
101 <YOUNGER.BROTHER>
19.10.19.23:59:
A FOURTH APPROACH TO KHITAN 'STABLES' AND 'ALTERNATORS'
1. See my last post for three
previous approaches to Khitan 'stables' and 'alternators'. Here's a
fourth.
The ż in the Polish name Czyż (see topic 4 below) is [ʂ] in word-final position but is [ʐ] if a vowel-initial ending follows. In Khitan terms, Czyż is an 'alternator', whereas a word ending in sz [ʂ] is a 'stable' because sz remains [ʂ] even if a vowel-initial ending follows.
What if Khitan had a similar phenomenon in 'reverse': i.e., at the beginnings of words:
Stables have invariable series 1 or series 2 initials
Alternators have series 1 initials in absolute initial position but have series 2 initials in certain environments (after sonorants?)
Historically, alternators once had series *3 initials, but series *3 merged with series 1 and series 2 in different environments. (And at this point, the parallels with Polish, much of Slavic, German, or Dutch break down, as their root-final alternations have nothing to do with a series *3.)
In this fourth scenario (with subscript numbers for series):
| environment\stage |
pre-Khitan |
Khitan |
| initial position |
*[C₃] |
[C₁] |
| not after sonorant? |
||
| after sonorant? |
[C₂] |
Series 1 and 2 remain constant in all environments at both stages.
If I plug in some concrete phonetic values:
| environment\stage |
pre-Khitan |
Khitan |
| initial position |
*[t] |
[tʰ] <t> |
| not after sonorant? |
||
| after sonorant? |
[d] <d> |
More complex possibilities are possible: e.g.,
| environment\stage |
pre-Khitan |
Khitan |
| initial position |
*[t] |
[tʰ] <t> |
| some noninitial environments |
[t] <d> |
|
| other noninitial environments | [d] <d> |
In the table above, *[t] has merged with series 2 *[d] into /t/
which has a voiced allophone in certain environments.
In isolation, there would be no way to distinguish between stables
and alternators. One would have to simply memorize which words
alternated: i.e., which words once had series *3 consonants. Series *3
no longer exists, but the alternation is diachronic detritus: a
remnant of its former existence.
2. As I ponder the stable/alternator problem, I've become more skeptical of proposed readings for Khitan small script characters.
I think it would be nice to have a table for all Khitan small script characters with columns for Khitan-internal (i.e., orthographic alternations) and Khitan-external evidence (i.e., Chinese transcriptions of Khitan words) for their readings.
The following three logograms might have blanks in those columns, as
their readings seem to be guesses based on synomyms in other
languages:
101 <YOUNGER.BROTHER>
dɪu (Takeuchi 2012)
cf. Written Mongolian degüü 'younger sibling' (added 10.22.21:45), Jurchen deu(n), Manchu deo
218 <SEAL>
dor (Takeuchi 2012)
cf. Jurchen/Manchu doron (but Written Mongolian törö 'law'!)
The readings above are all from Takeuchi (2012), but other
researchers have proposed similar readings.
At first I thought both of the above words were stables until I realized how shaky their readings were.
3. Sanskrit turns up in the most unexpected places. mantrin (nom. sg. mantrī) 'minister' was borrowed into Malay as menteri, which in turn was borrowed into Portuguese as mandarim, Angliczed as mandarin. And then ...
Robert Cassotto became Bobby Darin thanks in part to the sign at a take out restaurant; the letters M, A and N on the light-up sign "MANDARIN" were not working, leaving only "DARIN", from which Cassotto decided that his last name would be Darin.
Why does Portuguese mandarim end in a nasal vowel?
Did Malay once use the -n stem form of the Sanskrit word?
4. Czyż [tʂɨʂ] to Chess is my new
favorite Americanization.
5. Today I just found out about the confirmation of the identification of មហេន្ទ្របវ៌ត Mahendraparvata 'Great Indra Mountain'.
Sanskrit parvatas 'mountain' can also mean 'seven' (a
reference to seven mountain ranges). Imagine some
Tangut/Khitan/Jurchen-type script with a 'mountain'-like element in a
character <SEVEN> and modern scholars never understanding why.
No, I don't really think parvatas underlies any TJK characters.
My point is that obscure cultural references may underlie the choice of
character elements.
6. Ultraman
Ribut is named after Malay ribut 'storm'.
7. I started following 漢字検定1級・準1級 Kanji Kentei 1/Pre-1,
an account devoted to the most difficult kanji on the Kanken. The
first tweet I saw was about 鬩牆 gekishō 'fight wall' =
'infighting': i.e., to fight within walls.
8. I also started following 現代文語彙bot Modern Vocabulary Bot,
an account devoted to the most difficult kanji on the Kanken. The
first tweet I saw was about 杞憂 kiyū
'groundless worry'. One
might guess 杞 is '"groundless', but the word is literally 'Qi-worry'.
Wikipedia
explains:
It [the state of Qi] is perhaps best known as the inspiration for the popular Chinese idiom, 杞人忧天 (杞人憂天) (Qǐ rén yōu tiān, literally, "Qi people lament heaven" or "the people of Qi worry about the sky"), which is said to refer to the fact that the people of Qi often talked anxiously about the sky falling down on their heads. The idiom is used when mocking a person's needless anxiety over an impossible, inconsequential, or inevitable matter.
杞憂 kiyū is short for 杞人憂天 Ki jin yū ten.
9. Until I heard "Lagos" on Bob and Abishola, I though it was pronounced [lagos]. The name turns out to be Portuguese for 'lakes'; the Yoruba name is Èkó.
19.10.18.19:57: THREE APPROACHES TO KHITAN 'STABLES' AND 'ALTERNATORS'
1. In these three posts, I've laid out the Khitan three-series hypothesis. I want to step back and look at alternatives.
Fact: Khitan words with obstruent initials fall into two categories:
'Stables' that are consistently spelled with symbols for only one series of consonant: e.g.,
'Alternators' that are spelled with symbols for two series of consonants: e.g.,
Fact: Alternators almost always have nonvelar, nonuvular
obstruent initials. I know of no cases of uvular alternators, and the only two cases of velar alternation known to me
involve Chinese loans¹.
Here are three approaches to those two facts:
A. Allographic
Alternations have no allophonic or phonemic significance.
Problem: Fails to explain why the stables never alternate.
The stable 'monkey' is a common word due to its use in the calendrical
system, so the absence of ˣ<b.o(.o)> cannot be regarded as
an artifact of low frequency.
Problem: Fails to explain why back obstruents almost never
alternate.
B. Allophonic
I used to think this was a possibility. In this scenario, /voiceless/ consonants were written as <voiced> in certain environments.
Problem: Voicing environments have yet to be identified.
Problem: This hypothesis predicts that alternators begin with
/voiceless/ consonants. Khitan 'voiceless' consonants were phonetically
voiceless aspirated and regularly correspond to 'voiceless'
(phonetically
voiceless aspirated) consonants in Mongolic. But ... alternators tend
to begin with Khitan 'voiced' consonants! So is the allophony actually
the other way around, with /voiced/ consonants devoicing in
certain environments?
Problem: Many stables begin with /voiceless/ consonants. Why
aren't they spelled with <voiced> consonants in voicing
environments? Some stables are of high frequency, so the absence of
variant spellings cannot be an artifact of rarity.
C. Phonemic (a.k.a. three-series)
The Khitan small script has two types of obstruent symbols: <voiceless> and <voiced>. But the Khitan language has three types of obstruents, and a third type could be written with both<voiceless> and <voiced> symbols, possibly depending on the context (the BC a.k.a. allophonic-phonemic solution).
Problem: Why doesn't the Khitan small script distinguish between three kinds of obstruents?
Answer: Underspecified scripts exist: e.g., for a long time
voicing was unspecified in kana (even though it was
specified in the earlier man'yōgana system!) Even now, Hebrew stop
letters stand for both stops and fricatives. And the traditional
Mongolian script does not differentiate between k/g or t/d.
(But q/gh are always distinguished; cf. the lack of uvular
alternations in Khitan.)
The two series of the small script might be influenced by the two series of the old Uyghur script. Liao Chinese had two series in speech. If a speaker of a two-series language worked on the Khitan small script, he might project those two series onto Khitan.
Problem: Is there any external evidence for three series?
Answer: The Chinese transcriptions of Taghbach (a Serbi language) have three series. But whether those three series correlate to my hypothetical three series for Khitan has yet ot be seen. At the moment I think a merger of three series into two was a Mongolic innovation (under Turkic influence?):
| Proto-Serbi-Mongolic (3
series) |
||
| Proto-Serbi
(3 series) |
Mongolic (2
series) |
|
| Tabghach (3 series) |
Khitan (3 series) |
|
¹I've been citing one case of velar alternation (<k.ai> ~ <h.ai> for Liao Chinese 開). I just found a second: <g.ia> ~ <h.ia> for Liao Chinese 家. I proposed that pre-Khitan *kʰ became h [x], leaving the Khitan with two choices for borrowing Liao Chinese *kʰ: k [k] and h [x]. But why would the Khitan borrow Liao Chinese 家 *kja as <h.ia> [xja]? I do not know of any cases of velar alternation in native Khitan words, so I don't think there was a synchronic rule /k/ > [x]. A similarly troubling case is <h.au> for Liao Chinese 誥 *kàw. (<h.au> is not an alternator, as 誥 does not have an alternate transcription <g.au>. Nonetheless its near-homophone 高 *kaw is transcribed as <g.au>.)
Shimunek (2017: 438 ,442) reads
340 <h>
as <k> like
283 <k>
but that raises two questions:
Why did the Khitan create two characters for <k>? Such redundancy is expected in a script derived from an existing script but not in a newly created script²: e.g.,
Early Cyrillic has both И and І for /i/ because it is based on the Greek alphabet after Η /ɛː/ (the source of Cyrillic И) merged with Ι /iː/ as Η ~ Ι /i/. In other words, late first millennium AD Greek had two letters for /i/, and those two letters were carried over into Cyrillic. (The different values ofИ and І in Ukrainian are a later innovation that has nothing to do with Greek.)
A technical aside: Why is the sequence U+0066 U+0020 U+0418 (i.e., f И) in the previous line displaying as fИ in Chrome, Firefox, and Edge? It's displaying correctly in this paragraph.
Pre-1900 hiragana has an enormous amount of redundancy because
in theory any Japanese syllable could be written as a cursive form of
any Chinese character with a similar pronunciation. In reality, only a
small subset of the potential Chinese character candidates were
actually used as hiragana. But small subsets multiply: e.g., aki
'autumn' had 5 x 8 = 40 possible spellings: (あ ~ 𛀃 ~ 𛀄 ~ 𛀅 ~ z̄²
<a>) x (き ~ 𛀣 ~ 𛀦 ~ 𛀧 ~ 𛀨 ~ 𛀩 ~ 𛀪~ 𛀻 <ki>). That
variation ended in 1900 when a one-kana-per-syllable rule was adopted.
Why does 340 <k> correspond to Liao Chinese *x? I
can answer this question: Shimunek (2017: 213) does not reconstruct any
back fricatives in Khitan, so the Khitan borrowed Liao Chinese *x
as a stop, just as the Japanese (who also lacked back fricatives)
borrowed Middle Chinese *x as a stop k.
²The Khitan small script is, of course, not an ex nihilo creation. It is, to use Juha Janhunen's term, Sinoform: it recycles Chinese strokes and even the shapes of entire Chinese characters. But the phonetic values of Khitan small script characters have no relationship to those of their Chinese lookalikes: e.g., 171 久 is <da> which sounds nothing like Liao Chinese久 *kíw. (Contrast with the pre-1900 hiragana 𛀫 <ku> whose sound value is based on Early Middle Chinese *kuˀ.)
Were the sound values of Khitan small script characters chosen
completely at random, Cherokee-style? (Sequoyah chose D as the model
for his Ꭰ <a>, apparently without knowing that D stood for /d/.)
What if those characters originated as a sort of kungana: e.g., what if
久 <LONG.TIME> was chosen for <da> because there was a
Khitan da-word
meaning 'long time'? That hypothesis is difficult to test because so
few Khitan native words are known. (Kane 2009's Khitan-English lexicon
has ony 254 entries, and many of them are Chinese loans.)
³z̄ is my ad hoc typographical substitution for a two-stroke hiragana <a> not yet in Unicode. It is a cursive reduction of亞 resembling Z with a horizontal line over it. See 字典かな Dictionary of Kana, rev. ed., 笠間書院 Kasama shoin, Tokyo, 1972, p. 9. (Sadly no text is cited for that hiragana.)
2. What is the logic of the character for 樖 Cantonese po1 'classifier for plants'?
合 hap6 (lots
of meanings; none obviously plant-related)
柯 <TREE.ho2> o1 'axe handle'
柯 o1 does rhyme with po1, but a zero-initial
phonetic for a p-syllable is unusual. And I still have no
idea what 合 is doing on top. (合 is not a common top element.)
An alternate spelling 棵 <TREE.FRUIT> in CantoDict
makes more sense to me. 果 <FRUIT> gwo2 also functions as
a semi-phonetic: -w- is labial like p- and -o
matches the -o of po1.
3. I learned from Andrew West's article on Tangutologist Gabriel Devéria that Devéria was also a pioneer in Vietnamese studies (Vietology? - 504 results in Google):
During the following years he concentrated on the study of Annam, publishing a geographic and ethnographic description of Annam in 1886, and an account of the relations between China and Annam two years later.
Devéria's L'écriture
du royaume de Si-Hia ou Tangout (1902) was one of the earliest
books on Tangut that I consulted at
the University of Hawaii library during my fourth Tangut phase. (I
was exposed to Tangut three times before I finally fell in love with
it.)
4. Today I learned the English word mukbang from Korean 먹放 mŏkpang 'eatcast'. (The mixed-script spelling 먹放 has just 9 Google results which shows us how much hanja usage has declined.)
5. For many years I thought 曱甴 were Cantonese-only characters for gaat6 zaat6/2 'cockroach'. But Wiktionary lists a Mandarin reading yuē 'to take things' and a Sino-Japanese reading ō for 曱! dict.variants.moe.edu.tw gives the same meaning but lists the reading as yā (which would correspond to Japanese ō < *apu).
Wiktionary lists a Mandarin reading zhá for 甴. Is that a Mandarinization of Cantonese zaat6/2?
If 甴 zaat6/2 isn't a word by itself, how would one know that it's originally tone 6? I suppose it's because gaat6 zaat6/2 is a reduplicative word and if the first syllable is tone 6, then the underlying tone of the second must also be 6. How many other Cantonese words have the structure X6 X'6/2 (i.e., reduplications of a tone 6 X with a tone changed to 2).
*Stop-final syllables should in theory only develop tones 1, 3, or 6 (high, mid, and low level) in Cantonese depending on *voicing and *length:
| initial\length |
*short |
*long |
| *voiceless |
1 |
3 |
| *voiced |
6 |
|
But zaat6/2 has a high rising tone: i.e., a contour
tone. The other contour tones (low falling 4 and low rising 5) don't
occur in stop-final syllables.
19.10.17.23:55:
VELARS AND UVULARS IN THE KHITAN THREE-SERIES HYPOTHESIS
1. The Khitan 'three-series hypothesis' is that Khitan had three series of obstruents. Two series were written consistently in the Khitan small script, but a third series did not (always?) have unique symbols, and was written with symbols for the other two series.
(Whether there is any evidence for three series in the Khitan large script remains to be seen. I fear that the heavier use of logograms in the large script would obscure the alternations characteristic of the third series.)
There are almost no alternations involving velar and uvular obstruents. Why?
My old guess was that Khitan had implosives (!) which become rarer at backer points of articulation. But implosives are implausible in northeast Asia.
My current guess is that three velar series collapsed into two when *kʰ
weakened to h [x] (cf. *k [kʰ] > h [x] in
Jurchen/Manchu). The sole alternation I know of involving velars is a
transcription of a Chinese syllable:
<k.ai> ~ <h.ai> 'open' < 開 *kʰaj
If Khitan had [k x g] in native words but no [kʰ], perhaps both
<k> [k] and <h> [x] were regarded as approximations of
Chinese [kʰ].
Given that *qʰ weakened to h [χ] in Jurchen/Manchu, maybe Khitan lost *qʰ in the same way. But so far no uvular <χ>-characters have been identified in the small script. <h>-characters that are never used in Chinese transcriptions would be candidates for <χ>-characters. (Liao Chinese had *x but not *χ.)
Another possibility is that *q merged with *ʁ (cf. the voicing of *q in some Persian and Arabic varieties). That might account for this correspondence (Shimunek 2017: 341; the Khitan transliteration and transcription are mine):
Khitan <151.076> <ghu.gho> [ʁʊʁɔ] 'river' : Middle Mongolian qoroqan 'small river' < *qoro- 'river' + *-qan (diminutive suffix)
But *q merging with *ʁ would not be parallel with
the velars or Jurchen/Manchu. (And
the 'river' etymology has problems: e.g., I wouldn't expect Khitan [ʁ]
to correspond to Mongolian r.)
The Khitan consonant system in IPA according to today's version of the three-series hypothesis:
| type |
uvular |
velar |
palatal |
dental |
labial |
| series 3 |
*q |
*k |
*c |
*t |
*p |
| series 1 |
- |
- |
*cʰ |
*tʰ |
*pʰ |
| series 2 |
- |
*g |
*ɟ |
*d |
*b |
| fricative |
(*χ?) *ʁ |
*x |
*ɕ |
*s |
(*f) |
| nasal |
- |
*ŋ |
*ɲ |
*n |
*m |
| liquid |
- |
- |
- |
*r *l |
- |
| glide |
- |
- |
*j |
- |
*w |
*f is only in Chinese loanwords.
2. 拾萬字鏡 JUMANJIKYO
noted that
the 台 (a simplification of 颱) of 台风 ~ 台風 ~ 颱風 'typhoon' (the English word is from Chinese 颱風)
the 台 (a simplification of 臺) of 台湾 ~ 台灣 ~ 臺灣 'Taiwan'
are homophonous in Japanese, Mandarin, and Cantonese but not Korean:
颱 바람 태 (param) thae '(wind) thae'
臺 집 대 (chip) tae '(house) tae'
The earliest attestation of 颱 that I can find in Scripta Sinica
is in an
entry for 1462 in 朝鮮王朝實錄 Chosŏn wangjo shillok (Veritable
Records of the Chosŏn Dynasty), of all places. (That would rule out
the
English and 'Taiwan wind' etymologies since the name Taiwan was
unknown in Korea and China in the 15th century.) But I doubt the word
颱風 'typhoon' is of Korean origin. Could Korean 颱風 thaephung
be a borrowing of an Old Mandarin *tʰaj fuŋ '? wind'? On the
other hand, the Sino-Korean reading tae for 臺 is from a Middle
Chinese *dʌj.
Korean also has an unusual reading of 灣: 만 man with m-
unlike other languages with w- or v-. I presume man
is by analogy with the more common character 蠻 = 蛮 man
'barbarian' (#1254 in Jun
Da's Classical Chinese rankings; 灣 = 湾 is #2802).
The 15th century prescriptive reading of 灣 is regular: ᅙᅪᆫ
<ʔoan>.
3. Korean 깡패 kkangphae 'gangster' has an unexpected 깡 kkang instead of 깽 kkaeng from gang. Normally English [æ] is borrowed as ae, not a. Japanese is probably not a factor since ギャング gyangu would have been borrowed as 꺙 kkyang or a disyllable.
깡패 kkangphae is a redundant compound 'gang-gang'.
패 phae 'gang' is thought to be from Chinese 牌 'tablet'. It
seems to be a made-in-Korea meaning of 牌. I don't understand how 牌 came
to mean 'gang'. At first I thought phae was from Chinese 派
'faction', but that morpheme is 파 pha in Sino-Korean. Perhaps phae
< *[pʰaj] is a post-Sino-Korean (i.e., post-Tang) borrowing from
spoken Chinese 派 *pʰaj that came to be written phonetically as
牌 <tablet> in Korean simply because 牌 was also pronounced as
*[pʰaj] at the time.
4. What is the etymology of Korean 장승 changsŭng 'totem pole'? Martin et al. (1967: 1405) derive it from Sino-Korean 長栍 changsaeng 'long marker' with a irregular vowel change in 栍, a made-in-Korea character.
The English
Wikipedia has two hanja spellings for the word other than 長栍 in the Korean
Wikipedia:
長承 <LONG RECEIVE>
長丞 <LONG MINISTER>
The first looks semi-phonetic. 丞 <MINISTER> sŭng in the second makes semantic sense and requires no phonetic gymnastics to match the modern form.
The key word is 'modern'. The earliest form of the word in Yu (1964: 208) is 댱숭〮 tyàngsúng, a gloss for 堠 'earthen watchtower' in 訓蒙字會 Hunmong chahoe (Collection of Characters for Training the Unenlightened, 1527). There was no 15th century Sino-Korean syllable sung, and a shift of 栍 *sʌjŋ (*tone unknown) to súng is irregular.
Wikipedia mentions two more words for changsŭng:
In the southern regions of Jeolla, Chungcheong, and Gyeongsang, jangseungs are also referred to as beopsu or beoksu, a variation of boksa (복사/卜師), meaning a male shaman.
卜師 is literally 'divination master'. If beoksu (pŏksu in this site's romanization) is somehow related, it is a harmonized version of a *poksu borrowed from spoken Middle Chinese *pok ʂr̩. (The regular Sino-Korean borrowing of syllabic *r̩ was *ʌ which became modern a.) *o became ŏ to match the harmonic category of u. Beopsu (pŏpsu in this site's romanization) might contain 法 pŏp 'law' in place of the meaningless syllable pŏk. (The adverb [p]pak ~ pŏk 'with a vigorous rasp' would not make sense in this context or form a compound noun.)
5. Some romanize Korean <s.i> [ɕʰi] as si and others like me romanize it as shi. Wikipedia has a compromise solution I've never seen before: sʰi!
6. After seeing Yanic Truesdale on Gilmore Girls for months, I finally wondered where his name comes from. It's Breton!
7. I subscribe to the Beekes version of Proto-Indo-European which has no *a. Arapaho is a living language without /a/. The fact that Arapaho contains a gives away the fact that it is not an autonym.
8. I have the sinking feeling that the Botorrita plaques are more comprehensible to Celtic specialists than most Pyu inscriptions are to me.
9. The
Coligny calendar makes me curious about the native Pyu calendar.
19.10.16.23:26: KHITAN 'STABLES' AND 'ALTERNATORS' REVISITED
Can correspondences with other languages help us better understand Khitan 'stables' and 'alternators'?
The comparative table below has three series of obstruents. Stable series 1 and 2 are conventionally written as voiceless and voiced. Alternating series 3 is transliterated as either voiceless or voiced depending on the spelling, but its phonological and phonetic characteristics are open to question.
LC = Liao Chinese
M = Middle Mongolian cognates from Shimunek (2017)
WM = Written Mongolian
| series |
velar |
palatal |
dental |
labial |
| 1 |
k /kʰ/ | c /cʰ/ | t /tʰ/ | p /pʰ/ |
| LC *kʰ |
LC *tʂʰ |
LC *tʰ |
LC *pʰ, *f |
|
| M kü'ün ~ gü'ü 'person' |
M ca'ur 'military campaign' |
M tabun 'five' |
M hon 'year' < *p- |
|
| 2 |
g /k/ | j /c/ | d /t/ | b /p/ |
| LC *k |
LC *tʂ |
LC *t |
LC *p |
|
| M ger 'tent' |
M jun 'summer' |
M dolo'an 'seven' |
M basa 'again' |
|
| 3 |
K |
C |
T |
P |
| LC *kʰ (開) |
- |
LC *t (大德殿) |
LC *p (部僕) |
|
| - |
M jirin 'two (f.)' |
M dörben 'four' |
M bü- 'to be' |
|
| - |
- |
M temgü- 'to collect', WM temdeg
'mark' |
- |
Khitan series 1 consonants always correspond to LC *voiceless
aspirated and M *'voiceless' (phonetically aspirated) consonants with
one exception: Khitan ku 'person' corresponds to M k-
(<kh> in Hphags-pa) and g- (*k- in Chinese
transcription). g- seems to be an idiosyncracy of the M of the Secret
History of the Mongols; all other evidence points to
Proto-Serbi-Mongolic *k- [kʰ].
Khitan series 2 consonants always correspond to LC *voiceless unaspirated and M *'voiced' (phonetically voiceless unaspirated) consonants.
Khitan series 3 consonants generally correspond to M *'voiced' (phonetically voiceless unaspirated) consonants. Two exceptions are
Khitan <t.iu> ~ <d.iu> 'to gather' (Shimunek 2017: 373)
Khitan <t.em> ~ <d.em> 'to grant a title' (Kane 2009: 100)
The semantic link between Khitan <t.em> ~ <d.em> 'to
grant a title' and WM temdeg 'sign' is debatable. Perhaps
that's why Shimunek (2017) didn't include <t.em> ~ <d.em>
in his list of Serbi-Mongolic cognates.
I had thought series 3 might be nothing more than series 1 voicing after voiced segments, but if that were the case, I would expect series 3 to have correspondences like series 1, not series 2.
Here is a radical proposal in which I reinterpret series 2:
Proto-Serbi-Mongolic had three series of consonants which were kept
distinct in Khitan but merged in Mongolic: e.g.,
| series |
Proto-Serbi-Mongolic | Khitan |
Mongolic |
| 1 |
*tʰ |
<t> /tʰ/ | t [tʰ] |
| 2 |
*d |
<d> /d/ |
d [t] |
| 3 |
*t |
<t> ~ <d> /t/ |
The Khitan small script was influenced by LC (which had two series: *t
vs. *tʰ) and Uyghur (which had two series: t vs. d).
Perhaps the small script had two series even though the language
had three. Words with series 3 consonants (i.e., 'alternators') could
be written with either series 1 or series 2 symbols. Compare with how
voiceless unaspirated obstruents in Chinese have been romanized with
both voiceless and voiced letters: e.g., [t] as <t> and <d>.
The Khitan situation could have been complicated by voicing of series 3 in certain environments (after voiced segments?): e.g., /t/ could surface as [d]. I would predict that series 2 symbols would be favored in such environments.
The issue needs more attention. Some basic tasks to be done:
cataloging all stables and alternators
cataloging all contexts of alternators: are spellings
context-dependent or truly random?
Next: Velars and uvulars in the three-series hypothesis.
19.10.16.23:23: INTERNATIONAL PRONOUNS DAY MAP
I wonder if the "no gender distinctions" category in WALS' map "Gender
Distinctions in Independent Personal Pronouns" includes languages
that have no third person pronouns. (Or no pronouns at all.)
Tangut had no third person pronouns (Gong 2003: 607). No third
person pronouns are known in Khitan or Jurchen, but it's not clear
whether that's simply an artifact of incomplete understanding of
limited data. (I'm not counting <e.ghu> which Shimunek [2017:
223] interpreted as əγ " 'they' in the sense of 'these people'
". It looks like <e> 'this' plus <ku> 'person' with initial
lenition.)
Pyu seems to have have oblique third person pronouns but no subject third person pronoun (cf. a similar situation in Classical Chinese):
°o diṃṁ (accusative, possibly originally plural; diṃṁ
may be from a homophonous verb 'to gather')
°o vaṁ (dative)
°o by itself is extremely common in Pyu as a marker of
possessed nouns. The vaṁ of the dative marker may be a locative
noun. 'his side (?)' could have become 'to him'.
19.10.15.22:30:
METAL TONGUE
1. Yesterday, I mentioned that 銛 has
three Mandarin readings:
xiān < MC *siem < OC *sIlem
'shovel; harpoon; sharp'
tiǎn < MC *tʰemˀ < OC *l̥emʔ 'to
take (not the usual word); shovel'
guā < MC *kwat < OC *kʷat 'to cut
off'
(The meanings are from 廣韻 Guangyun [1008]
and were not necessarily current even a thousand years ago.)
金 <METAL> on the left of 銛 is semantic.
舌 on the right of 銛 is an unusual phonetic. Most phonetics represent one class of syllables, but 舌 represents three, so it has three different numbers in Karlgren's Grammata serica recensa (1957) and Schuessler's (2009) Minimal Old Chinese and Later Han Chinese: A Companion to Grammata Serica Recensa:
GSR 288/S 20-10 舌 *mIlat 'tongue' (in theory could be phonetic for other *lat-syllables, but it isn't)
GSR 302/S 22-01 for *kʷat-syllables
It may be tempting to claim that this series is really for *kʷlat-syllables
and is just a *kʷ-branch of GSR 288/S 20-10, but this is
impossible. See below.
GSR 621/S 36-16 for *lem-syllables
銛 is unusual because it simultaneously belongs to two series: GSR 302/S 22-01 and GSR 621/S 36-16.
The phonetic of GSR 302/S 22-01 is 𠯑 OC *kʷat to shut the mouth' which originally has nothing to do with 舌 <TONGUE> (apart from sharing 口 <MOUTH> on the bottom) and hence cannot be conflated with GSR 288/S 20-10. 𠯑 is only abbreviated as 舌 in combinations. There is also another abbreviation 𠮮 which is distinct from 舌 <TONGUE>. Does 銽, the full form of 銛, only have velar readings?
Another more complex variant of 銛 is 𨨱 with the phonetic
活 huó < MC *ɣwat < OC *gʷat
also belonging to GSR 302/S 22-01. Does 𨨱 also only have velar readings?
舌 in GSR 621/S 36-16 is an abbreviation of the semantic
compound 甜 <TONGUE.SWEET> OC *lem 'sweet' as a phonetic.
Such
abbreviated phonetics are common in Tangut: e.g., 𗗘
1079 2lenq3 'sweet' may be an abbreviated phonetic 𘡔 in
𗗕 0207 first syllable of 𗗕𗃨 2lenq3 2o1 'shifting phantom'
𗗖 0504 second syllable of 𗺫𗗖 2by1 2lenq3 'spinach'
𗗡 0955 second syllable of 𘀛𗗡 2ly1 2lenq3 'dirty'
Or one of those three could be phonetic in the others. No Tangraphic Sea analysis survives for any of the four.
𗗘 1079 2lenq3 < *Slim 'sweet' is cognate to 甜 OC *lem.
2. GEOGRAPHY IS NOT LINGUISTIC GENEALOGY: Just as not
all languages of India and Europe are Indo-European, not all languages
of Micronesia
are Micronesian.
According
to Wikipedia, Ross, Pawley, and Osmond (2016)
regard Yapese as a primary branch of Oceanic: a sister of Micronesian.
And according
to Wikipedia, Blust (1993) regards Chamorro and Palauan
as primary branches of Malayo-Polynesian: sisters of Oceanic. Nukuoro and Kapingamarangi
are Polynesian
outliers in Micronesia.
Classification of the languages of Micronesia
| Malayo-Polynesian |
|||||
| Chamorro |
Palauan |
Oceanic | |||
| Yapese |
Micronesian
languages |
Polynesian |
|||
| Nukuoro |
Kapingamarangi |
||||
Proto-Oceanic had a fairly simple phonology with one unusual feature: a distinction between two series of labials:
| plain |
*p |
*ᵐb | *m |
- |
| labialized |
*pʷ | *ᵐbʷ | *mʷ | *w |
Proto-Malayo-Polynesian
only had *p *b *m *w. How did the *Pʷ-series develop?
Yapese doesn't have any labialized labials, but it does have some unusual features absent from Proto-Oceanic and most languages:
glottalized sonorants /ŋˀ nˀ mˀ jˀ lˀ wˀ/
ejectives /kʼ tʼ pʼ θʼ fʼ/
I've never heard of ejective fricatives before. More on them here with audible samples.
I have no idea how either series developed.
Yapese has sixteen vowels. How did they develop from the *five of
Proto-Oceanic? I'm interested in how small vowel systems develop into
larger ones because I am looking for insights into vocalic expansion in
Tangut which went from *six vowels to dozens (without distinctive
length!).
3. It's unfortunate that the peoples indigenous to the regions where the world's most famous cities are now located are not well known. Until today I didn't know about the Ohlone of "the coast from San Francisco Bay through Monterey Bay to the lower Salinas Valley". I spent years in Berkeley without ever learning of the Chochenyo. I've never been to Ohlone Park or the Ohlone Greenway.
4. I look forward to KJ Solonin's forthcoming book The
Descendants of the White and High: The Tanguts in Asian History.
I wonder who'll contribute to it. A corresponding book for Tangut's
distant relative Pyu would be nice, though it might be far slimmer.
19.10.14.23:07: HANGUL AND IDEOGRAPHIC TONE MARKS
(Posted 19.10.16.)
1. I first found the Wikibooks index to 東國正韻 Correct Rhymes of the Eastern Country almost exactly six years ago and have been using it ever since. But I didn't notice until last night that it used Korean-specific Unicode combining characters for tones:
〮 U+302E HANGUL SINGLE DOT TONE MARK (high tone)
〯 U+302F HANGUL DOUBLE DOT TONE MARK (rising tone)
The only other possible tone (low) is unmarked.
Preceding those marks in Unicode order are
〪 U+302A IDEOGRAPHIC LEVEL TONE MARK
〫 U+302B IDEOGRAPHIC RISING TONE MARK
〬 U+302C IDEOGRAPHIC DEPARTING TONE MARK
〭 U+302D IDEOGRAPHIC ENTERING TONE MARK
which I've never seen in any electronic text, though I've seen them in print since I got my first Sino-Japanese dictionary over thirty years ago. Let's see if they work with Tangut:
𗗔〪 0218 1e'4 'level (tone)'
𗨁〫 2612 2phu4 'rising (tone)'
𘃽〭 1616 2o1 'entering
(tone)'
(I don't know how the Tangut translated Chinese 去'departing' since the native Tangut phonological tradition only applies three Chinese tonal categories to Tangut.)
I see that the combining tone characters only work with my Tangut
font if I copy and paste the above text and post it into BabelPad or
BabelMap. The characters aren't in the Tangut font specified by the
style for Tangut on this site.
2. I first heard the Cantonese term zuk1 sing1 for overseas Chinese in 1991. I was told it meant 'empty bamboo', but I could never find any word sing1 meaning 'empty' (and the noun-adjective order was odd). It's taken me 28 years to learn what sing1 is:
The original term is 竹杠 ['bamboo rod': i.e., hollow/empty bamboo]. But 杠 [gong3] is pronounced exactly like 降 "fall”, which is considered as inauspicious. The very opposite of “fall” is “rise”. So 升, meaning “rise”, is chosen to replace 杠.
Strangely the term turns out to mean 'thick bamboo pole' as well as someone 'empty of Chinese culture and values like a hollow bamboo pole'.
3. Dept. of Etymology ≠ Semantics: I wouldn't have guessed this distinction, since both bi- and di- mean 'two':
By contrast, duotheism, bitheism or ditheism implies (at least) two gods. While bitheism implies harmony, ditheism implies rivalry and opposition, such as between good and evil, or light and dark, or summer and winter.
I'm trying to come up with a mnemonic for the distinction: ditheism entails discord, whereas bitheism is associated with b-something? Benevolence?
4. Does Manichaeism still exist?
In modern China, Manichaean groups are still active in southern provinces, especially in Quanzhou and around the Cao'an, the only Manichaean temple that has survived until today. There is a Chinese Manichaean Council with representatives in Tibet and Beijing.[citation needed]
Normally I edit out things like "[citation needed]" when quoting Wikipedia, but I think that instance has to stay.
The Wikipedia article on the 草庵 Cao'an does not mention any modern Manichaeans.
5. Today episode 2 of Super
Robot Mach Baron turns
forty-five years old. I never noticed the unusual spelling of the name
of the
series' robot designer until tonight:
田中⿰㐅見一
That spelling only appears in the closing credits. Online it appears
as 田中視一. Apparently 㐅 is an idiosyncratic simplification of 示 shimesu-hen.
田中 is Tanaka, but I don't know how to read (⿰㐅見)一 ~ 視一. The obvious Sino-Japanese reading Shiichi doesn't sound like a name. O'Neill's Japanese Names gives a native name reading nori for 視, and Wiktionary lists a native reading tomo, so perhaps (⿰㐅見)一 ~ 視一 is Norikazu or Tomokazu (kazu being the native name reading of 一; there is a strong tendency for both readings in a two-character name to be of the same origin).
6. While reading about Heil V1, one of the
robots on Mach Baron,
I encountered a kanji I didn't recognize:銛 mori 'harpoon'.
Shpika stats,
Kanken levels,
and Jun
Da's general Chinese ranks:
| kanji |
Aozora |
news |
Twitter |
Wikipedia |
Kanken |
Jun Da |
| 銛 |
4618 |
- |
- |
3964 |
1 |
6780 |
銛 has three Mandarin readings: xiān, tiǎn, and guā.
More on them tomorrow.
19.10.13.23:54: ?STEMI QAGHAN
(Posted 19.10.16.)
1. In Turkish and Mongolian Studies (1962, 73), Sir Gerard Clau*son mentions
the great Türkü ruler of the second half of the sixth century, Eştemi Kağan (the exacct pronunciation of his name of his name is uncertain, the Byzantines called him Stembis Xagan, and the Chinese Shih-tieh-mi [Shidiemi in pinyin])
How did Clauson guess that the first vowel might be E-? There has to be an initial vowel because Turkic did not allow initial consonant clusters.
The Wikipedia entry for that qaghan is titled "Istämi" and gives
his name in runes
as 𐰃𐰾𐱅𐰢𐰃 <is₂t₂mi>. Is that an attested spelling, or
someone's modern creation? The runic script is often ambiguous, but
that spelling unambiguously represents [i] since <i> has to be
[i] and not [ɯ] in a word with series 2 (front-vowel) consonants
<s₂> and <t₂>. The e is not written since
[s]hort vowels, other than those enclosed in digraphs, should not be written except when they are the first vowel of a word, and then only if they are not a/e. (Clauson 1962: 81)
Other versions of the name in Wikipedia:
Istemi
İstemi (Turkish spelling of Istemi)
Ishtemi (= İştemi in Turkish spelling)
Chinese transcriptions in Wikipedia:
室點密 Shidianmi < *ɕit tém mɨit
室點蜜 Shidianmi < *ɕit tém mit
瑟帝米 Sedimi < *ʂit tèj méj
I don't see the Shidiemi Clauson mentioned.
All the transcriptions point to ş rather than s, contrary to the runic spelling. (The s in the Byzantine spelling could represent Turkic ş since Greek had no letter for ş.)
2. The final *-t in the transcriptions of ?stemi
above corresponds to zero in Turkic. Clauson (1962: 88) noted that
Middle Chinese *-t corresponded to Turkic -ð, -l, -r,
and even zero, but not -t which was transcribed as *tV.
That seems to imply that northwestern Middle Chinese *-t had
already shifted to *-r. Might cases of *-r
corresponding to Turkic zero really involve a subphonemic Turkic [ʔ]
after short vowels? Are there any cases of *-r corresponding to
zero after Turkic long vowels?
3. Taishanese has palatal allophones [tɕ tɕʰ] of /ts tsʰ/ before the high vowels /i u/. This is reminiscent of the palatalization of stops (but not affricates!) before high vowels in Late Old Chinese:
*t(ʰ)i > *tɕ(ʰ)i
*t(ʰ)ɨ > *tɕ(ʰ)ɨ
*t(ʰ)u > *tɕ(ʰ)u
Pulleyblank (1984: 179) opened my eyes to the phenomenon of
palatalization and affrication without palatal vowels, though I should
have figured that at least such affrication was possible since I had
known even before reading his book that Japanese tsu [tsɯ] was
from *tu.
It's been over twenty years since I wrote an unpublished study of
Taishanese historical phonology. It would be interesting if I could
find it, though it's so old that the file might be not readable with my
current software and fonts. Unicode insured that everything I've
written since I switched to Windows XP in 2002 should be legible in the
future.
4. James Evans' 1841 grid for his syllabics is completely full. It has some interesting characteristics.
4a. Onsets
sp- is the only possible initial cluster. It is now obsolete.
4b. Nuclei
There is no <u> or <ū> since Cree
and Ojibwe
only had a single type of labial vowel phoneme written as <o> and
<ō>.
There is a graphic distinction between <e> and <ē> even though
Cree ê only occurs long [...] Not all writers then or now indicate length, or do not do so consistently; since there is no contrast, no one today writes ê as a long vowel.
4c. Codas
There is a single symbol for a cluster coda <hk> since -hk
is "a common grammatical ending in Cree". In Ojibwe, the same symbol
represents the common cluster coda -nk.
Murdoch (1981: 27, 60) includes a second cluster coda symbol <sk>.
I found Murdoch through this page via Wikipedia:
John wrote to Cree Literacy Network about it in 2017: "I researched the origins and evolution of syllabic characters for Cree, Inuit and Dene languages, producing a MEd thesis at the University of Manitoba in 1981. Although James Evans, the Wesleyan Methodist missionary played a part in the first printings in syllabics at Norway House, He was not the person who was the most instrumental in the writing systems conception and spread. During my research I visited archives as well as Aboriginal communities in the Boreal Forest as well as the Eastern Arctic. Missionaries George Barnley, John Horden, Jean-Nicolas Laverlochère, Edmund Peck and Jean Baptiste Thibeault all arrived to Cree, Inuit and Dene nations who were already able to read and write in the system."
Is Murdoch saying the script spread across the First Nations without
Evans' (or any Euro-Canadian?) involvement? It's not clear whether he
agrees withWikipedia's take based on that online article:
there is strong evidence to suggest that the Cree people already knew the writing system and Evans simply adapted it for print.
But skimming Murdoch's thesis, I get the impression that in 1981 (maybe not anymore) he supported the conventional view of Evans as inventor. I'm confused.
This reminds me of the issue of whether the Khitan and Jurchen large
scripts were invented or derived from a preexisting Parhae script.
5. What is the etymology of Yazidi?
Earlier scholars and many Yazidis derive it from Old Iranian yazata, Middle Persian yazad, divine being.
I wouldn't expect a to become i or î (the Yazidi autonym is Êzîdî ~ Êzidî). But I don't know Kurdish historical phonology.
*a > i is not impossible. It's common in Tangut: e.g.,
*tI-S-tsa >𘅗 1321 1ziq4 'shoe'
Compare with Japhug tɯ-xtsa 'id.' (Jacques 2014: 90).
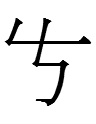


{kind=link}