called 'Sino-Jurchen' worked like
'Sino-Manchu', northern Chinese *kjan would be borrowed as giyan,
not giyen.
8b. The Jurchen phonogram
<shu>
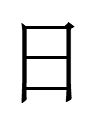
may be from 昼 (Liao and Jin Chinese *tʂiw), one of many variants of 晝 (I like the one with 日 surrounded by four lines).
2.15.23:57: An obvious problem with that derivation is the phonetic
mismatch of Jurchen sh- with Chinese *tʂ-. But such a
mismatch has a parallel with the mismatch of Jurchen sh- and
Mongolic c- in words like Jurchen shanggiyan
'white' (cf. Written Mongolian caghan 'white').
Then again, Jin (1984) derives <shu> from a variant of 書 (Jin
Chinese *ʂu) attested at Dunhuang resembling
the older version of <shu> from the Jurchen Empire. So never mind what I said.
20.2.12.23:42: WHITE RAT 1.19
1. Andrew West corrected my post about ɛ̃fini:
? qulugh ai nai sair par ish nyair
'white rat year, head month, ten nine day'
The Wikipedia file name (url) uses Ɛ̃fini because of a technical restriction, but the actual article title is ɛ̃fini.
I conflated the file name in the address bar with the article title within the article itself. I never thought of articles as being files before.
I've long known about that technical
restriction but never understood the reason for it.
2. I've long known about the obsolete practice of German-like (but
inconsistent) noun capitalization in English. But I didn't know how
it started until last night.
3. I hope to see Chris
Button's Derivational Dictionary of Chinese and Japanese Characters
some day.
4. I didn't know thorn (Þ) was ever written with a diagonal stroke until I saw this tweet by Andrew West last night.
I didn't even know about U+A764 LATIN CAPITAL LETTER THORN WITH
STROKE (Ꝥ) and U+A765 LATIN SMALL LETTER THORN WITH STROKE (ꝥ) until
now when I looked at this document
that Andrew and Michael Everson wrote.
5. Seeing this
cartoon of Latin phrases used in English
made me think of Literary Chinese four-character sayings in Japanese.
Are there Arabic phrases playing a comparable role in the Islamic world?
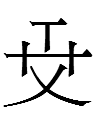
6. I confess it's taken me years to realize that the Jurchen phonogram
<tai>
is simply Chinese 太 <GREAT> with a line on top rather than
Chinese
天 <HEAVEN> with a dot added. That
obvious derivation was in Jin (1984: 4) all along, and I never noticed
it, possibly because I encountered the character through Kane (1989:
23) and never looked it up in Jin (1984) before. Wait ... Kane (1989:
23) in fact derives <tai> from太! I've looked at that page many
times since the mid-90s. How did I overlook that!?
It's not possible to date the creation of <tai> on purely phonological grounds, as 太 was pronounced in Chinese like Jurchen tai for centuries. In theory <tai> could be a carryover from the lost Serbi script from c. the 5th century - or the mostly lost Parhae script from c. the 8th century. <tai> is not known to exist in the Khitan large script (which uses an exact lookalike of Chinese 太 as a phonogram <tai>), so <tai> is either inherited from an earlier script or is a 12th century Jurchen creation.
20.2.11.23:44: WHITE RAT 1.18
? qulugh ai nai sair par nyêm nyair
'white rat year, head month, ten eight day'
1. Yesterday I wrote about 文 fumi 'writing' which is often thought to be a borrowing from Chinese 文 'writing' (presumably from a reading like northwestern Middle Chinese *ɱvun), but I would not expect Chinese *-n to be borrowed as Japanese -mi.
For years I've thought the word might have been borrowed from Paekche, the language of the people who taught literacy to the early Japanese. But no such Paekche word is known. Nor is there any plausible Korean cognate for such a word.
So last night I reconsidered another old idea of mine: that fumi
'writing' might be a repurposing of fumi
'stepping'. Tonight I verified that 'writing' and stepping' would have
had the same ancient accentuation (*high-low). But that's still not
enough. If writing (marks on paper) were likened to steps on the
ground, why doesn't the verb fum- 'step' do double duty for
writing? The actual verb for writing is kak- 'scratch'.
2. Twenty-five years ago yesterday, the Kakuranger team fought Yamanba. The 'real' yamanba is also called a yamauba. Yama is 'mountain' and uba is 'old woman'. The variant yamanba [yamamba] seems to retain a trace of earlier *[mb]:
*yamaumba > *yamaũmba > *yamaũba > *yamamba ̣̣(or yamauba)
uba seems to belong to a word family with oba < womba
'aunt' and oba < əpəmba 'grandmother'. *əpə-
is 'great', so *-mba is presumably a contraction of the linker *nə
and an otherwise unattested noun *pa 'old woman'. (Its
resemblance to Middle Chinese 婆 *ba 'old woman' is
coincidental.) But what is wo-? It can't be any of these wo
listed in Martin (1987: 503):
'male'
'little'
'hill'
'tail'
'hemp'
'cord'
And there is no candidate for u- in uba < *umba.
The accentuation of the ba-words has different pitches on the second syllable, possibly implying the various ba are not related:
oba 'aunt': class 2.1 *high-high(-high)
oba 'grandmother': class 2.5 *low-high(-low)
uba 'old woman': class 2.2b *high-low-(low)
Pitches in parentheses are for following particles.
3. I've long assumed that English girl had no cognates, but maybe it does.
4. Japanese 山茶花 <MOUNTAIN TEA FLOWER> sazanka looks as if it should be read ˟sansaka. Wikipedia thinks there was 音位転換 metathesis, but I have an alternate derivation that accounts for the -z- left unexplained by metathesis (which would produce ˟sasanka):
*sansakwa > *sansankwa > *sanzankwa > sazanka
The species name Camellia sasanqua is either from a variant *sasankwa (with metathesis?) or a misreading of a kana spelling ササンクワ <SA SA N KU WA> without the voicing mark.
Wikipedia says the 濁音符 voicing mark wasn't used as late as 1945 in
the text of the Jewel
Voice Broadcast: e.g.,
朕カ志ニアラス
<I ka WILL ni a ra su>
chin ga kokorozashi ni arazu
'not Our [imperial] will'
now written as
朕が志にあらず
<I ka" WILL ni a ra su">
with voicing marks.
20.2.10.22:04: WHITE RAT 1.17
? qulugh ai nai sair par ? nyair
'white rat year, head month, ten seven day'
1. On Saturday morning I was listening to the music of 馬飼野康二 Makaino
Kōji. He used the pseudonym Michael Korgen when foreign
composers were in vogue for
Japanese commericals. I love pseudonyms that vaguely sound like real
names.
2. Last night I got a couple of surprises from Wikipedia's Irish orthography article:
2a. On v (in the loanword vóta from yesterday):
It occurs in a small number of words of native origin in the language such as vácarnach, vác and vrác, all of which are onomatopoeic. It also occurs in a number of alternative colloquial forms such as víog instead of bíog and vís instead of bís as cited in Niall Ó Dónaill's Foclóir Gaeilge–Béarla (Irish–English Dictionary).
2b. I had no idea /z/ existed in at least one Irish dialect:
the phoneme /z/ does exist naturally in at least one dialect, that of West Muskerry, County Cork, as the eclipsis of s.
That eclipsed s is written as <zs> in Cape Clear
Irish.
s does not undergo eclipsis in standard Irish.
3. I forgot about Mazda's ɛ̃fini (IPA for French infini) division until last night. It's the only IPA brand name I've ever seen. The Wikipedia ɛ̃fini entry says IPA is "sometimes used in product naming" in Japan. What are other examples?
2.11.22:16: I just noticed the WIkipedia article for ɛ̃fini is titled Ɛ̃fini with U+0190 LATIN CAPITAL LETTER OPEN E in order to conform to Wikipedia's convention of beginning all article titles with capital letters.
2.26.23:06: No, see Andrew West's correction here.
4. Kiyose (1977: 114) reads Jurchen
'marquis'
as hau. Jin (1984: 153) reads it as xao or xou. The difference in initials is purely notational. h and x both represent the initial that I reconstruct as uvular [χ]. The different between au and ao is also purely notational; both are roughly [ɑw].
The word is clearly a borrowing from Ming (or earlier) northern Chinese 侯 *xəw (= heo in my pseudo-Möllendorff notation) 'marquis', so I read it as heo [xəw] which is exactly like Manchu heo [xəw] 'marquis'.
侯 'marquis' is a very stable word in the north. In Middle Chinese, its rhyme shifted from *-ow to *-əw and remained unchanged in the lineage of standard Mandarin until recently when *ə rounded to o to assimilate to the following w: *xəw > hóu [xow˧˥]. Manchu heo was borrowed prior to that assimilation. In theory heo could have been borrowed into Jurchen when the Jurchen were under Parhae rule (698-926). Or it could have been borrowed from Khitan. (There's a possibility I've never seen raised before: how many Chinese loans in Jurchen had Khitan intermediaries? Cf. how early Chinese loans - 'Go-on' - in Japanese were probably borrowed from Paekche rather than directly from Chinese.)
But in any case, there would be no reason for the Jurchen to borrow what sounded like heo [xəw] to their ears as hao [χɑw] or hou [χou] (= Kiyose's hau/Jin's xao and Jin's xou).
Jin's reading xou sounds anachronistic, as it is a perfect match for modern standard Mandarin hóu [xow˧˥].
I cannot explain Kiyose's hau/Jin's xao, as there is
no extant evidence for reading 侯 as *xaw in the northeast (or
anywhere else) up into the Ming dynasty. The Chinese *-aw rhyme
category has a distinct history and is not confused with the *-əw
category in Manchu: *-aw corresponds to Manchu -oo and -ao,
whereas *-əw corresponds to Manchu -eo. I assume
Jurchen had the same pattern minus -oo (which is in borrowings
predating *-ao > -oo in Manchu; Manchu -ao
is in borrowings postdating *-ao > -oo).
If the Jurchen word for 'marquis' were hao, I would expect
that word to undergo monophthongization and become Manchu hoo
rather than the heo that is attested.
One could claim that Jurchen hao became extinct and that the word was reborrowed into Manchu as heo, but that still does not address the issue of why the Jurchen would borrow Chinese *xəw as hao [χɑw] instead of heo [xəw].
As tedious as this section may be, I think a lot of Jurchen character readings require this level of scrutiny and reevaluation.
2.11.20:31: Fortunately no arguments about Jurchen are likely to
revolve around a single transparent loanword from Chinese, so there is
little harm in reading the Jurchen character for 'marquis' as hao
or hou, etc. Nonetheless I still think there is a need to
reconsider even what may seem to be obvious in Jurchen reconstruction.
20.2.9.23:59: WHITE RAT 1.16
? qulugh ai nai sair par ? nyair
'white rat year, head month, ten six day'
1. Yesterday I was listening to the music of 岩 崎文紀. I initially misread his name as Iwasaki Fuminori. His name is actually Iwasaki Yasunori. I've never seen 文 read as yasu before.
2.10.22:51: The Japanese name element yasu means 'peace' and is most commonly written
安 <PEACEFUL>
康 <PEACEFUL>
靖 (prewar 靖) <PEACEFUL> (the Yasu- of 靖國神社 Yasukuni Shrine)
保 <SAFEGUARD>
which are the first four Windows IME suggestions that are used in names.
保 doesn't represent a Chinese morpheme for 'peace(ful)', so I was surprised back in 1991 when I learned that 藤堂明保 was read Tōdō Akiyasu. But I suppose 'peace' is the intended result of safeguarding.
It's taken me a couple of days to figure out why yasu would be spelled 文 <WRITING> which is normally read fumi 'writing' in names. 文 <WRITING> is associated with 文明 <WRITING BRIGHT> 'civilization', and civilizations are supposed to be peaceful without the strife of barbarism. But I really have no idea why the composer has that unusual reading.
Japanese name laws restrict the kanji used in baby names but have no
limits on how those kanji are read. dqname.jp
lists very unusual readings of baby names with legal kanji. Some 北斗の拳 Hokuto
no Ken fan (I'm guessing) named their son 北斗拳 Hotoke
<NORTH DIPPER FIST> (< Hokuto Ken)
which sounds like Hotoke 'Buddha'. The clipped readings ho
and ke for 北 hoku and 拳 ken are nonce
inventions.
A girl was named 帆都華 <SAIL CAPITAL FLOWER> Hotoke
and her twin was named 都萌 <CAPITAL MOE> Tomoe with moe. ho
and to are normal readings for 帆 and 都 which are not common
name characters. The reading ke for 華 is rare: the one example
that comes to mind is 法華經 Hokkekyō 'Dharma Flower Sutra' (i.e.,
the Lotus Sutra).
The creative use of kanji today may give insight into how Chinese
characters were used to write non-Chinese languages in the past: e.g.,
what logic led to the readings of Khitan and Jurchen characters.
2. Irish parliamentary elections were held yesterday. Why does Irish stáisiún vótála 'voting station' have ú [u] instead of o or ó [o]?
2.10.2:23: vótála is the genitive singular of vótáil 'voting' from vóta 'vote' plus the verbal noun suffix -áil.
-áil
also makes verbs out of nouns. Fun examples:
The Irish-language poet Cathal Ó Searcaigh in his poem
"Cainteoir Dúchais" (published 1997 in the collection“ Out in
the Open) uses the following verbs, most of them probably nonce
words:
hoovereáil ("to hoover")
jeyes-fluideáil ("to disinfect with Jeyes Fluid")
harpickeáil ("to clean with Harpic")
vimeáil ("to clean with Vim")
flasháil ("to clean with Flash")
windoleneáil ("to clean with Windolene")
eau-de-cologneáil ("to apply eau de Cologne to")
shagáilte ("shagged out")
cruiseáil ("to cruise")
I first learned of Harpic and used it when I lived in the UK. I might have seen Flash. I guess they're sold in Ireland too. I've never heard of Jeyes Fluid, Vim, or Windolene.
2.10.23:39: Wiktionary derives vóta from
Latin vótum. But I thought v was only in modern
loanwords (there was no v in the
premodern Irish alphabet), so I had guessed that the word was
borrowed through English
rather than directly from Latin. How old are words like Vailintín
'Valentine' and Vulgáid
'Vulgate'? Are those modern respellings of old loans?
3. What should the virus in the news be called?
2.10.2:25: I've been thinking of it as the 'coronavirus', but it is just a coronavirus:
Coronavirus is the umbrella term for a large group of viruses, including ones that can cause the common cold.
Toyota was fortunate to have retired the Corona model name almost twenty years ago.










{kind=link}
{kind=link}
{kind=link}