




? qulugh ai nai sair nyêm nyair
? qulugh ai nai sair nyêm nyair
'white rat year, head month, eight day'
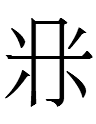
1. The Khitan large script graph
<EIGHT>
is more complex than Chinese 八 <EIGHT>. Could the Khitan graph have originated as a logograph for a non-Khitan word *nyêm in an earlier (Parhae?) script that was recycled for a (nearly) homophonous, unrelated Khitan word for 'eight'?
I discuss the reconstruction of Khitan 'eight' here.
Jurchen <EIGHT> does not appear to be graphically cognate to Khitan <EIGHT>, though it might be derived from Jurchen <SEVEN>:
<
?
2. I just heard "Їдемо" by Хочу ЩЕ! on the radio. Its cover might lead some to think the song title was "Їдемо Україна/Yidemo Ukraine". Note how "Україна" is translated as "Ukraine" rather than transliterated as "Ukrayina".
Oddly when I searched for that cover, Google automatically switched to Russian even though I had input a string ("Їдемо Україна") with the Ukrainian letter Ї absent from Russian.
Is Їдемо with Ї- a dialectal form preserving the initial of Proto-Slavic *jĭdemŭ? The standard Ukrainian form is ідемо with i- like most Slavic languages.
An exception is Lower Sorbian źomy in which the initial vowel has been lost. And although that vowel is retained in the infinitive hyś, Wiktionary says that's pronounced ... [ɨɕ]!
-мо for the first person plural jumps out at me as a Ukrainian form,
though I learned from De Bray (1980: ???) that -мо still marginally
exists in Belarusian дамо
'we give' and ямо 'we eat' (but Wiktionary
only lists ядзім with the regular -м ending).
-мо is also in Slovenian and Serbo-Croatian which do not subgroup with Ukrainian. It seems *-mŭ strengthened to -mo twice: at least once in the south (Slovenian and Serbo-Croatian) and once in the east (Ukrainian and Belarusian).
De Bray (1980: ???) also lists as a Ukrainian first person plural
ending, though he gives no details on when to use it, and Wikipedia
doesn't mention it.
ЩЕ [ʃtʃɛ] in the group name is closer to the second syllable of Proto-Slavic *ešče than the second syllable of Russian ещё [(j)ɪˈɕːɵ].
3. The last time I listened to a lot of Ukrainian pop music was
eight years ago. Back then a lot of it was sung in Russian. Not
anymore. Every song I've heard lately is in Ukrainian. So I was
surprised to see a
Ukrainian album with a Russian title and some Russian songs:
Anna-Maria's Разные (Various).
4. Tonight I saw a TV report on a Hawaiian language celebration at Windward Mall.
5. While looking for an online reference to that event, I found this almost two weeks late:
Starting Wednesday, the University of Hawaii will offer free Hawaiian language courses to the public.
20.1.31.22:22: WHITE RAT 1.7
? qulugh ai nai sair ? nyair
'white rat year, head month, seven day'
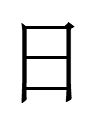
1. The Khitan large script graph
<SEVEN>
is much more complex than Chinese 七 <SEVEN>. It just occurred to me that the former might have originated as a logograph for a non-Khitan word (*dalo or *dalu?¹) in an earlier (Parhae?) script that was recycled for a (nearly) homophonous, unrelated Khitan word for 'seven'.
Sometimes Khitan and Jurchen large script characters are graphic cognates, but not in this case - Jurchen <SEVEN> is simpler (yet still different from Chinese 七 <SEVEN>):
Maybe the Jurchen character is a recycling of a logograph for a non-Jurchen word *nadan in an earlier (Parhae?) script that was recycled for a (nearly) homophonous, unrelated Jurchen word nadan 'seven'.
¹These guesses for 'seven' are based on Kane (2009) and Shimunek's (2017) interpretations of
<da.313>
the stem of 'seventh' (not 'seven'!).
The phonetic value of 313 is uncertain. I am unaware of any alternations between 313 and, say,
<l.o> or <l.u>.
And I am also unaware of 313 (or any other small script character or
character sequence) transcribing Liao Chinese *lo or *lu.
Kane and Shimunek's interpretations are based on an assumption that <da.313> corresponds to the dolo- of Written Mongol dologhan 'seven'. (The suffix -ghan is a Mongolic innovation absent in Khitan.)
I feel uneasy about writing dologhan, for as Janhunen (2003: 34) points out,
Since Written Mongol is basically a non-spoken language transmitted with the help of an abstract graphic code, it has strictly speaking no 'phonology' or 'pronunciation', though many Written Mongol grammars misleadingly include sections on such topics.
There are, however, conventions for pronouncing it, or else I
wouldn't have been able to read it out loud for my Written Mongol class
in graduate school. There is no consensus on how to pronounce it: e.g.,
Grønbech (the textbook I used long ago) reads ᠳᠣᠯᠣᠭᠠᠨ 'seven' as dologhan
whereas Lessing reads it as dolughan. The spelling is
ambiguous: the fourth letter could represent o or u.
Janhunen works around the problem with a strict transliteration ignoring those conventions: e.g., tuluqhav 'seven'. I confess that I am not comfortable with his system and that I have yet to work out an alternative of my own. Off the top of my head, I could transliterate the Written Mongol spelling of 'seven' as <TUlUghan>, using uppercase to indicate ambiguities:
<T> could represent either /t/ or /d/
<U> could represent either /u/ or /o/
<l>, <gh>, <a>, and <n> are unambiguous and hence in lowercase.
Modern forms clearly point to do- for the first syllable but
do not unambiguously point to o or u, as their second
vowels could be contractions of ogha or ugha:
Khalkha, Buryat doloon
Kalmuk dolan
Baoan dolong
Dagur, Monguor dolōn
Dongxiang dolon
I got those forms from Sanzheev, et al. (2015-2018), Этимологический
словарь монгольских языков (An Etymological Dictionary of the Mongolic
Languages) legally available for free on the site of the Institute of Oriental
Studies of the Russian Academy of Sciences: vol.
1 / vol. 2
/ vol. 3.
Sun's (1990) Mongolic comparative dictionary provides even more
forms, but again none point decisively to o or u.
I favor dologhan on the basis of Phags-pa Mongol ꡊꡡ
ꡙꡡ ꡖꡋ <do lo 'an>.
2. Last night I learned about a manga called 緋の稜線 Hi no ryōsen
(The Scarlet Ridge). The Sino-Japanese word 稜線 ryōsen
'ridge' can be mechanically translated into Sino-Korean as 능선 nŭngsŏn
or into the Sino-Korean-native hybrid 산등성이 sandŭngsŏngi. 산
san is Sino-Korean 'mountain', and 등 tŭng is the native
word 'back', but what is the native final element -sŏngi?
3. Last night I compiled this table of the distribution of Tangut Grade II tense vowel rhymes:
| grade\vowel |
uq |
iq |
aq |
yq |
eq |
enq |
oq |
| I |
✓ |
✓ |
✓ |
✓ |
✕ |
✕ |
✓ |
| II |
✕ |
✓ |
✕ |
✕ |
✓ |
✓ |
✓ |
| III |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
| IV |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
Last night, I proposed that *-aq2 merged with *-aq1. Perhaps there were similar mergers of
*-uq2 and *-uq1
*-yq2 and *-yq1
*-iq1 and *-iq2 or
*-oq1 and *-oq2?
{u, a, y} do not form a natural class contrasting with {i,
o}.
Why don't -eq1 and -enq1 exist? Did Grade I and II *-e(n)q rhymes merge in the opposite direction as some of the other vowels, and if so, why?
Why is enq the only possible tense nasal vowel? Is that an
error in my transcription system? I would expect inq, anq, and onq
as well, but they don't exist (anymore?). (-un is only in
Chinese loanwords which wouldn't have tense vowels, and there is no -yn.)
4. After over a quarter century of interest in Vietnam, I somehow never heard of the San Diu or Ngái peoples until last night. How do they differ from the Chinese?
5. Last night I wrote about the second
half of 鍋奉行 nabebugyō
'person who tries to control every step of the process when a group
cooks hot pot at the table'. Now a few words about the first half. Wiktionary gives this
etymology:
Originally a compound of Old Japanese elements 肴 (na, 'small snack, hors d'oeuvre') + 瓮 (he, 'a pot or pan for holding food or beverages'). The he changes to be as an instance of rendaku (連濁).
Janhunen would like that etymology. He thinks Japonic originally had
lots of monosyllabic roots before being reshaped to look 'Altaic'.
2.1.23:21: Despite the fact that the word nabe is attested in Old Japanese (as 名倍 nambəy [Man'yōshū 3824] < *na-nə-pai; *pai may be *pa-i, but I don't know of any cases of a root *pa without *-i) and not in Korean until modern times, I was surprised to see Martin (1987: 490) write, "Borrowed from/into Korean nampi?" Wiktionary says the word appears in Korean as 남비 nambi /nampi/ in 1938. That is the only form in Martin et al.'s (1967: 308) dictionary. The current form (standardized in 1988 according to Wiktionary) is냄비 naembi /nɛmpi/ with fronting of the first vowel to assimilate to the secnd.
I was also surprised to see Martin (1987: 403) quoting Ōno's
proposal of a possible derivation of he 'pot or pan for food or
beverages' from Korean pyŏng 'bottle' - which is an unrelated
borrowing from Chinese 瓶.
6. Jacques (2014: 2) regards Pumi as the closest relative of Tangut. Here is a set of correspondences that puzzle me:
| gloss |
Pumi |
Tangut |
pre-Tangut |
Proto-rGyalrong |
Written Tibetan |
|||||
| Qinghua |
Lanping |
Jiulong |
Taoba |
Wadu |
tangraph |
reading |
||||
| four |
ʒɛ⁵⁵ |
ʒɛ⁵⁵ | ʒə¹¹ (lĩ⁵⁵) |
ʐɐ⁵⁵ |
ʐɐ̂ | 𗥃 |
1lyr'3 |
*rliX |
*k.pli |
bzhi |
| two |
ni¹³ |
ni¹³ | nɯ¹¹ (lĩ⁵⁵) |
nə³⁵ |
nǒŋ < *nǐ-jôŋ |
𗍫 | 1ny'4 |
*niX |
*k.nis |
gnyis |
| day |
n̥i⁵⁵ |
n̥i⁵⁵ | ȵĩ⁵⁵ tio⁵⁵ |
n̥ə⁵⁵ |
n̥ôŋ |
𗾞 | 2ny'4 |
*niXH |
*t.ʃni |
nyi-ma 'sun' |
| person |
mi⁵⁵ |
mi⁵⁵ | mi³⁵ |
mə⁵³ |
mə̂ ~ m̥ə̂ |
𗼎 | 2mi4 (1st syl. of 'Tangut') |
*miH |
*t.mi |
mi |
| fire |
mɐ¹³ |
mɐ⁵⁵ |
mɐ³⁵ |
mɐ³⁵ |
mɐ̌ |
𗜐 | 1my'1 |
*CAmiX |
*t.mi |
me |
Sources:
Qinghua Pumi: Sun (1991) at STEDT
Lanping Pumi: Huang (1992) at STEDT
Jiulong Pumi: Huang (1992) at STEDT
Wadu Pumi: Daudey (2014)
Proto-rGyalrong: Hsiu (2020)
Proto-rGyalrong is a very conservative Sino-Tibetan language. Nonetheless the multiple correspondences of Proto-rGyalrong *i may indicate that its vocalism is simpler than that of the proto-language.
2.1.14:42: I used to think 𗇋 2mer4
< *RImejH 'person' was related to mi-words for
'person', and maybe it contains the same root, but its proto-vowel is
not *i. So I've replaced it with 𗼎
2my4 < *2miH, the first syllable of 𗼎𗾧 2my4 2na'4 'Tangut' < 'person
black'.
7. Tonight for dinner I ate
牡蠣蕎麥
<MALE OYSTER BUCKWHEAT WHEAT>
kaki soba 'oyster buckwheat noodles'
an example of the loose matching between Japanese spelling and Japanese words. kaki 'oyster' and soba 'buckwheat noodles' are both monomorphemic, yet they are each written with two kanji. 牡蠣 has as much to do with kaki as it does with the English word oyster: almost nothing.
The Chinese word 牡蠣 (Mandarin mǔ lì) may have originated as
an attempt to write a conservative sesquisyllabic form for 'oyster'
like Old Chinese 蠣 *mIrats in a period when a monosyllabic *m-less
pronunciation of 蠣 was favored.
*mI- is an animal prefix that probably has nothing to do
with the Old Chinese word *CAm(r)uʔ or *mAruʔ
'male (of animals)' written as 牡. But the animal association of
the original referent of 牡 could have made it a favorable
candidate for writing an animal name.
Could the unidentified minor syllable high vowel *I of *mIrats be *u as in 牡 *CAm(r)uʔ or *mAruʔ?
蕎麥 is a semiredundant compound: 麥 alone is 'wheat' and 蕎 is a kind of wheat. Neither half indicates noodles. The Japanese word 蕎麥 soba can refer to the buckwheat plant, and the spelling 蕎 麥 was used without augmentation for noodles made of buckwheat. In theory a silent <NOODLES> could have been added to indicate when soba refers to noodles: 蕎麥麵 soba (noodles) vs. 蕎麥 soba (the plant).
2.1.14:55: Incredibly the earliest attestation of 牡蠣 I could find at
Scripta Sinica
was in 世宗實錄 Sejong shillok (Veritable
Records of Sejong,
1454). That may simply reflect how 'mussel' isn't the sort of word that
would tend to appear in the genres of the Scripta Sinica corpus. I
doubt牡蠣 was coined in 15th century Korea and thereafter somehow crossed
the sea to be adopted as the spelling of Japanese kaki. The
word must have been around in East Asia before then.
8. I recently noticed Korean in the opening title of The King of Queens but couldn't read it until I took a screenshot tonight:
참피온 탁구장
chhamphion thakkujang
'Champion Table Tennis Facility'
That turns out to be a
real business in New York City.
9. Ortodokse or Orthodhokse? The seal of the Orthodox Church of Albania has a Greek-influenced version of its Albanian name with fricatives instead of stops.
10. I've known about Dazai Osamu's Hashire! Merosu (Run, Melos!) for a long time but never saw it until tonight. It's so short!
11. I've long thought South Park would be hard to translate into Japanese. The Japanese episode titles are not much like the originals.
12. I heard "Bringing
in the Sheaves" on Two and a Half Men and had to look up sheaves.
20.1.30.23:59: WHITE RAT 1.6
? qulugh ai nai sair ? nyair
'white rat year, head month, ? day'
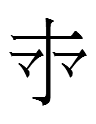
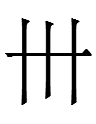
1. The Khitan large script has at least nine variants of <SIX>:
I don't know which one(s), if any, are considered 'correct'. Such an extreme degree of variation may imply that Janhunen (1994: 111) was right about the Khitan large script having a history.
I have followed Andrew West in choosing what I'll call the 'fuma'
variant (because it contains lookalikes of the katakana フ fu
and マ ma). I rely on his
calendar for Khitan and Jurchen dates.
2. I've never seen what I assume to be an Italian verb embedded like this in English before (emphasis mine).
I remained folgorated by the sounds and the melodies of Giombini
Was the interview in English, or is the word an artifact of machine
translation into English?
3. The Honolulu Star-Advertiser features a Japanese word once a week. This week's word was 鍋奉行 nabebugyō 'person who tries to control every step of the process when a group cooks hot pot at the table'. It is literally 'pot magistrate'; a bugyō "was a title assigned to samurai officials of the Tokugawa government in feudal Japan".
奉行 <RECEIVE EXECUTE> is an ambiguous spelling: it can either be read using later stratum (Kan-on) readings as hōkō 'receiving and executing a lord's orders' or using earlier stratum (Go-on) readings as bugyō 'magistrate' (i.e., someone who receives and executes a lord's orders).
I think 奉行 is the only common word in which 奉 is read bu. 奉 is read hō in almost all other Sino-Japanese compounds except the Go-on compound 供奉 gubu 'accompany as an attendant; court monk', a word not in Windows 10's IME.
1.31.1:00: 供奉 can also be read as a Kan-on compound kyōhō
'supply; accompany as an attendant'. Typing kyōhō
in Windows 10's IME also doesn't produce 供奉, so I use the Mandarin IME
to write it. I've been typing Chinese characters on computers for 25
years now, and it never gets any easier.
4. The Honolulu Star-Advertiser today says singer Olivia Thai "spoke three Chinese dialects until learning English in school". I'm guessing the three are Mandarin and her parents' native languages which aren't Mandarin.
1.31.0:16: IMDb says "her parents were born and raised in Vietnam". Five major types of Chinese are spoken in Vietnam: Cantonese, Hakka, Teochew (Chaozhou), Hoklo (Hokkien), and Hainanese. The last three are forms of Southern Min.
The Vietnamese Th- spelling for [tʰ] in her name should have
made me guess her family had lived in Vietnam.
5. Looking at Xinlong Queyu ʂqa¹³ rdə⁵⁵
'ten' made me realize my belief that pre-Tangut uvulars conditioned
Grade II might be wrong. The Tangut word for 'ten' is
1084 2ghaq1
which is Grade I, not II, even though its pre-Tangut ancestor presumably had *q like its distant relative Xinlong Queyu.
Maybe my belief isn't entirely wrong. There is no Tangut rhyme *-aq2: i.e., a Grade II tense vowel. So I propose this backstory for 'ten':
*SVqa > *SVʁa > *Sʁa > *ʁʁa > *ʁʁaq > *ʁaq > *ʁaq2 > *ghaq2 > ghaq1
I've excluded the tone 1- since I don't know when it developed.
The story in words:
*-q- lenited to *-ʁ-. The minor syllable was
reduced to *S- which assimilated to *ʁ-, resulting in a
tense consonant *ʁʁ- (cf. tense hh-
in Middle Korean; the doubling is a convention I've borrowed from the
conventional way Korean tense consonants are romanized). The tension of
this consonant spread into the vowel, and I write that tension as -q.
The tension in the vowel became phonemic after tense *ʁʁ-
became regular *ʁ-. Uvular-initial words with lower vowels like
*a developed Grade II. Uvular *ʁ- merged with velar *gh-,
so the grade was no longer predictable. Finally, *-aq2 merged
with *-aq1, leaving a gap in the rhyme system.
6. After over three decades I finally saw the lyrics of Falco's "Der Kommissar". The English sprinkled in it jumps out at me.
7. Tonight I found Suzuki Hiroyuki and Sonam Wangmo's "Lhagang Choyu Wordlist with the Thamkhas Dialect of Minyag Rabgang Khams (Lhagang, Dartsendo)" (2018) via the Wikipedia article on Choyu (Queyu). Here are examples of uvulars corresponding to Tangut Grade II:
*C- is not *S- which would have left a trace as
vowel tension (-q in my transcription system)
Tangut gh- was lenited in intervocalic position between the vowel of a lost minor syllable *CV- and the vowel of the major syllable (which may or may not have raised to -u at the time)
'bitter': Thamkhas qʰa mu : Tangut 4046 1khi2 < *qʰa
I have omitted tones.
Normally Tangut Grade II derives from medial *-r- in forms with lower series vowels like *a, but there is no *-r- in the cognates of those words. Compare:
*CA > CV1 (*C = nonuvular, *A = lower
series vowel)
*QA > CV2 (*Q = uvular)
*CVQV > CV2 (*C = not *S-)
8. New word for today: anosmia (found
after looking up Zicam
which was advertised on TV tonight).
20.1.29.22:22: WHITE RAT 1.5
? qulugh ai nai sair tau nyair
'white rat year, head month, five day'
1. Khitan large script <FOUR> doesn't look like Chinese <FOUR>, but Khitan large script <FIVE> does look like Chinese <FIVE>. Its phonetic value, however, is completely different: tau rather than ngu as in Liao Chinese.
Liao Chinese 五 *ngu 'five' is transcribed in the Khitan large script as 吾 ngu, a lookalike and soundalike of Liao Chinese 吾 *ngu 'I'. That usage of 吾 to write ngu may be a Khitan innovation, as 吾 was pronounced *ngo in the Middle Chinese known to users of predecessor scripts (Serbi and Parhae) in centuries past.
A typology of Khitan and Jurchen large script characters:
| Type |
Does the character resemble a Chinese
character? |
Does the character have a Chinese-like
reading? |
What kind of Chinese does the reading
resemble? |
Probable source of character |
Do the Khitan/Jurchen and Chinese characters
represent semantic equivalents? |
| A |
yes |
yes |
Liao or Jin Chinese |
Khitan or Jurchen Empire |
no |
| B |
Middle Chinese |
Parhae |
|||
| C |
Late Old Chinese |
Serbi |
|||
| D |
no |
none |
Khitan or Jurchen Empire |
yes |
|
| E |
Parhae or Serbi |
no |
|||
| F | no |
N/A |
N/A |
Parhae or Serbi |
N/A |
Examples of each type:
A. Khitan large script phonogram 吾 ngu < Liao Chinese 吾 *ngu
(rather than Middle Chinese *ngo or Late Old Chinese *nga)
B. Khitan large script phonogram 何 ha < Late Middle Chinese 吾 *ha (rather than Liao Chinese *ho)
C. Jurchen large script phonogram
<gai> [kaj]
< Late Old Chinese 可 *kʰajʔ (rather than Jin Chinese *ko
[kʰɔ])
D. The Khitan large script phonogram 五 tau originated as a logogram for tau 'five' (which means the same thing as Liao Chinese 五 *ngu) and was then used to write any tau in the language. This exact usage cannot be a carryover from the Parhae script for some non-Khitan (Tungusic? Koreanic? Japonic?) language, since such a language wouldn't have a word like tau for 'five'. However, the general idea of using a character to write a non-Chinese word and all syllables sounding like that word is a carryover from the Parhae script.
If the Serbi word for 'five' was tau (as opposed to a more
Mongolic-like *tabu) centuries ago when the lost Serbi
script was in use, it is possible that 五 with the phonetic value tau
is a carryover from the Serbi script. But I don't know whether *-b-
was lost in 5th century Serbi - or even what the Serbi word for 'five'
was. (Khitan and Mongolic mismatches in numerical words do not make me
optimistic about guessing Serbi words on the basis of Khitan and
Mongolic.)
E. The Jurchen large script phonogram
resembling Jin Chinese 不 *bu 'not' may be a derivative of 不
originally for a Parhae Koreanic cognate of Middle Korean ani
'not'. The character has nothing to do with negation in Jurchen; it is
solely used to write Jurchen [an].
F. Khitan and Jurchen large script characters such as
Khitan <ai> and Jurchen <aniya> 'year'
that bear no resemblance to Chinese characters may be inherited
from the Serbi and/or Parhae scripts rather than invented on the spot
in the 10th and 11th centuries respectively. In Janhunen's scenario as
I understand it, these characters are products of one or more alternate
lines of evolution instead of conscious Khitan and Jurchen creations.
2. Last night I realized that Jurchen
<ge> /kə/
looked and sounded like the Old Japanese phonogram 居 kə (an
adapation of Middle Chinese 居 kɨə 'dwell'). Cursive forms of
居 resemble Jurchen <ge>: the bottom component 古 is
abbreviated into a shape close to 土.
The dot in the Jurchen form may indicate the omission of strokes in a
cursive form (see Grinstead 1972: 58 on this practice in Chinese
calligraphy). Is <ge> a type B character reflecting Middle
Chinese pronunciation?
<ge> corresponds to 厄 *ə in Ming Mandarin transcription after voiced segments. Maybe it was phonetically [ɣə] after voiced segments. (Cf. *k-lenition to [ɣ] in Middle Korean to the south of the Jurchen-speaking area.)
I would predict that <ge> was [kə] in initial position, but in
the one text where it occurs in that position (Memorial XX; Kiyose
[1977: 190]), it corresponds to Ming Mandarin 額 *ə. That might
be a mistake by analogy with the reading of <ge> in other
positions where it is more common.
Kiyose's transcription <ge> seems motivated by historical and comparative considerations rather than Jurchen synchronic phonetics. <ge> sometimes corresponds to standard Manchu ge: e.g.,
'husband':
<ei.ge> : Manchu eigen (Translators 292)
But note Translators 137:
'camel':
3. I'm still reading William C. Hannas' The
Writing on the Wall: How Asian Orthography Curbs Creativity
(2003). On page 230 is a great self-referential typo: psuedowords!
4. I was puzzled by -t in Tshobdun rGyalrong kə'ŋɢət 'nine' since other Sino-Tibetan languages lack it: e.g.,
Old Chinese 九 *[k]uʔ
Old Tibetan dgu
Old Burmese kuiv· [kə̤w] (the breathiness is not
indicated in the script)
Pyu tko
But Jacques (2009: 158) explains that the -t of the Japhug cognate kɯngɯt 'nine' is by analogy with the adjacent numeral kɯrcat 'eight'. Similarly, -t must have spread from 'eight' to 'nine' in Tshobdun. I should have figured that out.
Strictly speaking, could the spread have occurred in a common ancestor of Japhug and Tshobdun? Hsiu (2020) subgroups Japhug and Tshobdun together with 'rGyalrong proper' in 'Core rGyalrong':
| rGyalrong | ||||
| Zbu |
Core rGyalrong |
|||
| Japhug |
Tshobdun |
rGyalrong proper |
||
| Southeastern | Situ |
|||
The five branches correspond to Gates' (2012) five languages (except
that Gates uses the term 'South-central' instead of 'Southeastern').
It just occurred to me that the spread could have occurred in Tangut. But Tangut 1gy'4 'nine' cannot be from *ŋgu(t)X which would have become ˟1gwy'4 with a -w- absent from the actual word for 'nine'. However, Tangut 1gy'4 'nine' could be from *ŋgotX. Perhaps Proto-Sino-Tibetan *-əw became
Old Chinese *-u
Old Tibetan -u
Old Burmese -uiv· [əw]
Pyu -o
The trouble is that Hill (2019: 272) has established that the Old
Chinese reflex of Proto-Sino-Tibetan *-əw is *-o, not *-u.
I could try to work around this problem:
The Old Chinese initial is uncertain - it is back, unaspirated, and voiceless, but it could be *k, *kʷ, *CVq, or *CVqʷ. The fact that 九 *[k]uʔ <NINE> is phonetic in 軌 *kʷruʔ <CHARIOT.NINE> 'wheel rut' leads me to think the initial could have been *kʷ-. If so, perhaps
*kəw > *ko
but *kʷəw > *ku
Another possibility is that the vowel of a lost minor syllable
(corresponding to Tshobdun kə- or Pyu t-?) conditioned *-əw
to become *-u rather than the default *-o.
In any case, Pyu and perhaps pre-Tangut upset an otherwise neat pattern. Pyu and pre-Tangut do not subgroup together, so their mid vowels are not shared innovations.
Comparative Sino-Tibetan is still in its infancy. The stories of even basic words like 'nine' are still largely unknown. I have concentrated on the problem of reconstructing its vocalism, but there are other issues as well: e.g., Chinese and Pyu point to a voiceless consonant, whereas the other languages point to a voiced consonant. (Old Burmese k- is from *g-.) I don't know how to reconcile the evidence for *k-type initials with the evidence for *g-type initials.
5. Another numerical puzzle: Hsiu's (2020) Proto-rGyalrong *t.gu 'two' looks like Tibetan dgu 'nine' (and in fact I typed 'nine' after *t.gu by reflex at first). I've never seen anything like *t.gu before. It would be nice if *t.gu matched the mysterious 'other' words for 'two' in Tangut, but no:
𘙇𘂚 0795 5855 2ryr4 2loq
'second (month)'
𘂈 5914 2loq1 'second (son)'
See Andrew West's 2011 article for more on the 'other' Tangut numerals.
The characters for the root loq 'two' contain the left and right sides of the character for the normal word for 'two'
𗍫
1ny'4 (cognate to the other Proto-rGyalrong word for 'two', the pan-Sino-Tibetan word *k.nis)
which has long reminded me of a mirror-image version of the complex Chinese character for 'two', 貳.
6. I had forgotten that I had bookmarked Wang Feng's "Language Diversity and Human Diversity in Yunnan". I accidentally clicked on the bookmark today at lunch.
Slide 9: The complexity of the Bai script with its many semantic-phonetic compounds contrasts with the relative simplicity of the Khitan and Jurchen large scripts which do not seem to have any such compounds.
Slide 19: Wang's view of Bai as a sister of Chinese reminds me of Starostin's proposal that Bai is an offshoot of Chinese. But to me Bai has always seemed too different to be closely related to Chinese.
Slide 20: The shared Bai/Chinese sound changes that Wang proposes
could simply reflect Chinese sound changes in Chinese loanwords in Bai.
I would like to see these sound changes in probable native Bai words:
i.e., Bai words without Chinese cognates. ("Probable" because those
words could be borrowings from non-Chinese sourcces.)
Slide 25: The mismatches between the early Chinese transcription of Bai and Proto-Bai may suggest that the latter postdates the former: i.e., that Proto-Bai underwent sound changes not yet reflected in the transcription.
Slide 27: The comparison of Proto-Bai *dro4 and Chinese 石 'stone' has bothered me because Proto-Bai has a *-r- absent from Chinese. I reconstruct 石 in Old Chinese as *CiTak. There has to be an *i in the minor syllable to condition *-i- in Middle Chinese:
*CiTak > *diak > *dʑiak > *dʑiek
The theoretical Go-on reading of 石 should be jaku (from *dʑiak)
but the actual reading is shaku. Perhaps shaku
is from a *tɕiak that lost a minor syllable *Ni-:
*Nitak > *Nitiak > *tiak > *tɕiak
(in other dialects: *Nitiak > *Ntiak > *ndiak > *diak > *dʑiak)
But here's another scenario:
*Ridiak > *rdiak > *driak > Proto-Bai *dro4
Schuessler (2007) compared the Chinese word to Vietic, and indeed my *Ridiak does superficially resemble Vietic forms like Ruc latáː 'stone' (Nguyễn Phú Phong et al. 1998). The Ruc tone goes back to *-ʔ which isn't far from *-k. But I think the Chinese and Vietic forms are unrelated lookalikes, as the match is weak:
the minor syllable vowels don't match
the major syllable onsets differ in voicing
the codas don't match
I also considered the Chinese and Bai forms to be lookalikes too, but given that the early transcription of Bai 'tiger' reflects a pre-Proto-Bai *la1 corresponding to Proto-Bai *lo1 (slide 25), maybe 'stone' was borrowed as pre-Proto-Bai *rdak or *drak which became *dro4 in Proto-Bai.
Slide 27 (again): Wang regards Proto-Bai *the4 'iron' as being from "[t]he oldest layer" of Chinese loanwords. That layer cannot be very old, as *the4 resembles Late Old Chinese 鐵 *tʰet and not Early Old Chinese *HAlik or *CAl̥ik.
Bridging the Early and Late Old Chinese forms (the relative chronology is not entirely clear):Secondary *l̥-scenario:
*HAlik > *HAlit > *HAlait > *Hlait > *l̥ait > *tʰait > *tʰeit > *tʰet
*H could have been *k: cf. Ruc klát 'iron', another version of this word which seems areal
Primary *l̥-scenario:
*CAl̥ik > *CAl̥it > *CAl̥ait > *l̥ait > *tʰait > *tʰeit > *tʰet
I favor the secondary scenario, as I'd like to think that all Old
Chinese voiceless sonorants are ultimately compressions of earlier *CVC-sequences.
20.1.28.23:29: WHITE RAT 1.4
? qulugh ai nai sair ? nyair
'white rat year, head month, four day'
1. I have not commented on the Khitan large script characters 一二三 <ONE TWO THREE> which are self-explanatory and identical to Chinese 一二三 <ONE TWO THREE>. One might expect Khitan <FOUR> to look like Chinese 四 <FOUR>, but Khitan breaks the pattern with a near-lookalike of Chinese 卅 <THIRTY> (< <TEN> x 3).
The Khitan character has four lines and looks like a tally mark.
There is a tally mark-style variant of Chinese <FOUR>, but it
is a stack of two <TWO> rather than a line with three
intersecting lines: 亖.
I just realized Jurchen <FOUR> also has four lines, albeit in
yet another configuration:
What I call Janhunen's question applies here:
If it was the aim to create a [Khitan] script distinct from the Chinese, why were not all [Khitan large script] characters consistently replaced or modified? (Janhunen 1994: 111)
Why create a new character for <FOUR> but not <ONE>, <TWO>, or <THREE>?
Janhunen's question also applies to the Jurchen (large) script: if it was the aim to create a Jurchen script distinct from both Chinese and Khitan, why carry over一二 <ONE TWO> into Jurchen while only adding a stroke to 三 <THREE> and coming up with a new character for <FOUR>?
I like what I'll call Janhunen's solution: the Khitan and
Jurchen large scripts are both offshots of an earlier script or scripts
that in turn are sisters of the standard Chinese script rather than
deliberately engineered deviations from it. Perhaps Khitan large script
<FOUR> is derived from the lost Serbi character for <FOUR>,
whereas Jurchen <FOUR> is derived froma Parhae character for
<FOUR>.
2. Shimunek (2017: 233) reads <FOUR> as dur or tur, assuming that it shares the same root as the ordinal numeral d/turər (m.) ~ d/turən (f.) 'fourth'. But I fear that 'four' may be to 'fourth' what English two is to second: i.e., not related.
Khitan 'fourth' is what I call an alternator: its initial consonant is spelled both <t> and <d>. The Mongolic side of Serbi-Mongolic has d- for 'four'. Is the Khitan initial /t/ or /d/ with allophony, or is it a third consonant without a character of its own? Perhaps:
| phoneme |
Khitan small script spelling |
| /tʰ/ |
<t> |
| /d/ |
<d> |
| /t/ |
<t> ~ <d> |
Mongolic may have merged Proto-Serbi-Mongolic *t and *d into d, reducing a three-way opposition to two: d /t/ vs. t /tʰ/.
Shimunek's tur ~ dur is another example of the vowel merger that he proposed. Mongolic preserves the original vocalic distinction between 'three' and 'four':
| gloss |
Proto-Serbi-Mongolic |
Khitan |
Written Mongol |
| three |
*gu-r [ɢʊr] |
[ɢur] | ghurban |
| four |
*tö-r [tor] |
[tur] |
dörben |
Maybe Khitan 'three' was [ɢʊr] with a [ʊ] that had been demoted to
an allophone of /u/ after uvulars unlike Proto-Serbi-Mongolic /ʊ/ which
contrasted with /u/. Some sample syllables:
| Proto-Serbi-Mongolic |
Khitan |
Written Mongol |
| *gu [ɢʊ] |
/ɢu/ [ɢʊ] | ghu |
| *gü [gu] |
/gu/ [gu] |
gü |
| *tu [tʊ] | /tu/ [tu] |
du |
| *tü [tu] |
/tu/ [tu] |
dü |
Uvulars which were allophones of velars before low series vowels in
Proto-Serbi-Mongolic became phonemic in Khitan.
3. Khitan small script character 057 from yesterday's post belongs
to a 'family' of characters that may not have any phonetic common
denominator:
<054 055 056 057 058 059 388>
The readings of 054, 055, 056 (a variant of 055?), 058, and 388 are unknown. I don't know why Kane assigns the mnemonic transliteration (not a reading!) mỉ to 058 which doesn't resemble any Chinese character pronounced mi. (Some mnemonic transliterations are based on graphic resemblances to unrelated Chinese characters.)
057 is <ho> and 059 is <uni>.
One frustrating thing about the Khitan small script is that
similar-looking characters like these seem to have the same graphic
elements for no reason. A Khitan might say the same thing about the
Latin letters E and F. Or P and R. (Of course some resemblances are
significant: e.g., C and G, I and J, U, V, and W.)
Khitan small script character numbers 001-378 from Chinggeltei et al. (1985) are widely used (though not universal). The numbering after that varies by scholar. I follow Wu and Janhunen's (2010) numbering which builds upon Kane's (2009) additions and has more numbers than anyone else's (459)¹. Kane assigned 379 and 380 to
<TENT> and <FORTUNE>
which Chinggeltei et al. (1985) regarded as
a variant of 081 and a block <335.277>.
I wrote a five-part series on 380
<FORTUNE> and its variants last year. I accept Kane's
interpretation of those characters.
Wu and Janhunen (2010) assigned the next available number (381) to
which corresonds to 379 in Chinggeltei (2010). Chinggeltei regards Kane's 379 as his 386 and does not assign a number to 380 (perhaps because he still regards it as a block of two characters).
¹One might think that Wu and Janhunen's (2010) list of 459 Khitan small script characters is complete, but there are at least 472 characters, and I don't know what I'm going to do about numbering the 13 characters not inWu and Janhunen (2010).
All numbering systems for Khitan small script characters are arbitrary, but one is necessary because I need some way to refer to characters whose pronunciation is unknown without resorting to images. And I have switched to naming my images by numbers.
You can tell which images are old by their names. The earliest images are named using Kane's transcription system. So the image for 057 is called "BabelStone-small-xo.gif" rather than "BabelStone-small-057.gif" because it dates before the change in April 2014.
²Wu and Janhunen (2010) transliterate
381
as hong˟, but that does not mean 381 was necessarily read hong; the diacritic ˟ merely indicates a graphic resemblance to
075
which Wu and Janhunen (2010) read as hong. 381 and 075 could have readings as different as
057 ho and 059 uni.
Wu and Janhunen (2010: 43) list six cases of their use of the diacritic ˟ but exclude 381 hong˟.
I think the post-380 characters either represent rare syllables or
are logograms for words that are not common in the known corpus (though
they might have been common in everyday speech). Wu and Janhunen (2010:
40-41) identify twenty single-consonant characters. That may be a
complete or nearly complete list. I would be surprised if there are
more than a couple of single-consonant characters that have not been
identified yet.
4. Last night I guessed that the Korean equivalent of Japanese 戰慄 senritsu 'shudder' would be 전률 <ch.ŏ.n r.yu.r> chŏllyul. But the actual word is 전율 chŏnyul. It doesn't seem possible to predict when combinations of Sino-Korean morphemes ending in /n/ and beginning with /r/ will surface as [ll] or as [n]. Compare:
韓 Han 'Korean' + 流 ryu 'flow' = 韓流 Hallyu 'wave of Korean pop culture popularity'
戰 chŏn + 慄 ryul = 戰慄 chŏnyul 'shudder'
The reading 慄 (r)yul is interesting because it corresponds to Middle Chinese *lit without any -u-like vowel. In the idealized Sino-Korean of 東國正韻 Tongguk chŏngun (Correct Rhymes of the Eastern Country, 1447), 慄 is 리ᇙ rírʔ which should correspond to modern Sino-Korean 릴 ril. But there is no such modern Sino-Korean reading: all the hanja read rírʔ in Tongguk chŏngun (栗凓慄鷅搮篥 - all with the same phonetic 栗 <CHESTNUT>) are now read 률 ryul, and the Sino-Korean reading 릴 ril does not exist. (In fact the only 릴 ril in Korean is a loan from English reel.) What happened?
There is no Korean-internal reason I can think of to shift -i-
to -yu-. So maybe Korean borrowed from a Chinese variety with -yu-
and the Tongguk
reading is a 'correction'. Xiaoxuetang lists some modern southern
varieties with labial vowels in 栗 'chestnut', but I doubt they are
relevant:
常山 Changshan Wu loʔ (unique in Wu)
鍾山 Zhongshan luə
There are some Hakka varieties with lut, but I think all those forms are borrowings from Cantonese.
The earliest reconstructible form of the word is *rik. I
reconstruct *-k assuming that it is preserved in a loanword in
the Kam-Sui
language Then
(lik 'chestnut') mentioned by Schuessler (2007: 352). (Later
Chinese -it can be from either *-it or *-ik.)
5. 中山 Zhongshan Hakka is one of the Hakka varieties that seems to
have borrowed 'chestnut' from Cantonese. Zhongshan "is one
of a very few cities in China named after a person." What are the
others?
6. I came across this while reading up on heterograms:
The New Persian term [گبر] Gabr (Zoroastrian) may have arisen "as a contemptuous term for the people who wrote [the Aramaic spelling] 'GBR' ' instead of [the native word] 'mard' " (Sims-Williams, personal communication; see GABR [link added] for other views), in which case it demonstrates a correct reading of the heterogram involved.
I vaguely recall that I thought there might be some connection between gabr and Arabic كافر kāfir, but Shaki (2012) points out that
[...] although Persians still fail to articulate some Arabic speech sounds properly, there is no unusual sound in kāfer [the standard Persian pronunciation of kāfir with lowering of short i to e] that would require phonetic modification. Moreover, although gabr has been sometimes used to denote infidel (kāfer) by semantic extension (e.g., Rūmī, Maṯnawī II, p. 287, v. 177; Ḥasan Rūmlū, ed. Navāʾī, I, p. 384; Eskandar Beg, I, pp. 85, 87), kāfer as a generic word could hardly refer to a specific revealed religion such as Zoroastrianism.
7. Why do I care about heterograms? I've been pondering whether to use the term to describe Tangut characters that might have originated as Khitan small script block-like representations of some other language ('Tangut B'): e.g.,
𗰗 1084 2ghaq1 'ten'
which might correspond to some Tangut B word written phonetically as
𘢰+𘤊
(pronunciation unknown) + (pronunciation unknown).
The Tangraphic Sea analysis of 1084 is unknown. If it were known, most would interpret it as a semantic compound analysis:
𘢰 as an abbreviation of character X
having some semantic relevance to 'ten' +
𘤊 as an abbreviation of character Y having
some semantic relevance to 'ten'
But I side with Kwanten's (1989) basic idea - the analysis might be understood as
𘢰 as pronounced in character X +I disagree with Kwanten on some major points. Kwanten seems to imply
that Tangut was at least typologically 'Altaic', whereas Tangut (A) is
clearly Sino-Tibetan. And in Kwanten's view, the Tangut script
represents that 'Altaic'-type language, whereas in mine, it encodes a
Sino-Tibetan language with spellings sometimes reflecting an unrelated
isolate (Tangut B). To tie that example back to topic 5, 2ghaq1
has as much to do with 𗰗 as Middle
Persian mard has to do with the Aramaic-based spelling
<GBR>: nothing but convention.
8. Today while copying the Sino-Jurchen vocabulary of the Bureau of Translators, I came across the word
<MIRROR³.ku> 'mirror'
which Kiyose (1977: 111) read as bulunku and Jin (1984: 48) read as buneku. Kane (1989: 251) read the word as meleku in the Sino-Jurchen vocabulary of the Bureau of Interpreters.
What's going on there? Let's look at the Ming Mandarin transcriptions in the two sources:
Translators: 卜弄庫 *pu luŋ ku
Interpreters: 墨勒苦 *mə lə ku
And then let's look at attested 'modern Jurchen' forms:
Written Manchu buleku [puləkʰu]
Sibe buluNku, buləku (as written by 山本謙吾 Yamamoto Kengo
1969 and copied in Kane [1989: 251])
Here's what I think happened:
The most conservative version of the Jurchen word was [puləŋkʰu]
[ə] > [u] (to match the other vowels in the word?) (Translators, Sibe)
[u] > [ə] (to match the following [ə]) (Interpreters)
The *m in the Interpreters transcription may be a misperception or approximation of a Jurchen [b]. (Maybe b really was [b] in that dialect rather than [p].)
Maybe b- > m- under the influence of the
following [ŋ], but I doubt it. (But cf. Jurchen bonion > monion
'monkey' in which the nasal is closer to b.)
Jin's -n- is doubtful. I think he was influenced by how 弄 is
now pronounced nòng in standard Mandarin. It is an
example of what I call n-eutralization: n-l
merger in the direction of n. nòng may be a
borrowing into Standard Mandarin from a n-eutralizing dialect.
There are also l-eutralizing dialects. Compare these Mandarin
dialects (I've left out the tones from Wuchang and Hefei):
| dialect\word |
弄 'play' |
來 'come' |
你 'you' |
| standard |
nòng |
lái |
nǐ |
| 武昌 Wuchang (n-eutralizing) |
noŋ | nai |
ni |
| 合肥 Hefei (l-eutralizing) |
ləŋ | lᴇ |
li |
is not in any other known word and could be a logogram
<MIRROR>.
9. Today while copying the Sino-Jurchen vocabulary of the Bureau of Translators, I came across the word
<ha.ji.ha> hajiha 'scissors'
The first character seems to be graphically cognate to the Khitan large script character <ha> and the Chinese character 何 which was pronounced *xo in Liao and Jin Chinese, not *xa which was the Late Middle Chinese pronunciation. My guess is that 何 was a phonogram for ha in the Parhae script that retained its value in the Khitan and Jurchen large scripts even though the vowel of the Chinese original had raised and rounded.
The standard Manchu word for scissors is hasaha. It is hard
to reconcile hasaha with the Translators form hajiha
and the Interpreters form transcribed in Ming Mandarin as 哈雜 *xatsa
that Kane (1989: 582) interprets as hadza or haj(h)a. I
would favor haj(h)a, as Jurchen probably did not have /dz/ or
[dz]. I suppose one could reconstruct a common ancestor with a *z
that became s in Manchu and j in Jurchen, but there is
no other evidence for such a voiced fricative.
20.1.27.23:59: WHITE RAT 1.3
? qulugh ai nai sair ? nyair
'white rat year, head month, three day'
1. Shimunek (2017: 233) reads <THREE> as ɢur, assuming that it shares the same root as the ordinal numeral ɢurər (m.) ~ ɢurən (f.) 'third'. But I fear that 'three' may be to 'third' what English two is to second: i.e., not related.
His ɢur /ɢur/ corresponds to the Written Mongol root ghur. Proto-Serbi-Mongolic *gur [ɢʊr] had a uvular allophone [ɢ] of *g before the lower series vowel *u /ʊ/. In Khitan, that allophone became phonemic after *u /ʊ/, *ü /u/, and *ö /o/ merged into u (Shimunek 2017: 214).
That merger is similar to the merger of Jin Jurchen *u /ʊ/, *ü /u/, and *ö /o/ into u in the Ming Jurchen of the Bureau of Translators (Kiyose 1977: 41). (Note, however, that according to Kiyose, not all *ö /o/ became u /u/ in the Bureau of Translators dialect. *ö in initial syllables became e /ə/ rather than u /u/.) Oddly Kiyose's proposed merger in Jurchen (between the 13th and 15th centuries?) long postdates the merger in Khitan (before the 10th century?). I would have expected the mergers to be more or less simultaneous as a Manchurian areal feature. The mergers require more study.
2. Last night I heard the word pleather on The
Goldbergs and couldn't identify what the p-part was. I
should have been thinking of a pl-part.
3. Last night I found that the unusual block
in the 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan
Small Script) hand
copy of the
epitaph for Empress 仁懿 Renyi (?-1076) of the Khitan Empire (left)
corresponds to the conventional block in the index of blocks on p. 200
(right).
<162-六-229-349> vs. <057-229-349>
The first block can't be read since it has a noncharacter: 六 is a Chinese or Khitan large script character¹, not a Khitan small script character.
The second block can be read, but how?
Kane (2009) would read it as <ci.ta.ge>. Kane assumes that some Khitan characters had inherent vowels. He mentions Nie Hongyin's suggestion of Khitan initial consonant clusters on p. 255, but does not seem to believe in the idea.
Shimunek (2017: 218-220), on the other hand, is comfortable with initial clusters, and would read the word as <c.ta.ge>. The initial cluster /ct/ is unusual in East Asia and the 'Altaic' world, but is plausible from a global perspective. Similar clusters appear in, for instance, Russian чтение [tɕtʲenʲɪje] 'reading' and Czech čtvrt 'quarter'.
The modern Mongolic language Mongghul may not have that
particular cluster (it's not in the list of clusters in Georg
[2003:
293]), but Tibetan influence has led to clusters even in native words:
e.g., rg- in rgon 'wide' (cf. Written Mongol örgen
'id.').
The vowel sequence a ... e violates 'Altaic' vowel harmony rules, though it is not impossible in the region: e.g., just this morning I copied the Manchu word daise-la-bu-ki 'substitute-VBLZ-CAUS-DES'. Such apparent violations need further examination.
1.28.22:48: Manchu daise 'substitute' seems to be a
borrowing
from a hypothetical Chinese *代子 'substitute' (a spoken word that wasn't
preserved in the conservative written language?). The verbalizing
suffix -la- converts nouns into verbs. (I couldn't find an
appropriate abbreviation in the
Leipzig glossing rules, so made up VBLZ 'verbalizer' by
analogy with NMLZ for nominalizer.)
¹The function of 六 in the Khitan large script is
unknown. Despite looking exactly like Chinese 六 <SIX>, it
does not stand for the Khitan word for 'six' which is written with an
entirely different character written at least nine different ways:
My guess is that 六 is a phonetic symbol pronounced something like
Liao Chinese 'six' or like words for 'six' in some language of Parhae.
4. On Reba, a drawn-out pronunciation of the name Hart
was described as having "two syllables": [hɑːːɹt]. I presume that was
an artifat of the script which might have something like "Ha-art"
(which is what the closed captions had). The overlong vowel was
pronounced with a rising pitch.
I got the [ːː] symbol from the Wikipedia Estonian article which uses [ː] for long vowels and [ːː] for overlong vowels (pronounced with a falling pitch unlike "Ha-art").
5. Forty-five years ago today, Super Robot Mach Baron fought プレッシャーケルン Puresshākerun 'Pressure Köln". That got me to look up Kölsch the and find this unusual change:
As a typically Ripuarian phenomenon, [d] and [n] have changed into [ɡ] and [ŋ] in some cases, e.g. std. "schneiden, Wein", ksh. "schnigge, Wing".
1.28.0:01: [d] > [g] reminds me of t > k in
Hawaiian.
6. When I first encountered Japanese 戰慄 senritsu, I thought it had something to do with fighting since 戰 is 'fight'. Then I learned 戰慄 meant 'shudder' and was puzzled by what 戰 was doing. Was 戰慄 originally 'shudder in battle'? Turns out that 戰慄 is a synonym compound 'shudder-shudder'. Schuessler (2007: 605) explains that
[A]s in many lgs., the word for 'war, battle' zhàn [the Mandarin reading of 戦] may be a semantic extension [of] zhàn 'tremble, fear' [...] The semantics are identical to Greek pólemos 'war' which is derived from a root 'tremble, fear' (Buck 1949; §20.13).
Apparently 'shudder' for 戦 only survives in 戦慄.
20.1.26.23:51: WHITE RAT 1.2
? qulugh ai nai sair ? nyair
'white rat year, head month, two day'
1. I've been writing Jurchen dates in a sexagenary month + numeral day hybrid style which gave each day a name that would be unique for five years and gave me an excuse to discuss Jurchen numerals. But this Khitan year I'm going to write both months and days in a mostly numerical style. Mostly because the first month is 'head month' rather than 'one month'.
There won't be another White Rat 1.2 for another sixty years, and I will be, um, gone by then, so these calendrical titles should be unique.
2. Shimunek (2017: 234) reconstructs Khitan 'two' as jur. It
is unclear how the vowel of jur can be reconciled with the
vowel of the root jir 'two' in Written Mongol jirghughan
'six' < jir 'two' x ghu 'three' + -PAn
(lower numeral suffix). Shimunek does not reconstruct a
Proto-Serbi-Mongolic word for 'two'. I presume that word was *j-r.
3. Yesterday it occurred to me that if fragments like this from the tomb of the first Khitan emperor (d. 926) could be dated, they might be the earliest surviving texts in the Khitan large script.
As far as I know, the earliest surviving dated Khitan large script text is the epitaph for 耶律延寧 Yelü Yanning from 986.
And the earliest dated Khitan small script text is the epitaph for 耶律宗教 Yelü Zongjiao from 1053.
宗教 now means 'religion', but I can't find any examples of the term in Scripta Sinica before the Yuan dynasty (i.e., after the Khitan Empire). So maybe the name was to be understood as a phrase 'ancestral teaching'.
Then again, Wikipedia
says the expression is first attested with a narrow, concrete meaning
(崇佛傳統及其弟子的教誨 'the tradition of Buddha-worship and the teachings of his
disciples') in the Buddhist text 續傳燈錄 Xuzhuan denglu (The Lamp
Record of Continued Biographies?) from the 10th century AD. But the
seeming absence of 宗
教 from 10th and 11th century secular texts makes me think the
expression had not yet widely diffused when Yelü Zongjiao got his name.
4. Yesterday while copying the 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan Small Script) hand copy of the epitaph for Empress 仁懿 Renyi (?-1076) of the Khitan Empire, I encountered the first Khitan small script block I've ever seen with this asymmetrical layout (15.1):
| c |
ta |
| 六 |
|
| ge |
|
The trouble is that the character 六 under <c> isn't even a
small script character. Is that an error in the hand copy?
5. 'Toothbrush' in Korean is 칫솔 chhissol < Sino-Korean 齒 chhi 'tooth' + -s- (genitive) + sol 'brush'. I wonder when it was coined - it's obviously modern, but is it pre- or postcolonial?
Most Korean compounds are etymologically 'balanced': a Sino-Korean morpheme is paired with another Sino-Korean morpheme, and a native morpheme is paired with a native morpheme: e.g.,
齒痛 chhithong 'toothache' < Sino-Korean 齒 chhi 'tooth' + Sino-Korean 痛 thong 'pain'
이앓이 iarhi 'toothache' < native 이 i 'tooth' +
native 앓이 arhi 'ache'
So mixed cases like chhissol stand out to me.
齒 chhi 'tooth' is usually a bound morpheme, though Martin et
al. (1967: 1653) says it is a literary word. Is it ever used outside
the fixed expressions
齒(를) 떨다
chhi-rŭl ttŏlda
'tooth(-ACC) shake (v.t.)' = 'grind teeth; stingy'
齒(가) 떨리다
chhi(-ga) ttŏllida
'tooth(-NOM) shake (passive of ttŏlda)' = 'teeth grind'
6. Japanese and Korean have pairs of transparently related intransitive and transitive verbs: e.g.,
ir- 'to enter' (v.i.) > ire- (v.t.)
tŭl- /tɯr/ 'to enter' (v.i.) > tŭri- /tɯri/ (v.t.)
I often rely on analogies with Japanese to function (if it can be
called that) in Korean, but analogies only go so far. Notice I didn't
translate ire- and tŭri-. ire- can mean 'put something
in something' (i.e., make something enter something), but tŭri-
does not. That meaning belongs to the unrelated Korean verb nŏh-.
A list of asymmetries like that would be useful for Korean learners
(and vice versa for Korean-speaking learners of Japanese - there may be
some case where a Korean verb X and a derived verb X' correspond to a
Japanese verbs X and an unrelated Japanese verb Y, but I can't think of
one).
7. Martin (1967: 337) reports the dialect form yŏh- for nŏh-.
Do they go back to *nek-?
*e normally broke to yŏ, but seems to have
simplified to ŏ- before *n- in the ancestor of nŏh-:
*nek- > *nyŏh- > nŏh-. The shift of ny-
> y- did not apply to nŏh- since its *-y-
had been lost. It did, however, apply to the ancestor of yŏh-.
Cf. the variation between ne < nŏy < nyŏy
and ye < nyŏy, both 'yes'.
*-k- weakened to -h- (see Vovin 2010: 29).
Vovin's proposal is not with issues that he discusses. One
that's long bugged me is asymmetry: *-p- and *-t-
lenite to voiced -β- (now -w-) and voiced -r-,
but *-k- weakens to either voiceless -h- or
voiced -ɣ- (now zero) in mostly different environments.
8. I discovered the spelling 這入る <CRAWL ENTER ru> for hair-u 'to enter' when looking up 入る (ha)ir-u 'id.' in Naver (see topic 5). 入る (ha)ir-u is ambiguous, but 這入る hair-u is not. 這入る only has 88,400 Google results. akipun explains that
もし、現代の本などで「這入る」と書いてあったら、古いスタイルで文章を書きたかった or 這って入るという意味で使っていると思います。
If 這入る is written in a modern book or the like, I think the author wanted to write in an old style or is using it to mean 'crawl and enter'.
(The "or" is not me; it's in the original.)
As one could guess from the above passage, the spelling 這入る
<CRAWL ENTER ru> is etymological. The Middle Japanese collocation
faf-i ir-u 'crawl-and enter-FIN' fused into a single word hair-u
simply meaning 'enter'. Could the fact that the common verb wi-ru
'to exist' and ir-u 'to enter' became homophones provided
pressure for hair-u to replace ir-u?
Probably not, as nonfinite forms of the two verbs are not homophonous,
and the two had been homophonous for a long time before the rise
of hair-u.
9. I was surprised to learn that DeBakey
is Arabic (دباغي <dbʔghy>? - could Dabbāghī have been
Anglicized via translation as Tanner?). Its De has
nothing to do with French or Dutch de (as I should have
guessed, since Bakey doesn't look French or Dutch).
Is there a word for pseudomorphemes in altered names: e.g., the O' of O'Dell < Odell which has nothing to do with Irish Ó (the name is English)?
10. Wikipedia has a useful list of don'ts with Arabic names: e.g.,
"Abdul" means "servant of the" and is not, by itself, a name. Thus for example, to address Abdul Rahman bin Omar al-Ahmad by his given name, one says "Abdul Rahman", not merely "Abdul". If he introduces himself as "Abdul Rahman" (which means "the servant of the Merciful"), one does not say "Mr. Rahman" (as "Rahman" is not a family name but part of his [theophoric] personal name); instead it would be Mr. al-Ahmad, the latter being the family name.
I've wondered if Paula Abdul's last name is an Americanization of `Abd al-something. Maybe the right word is Brazilification (?), as it turns out her father had immigrated to the US via Brazil.
11. Via the Arabic names article, a new term for today: theophoric name.












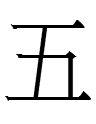

























{kind=link}
{kind=link}
{kind=link}