



19.2.23.23:41: THE DAY OF THE WHITE HARE
Or, in Jurchen,
<šang.giyan HARE DAY> šanggiyan gulma? inenggi
1. My pareidolia glasses make me see Chinese 兔 ~ 兎 <HARE> in Jurchen <HARE>. Compare the Jurchen character with these cursive forms of the Chinese character.
Trying to see the Khitan large script character -
<tau.lia> 'hare'
- a fusion of two phonograms -
<tau> + <lia>
in Jurchen <HARE> is too much of a stretch even for me.
2. I just learned there's a lesser known 'Seoul' - no, not a town
with the same name as the capital, but a homophonous unrelated
Sino-Korean compound 暑鬱 서울 sŏul,
a Chinese medical term that I could calque as 'thermopression'.
3. I wish Naver's Korean dictionary switched to Unicode for premodern hangul. The image for ᄫᅳᆯ <βɯr> in the entry for 서울 Seoul is hard to read.
4. I've had the 'Microsoft Old Hangul' IME installed for over a year but never tried it out until now. It produces ... Latin letters? I Googled "microsoft old hangul" and the first result I get is
The second result I get isI purchased a brand new laptop and installed the korean keyboard however, it does not allow me to actually type in hangul which is the most frustrating thing.
I have tried also tried installing the Microsoft Old Hangul keyboard but I can't get it to actually type in Hangul just in Latin letters.
There are only 119 results. I guess almost no English speakers care about this. I used BabelMap to type ᄫᅳᆯ <βɯr> above, but there's no way I'm going to type more than a few Middle Korean words that way.
Apparently
Microsoft Old Hangul only works in Office. Great ... I have that
IME installed on my laptop without Office.
5. The link above goes to an enthusiast of the グルジア Gurujia
language. I
should have guessed what that was. Other katakana names are the
obvious ジョージア Jōjia and カルトリ Karutori (< ქართული Kartuli).
Kanji short names are 具語 Gugo and 喬語 Kyōgo; -go is
'language', and Kyō is the Japanese reading of the first
character of 喬治, the Chinese version of 'George'.
6. It just occurred to me that 白 <WHITE> in 白村 Hakusuki could be just as un-Chinese as 村 <VILLAGE> suki. Suki is not a Japanese word. According to Wikipedia, Kōjien regards it as an Old Korean word for 'village'. But I don't know of any similar Korean word. Could it be a cognate of Korean 시골 shigol 'village' in an extinct Koreanic language: namely, Paekche?
If <WHITE> - read as *bæk in Late Old and Early Middle
Chinese - is actually a phonogram, could it represent a native Koreanic
word - a cognate of Korean 박 pak 'gourd'? Then the Old Korean
name underlying Hakusuki would be 'Gourd Village'.
(3.1.19:56: In 三國史記 Samguk sagi, 朴 [Late Old Chinese *pʰɔk] is a transcription of the surname of the founder of Shilla and is glossed as 'gourd'.
If that gloss is correct, what I wrote two
entries ago could be wrong. It may not be necessary to regard Late
Old
Chinese 斯盧 for Old Korean *sela 'Shilla' from 三國志 Sanguozhi
[Records of the Three Kingdoms, c. 280] as an early transcription *sie
la predating the shift of *-a to *-ɔ in what I
could call Very Late Old Chinese. Perhaps Old Koreans speakers
thought Very Late Old Chinese *-ɔ was similar to their *a
[phonetically back [ɑ]?] and wrote 'Shilla' as very late Old Chinese 斯盧
*sie lɔ
predating the shift of *-a to *-ɔ. According to Coblin
[1983: 103], the *a to *-ɔ [his *-o] shift was
complete by the Western Jin: i.e., the late 3rd century when the Sanguozhi
was compiled. But there is no guarantee that 斯盧 was a transcription
invented on the spot in 28X; it could have been created prior to the
raising and rounding of *a. In any case, reading 斯盧 as
Sino-Korean saro < earlier Sino-Korean sʌro < 8th
century Late Middle Chinese *sz̩ lo is anachronistic. Even a
6th century Early Middle Chinese reading like *si[ə] lo would
be
anachronistic.)
7. I saw this blurb for Tao
Te Ching: An All-New Translation:
Renowned translator William Scott Wilson offers a fresh version of the Tao Te Ching that will resonate with the modern reader. While most translators have relied on the "new" text of 200 B.C., Wilson went back another 300 years to work from the original characters used during Lao Tzu's lifetime. By referring to these earlier characters, Wilson is able to offer a text that is more authentic in language and nuance, yet preserves all the beauty and poetry of the work.
The "original characters"? What does that mean? That earlier shapes of the characters somehow give more insight? Why not the 'original wording'? Because "characters" sound so much exotic?
No, he really is referring to the shapes of the characters. In his own words, "the nuance and meaning of the original characters was lost"! (p. 11) My Exotik East alarm is ringing. Loudly. No one's going to invite me to a Japanophile conference. Sniff.
I don't see him using a special old-timey font or anything for the
characters. Are their olde shapes a secret for his erudite eyes only?
(And does it even occur to him that the Mandarin readings he uses are
just as anachronistic as his modern font?)
It gets worse ... "Chinese, as a language based on ideographs" (p. 27) ... characters which wouldn't exist if there weren't a spoken language to begin with. Characters which the majority of Chinese through time barely knew or didn't know at all.
John Cikoski would have a fit:
The legend of an "ideographic language" is false; reading Chinese is not grokking images of a man standing by his words or a woman kneeling under a roof or a bear riding a skateboard through a dentist's office or whatever. (p. xii)
So would the late John DeFrancis. His The
Chinese Language: Fact and Fantasy is still a favorite of mine
after over thirty years.
I am reminded of Bernhard Karlgren's "Notes on Lao-Tse"
(1932: 1):
Of all the documents of the pre-Han China, no one has attracted and interested Western readers so much as the short and exceedingly pensive treatise Tao te king [= Tao Te Ching] attributed to an unknown author around 400 BC. It has been translated several dozen times into Western languages. The majority of these "translations" merely reveal that their translators have had very little knowledge of the Chou-time language.
[...]
In most of these translations [the ones Karlgren regards as "[t]he most serious attempts" which makes one wonder what he thinks of the others] we find lines interspersed in the text, being explanatory speculations of the translators, for which additions the classical Chinese text has no corresponding passages.
It would be nice to see a Jurchen translation of the Tao Te Ching. Here's a Manchu version with the original Chinese and Karlgren's translation for comparison:
道可道也,
doro be doro oci ojo-ro-ngge,
'way ACC way TOP be-IPFV.PTCP.NMLZ'
BK: 'The Tao Way that can be (told of:) defined'
非恒道也。
enteheme doro waka.
'constant way NEG'
BK: 'is not the constant Way,'
名可名也,
gebu be gebu oci ojo-ro-ngge,
'name ACC name TOP be-IPFV.PTCP.NMLZ'
BK: 'the names that can be named (used as terms)'
非恒名也。
enteheme gebu waka.
'constant way NEG'
BK: 'are not constant names (terms).'
The Wikibooks translation does not match what I see:
There are ways but the way is uncharted;
There are names but not nature in words
I'm glad the ideographic myth hasn't taken root in Jurchenology or
Khitanology. The enigmatic construction of many Tangut characters makes
tangraphy fertile ground for the ideographic myth.
8. Is that supposed to be a Chinese character on the cover of Ideals of the Samurai?
9. Why wasn't I assigned Cikoski's Introduction to Classical Chinese (1976) at Berkeley? It was published there fourteen years before I took Classical Chinese.
Two days ago I found Brandt's Introduction to Literary Chinese, an example of the common sink-or-swim method. Blub blub.
10. I realized that Jurchen
is parallel to Khitan<sen.gi.ge> senggige 'filial piety, relative' < senggi 'blood'
cišid- 'filial' (reconstruction by Shimunek [2017: 219]) < cis 'blood'
which was one of the first words in the small script that I ever saw. I don't think the parallel is coincidental.
Later, Manchu replaced senggige with hiyoo-šun, a
borrowing of Ming Chinese 孝 *xjaw 'filial'.
11. I finally got around to rediscovering Blench
and Post 2013. Too much to quote and comment on here. Maybe I can
seriallize my reaction upon rereading it.
12. I keep forgetting to mention my idea of Jurchen
<sin> [ɕiɴ]
in 'rat' possibly being a phonogram derived from or cognate to Chinese 剩, pronounced *ʂiŋ in Liao and JIn Chinese. The graph could go back to the Parhae script. In Parhae times, the eastern Late Middle Chinese reading of 剩 would have been something like *ɕɦɨŋ. (But why is the Sino-Korean reading from that period ing [iŋ] instead of †sŭng [sɯŋ]?)
13. I didn't know Canadian Aboriginal syllabics were influenced by devanagari and Pitman shorthand. And I should have guessed this:
Canadian syllabics would influence the Pollard script in China.
14. How did Russians come to borrow рисунок risunok 'picture' from Polish rysunek? Wiktionary has lists of Russian borrowings from Polish and Russian terms derived from Polish. The two lists overlap. Does the longer second list contain calques as well as direct borrowings?
15. 3.1.19:49: A topic I forgot to mention: Luce (1985: 24) mentions old spellings of names of Karen (Old Burmese <karyaṅ>) groups:
Pgho for Pwo "in the older [Western?] books"; possibly also Old Burmese <plav>, <plavʔ>, <plo>, <ploʔ>, <plov>, <pravʔ>
Bghai for Bwè "as the older books call them"
Old Burmese <cakrav> "provisionally" for Sgaw
Have historical studies of Karen integrated such data? Pgh- and Bgh- remind me of Burling's (1969: 29) Proto-Karen *pɣ-. More about that in my entry for 2.24.
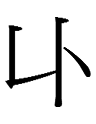
19.2.22.23:59:
THE DAY OF THE WHITE TIGER
Or, in Jurchen,
<šang.giyan TIGER DAY> šanggiyan tasha inenggi
I am out of time for tonight, so there are only three items.
1. I haven't been comfortable with transliterating the first character of the date as <šang> because it also seems to stand for sa- in
<sa.hai> sa-ha-i < *sa-qʰa-i 'know-PFV.PTCP-GEN' (Yongning Temple Stele line 8, 1413; the interpretation is from Jin Qizong [1984: 98])
and various other words where there is no nasal or trace of one. (A
nasal would have blocked the lenition of *qʰ to h [χ]. *saɴ-qʰa-i
would have become Jurchen †sakai.)
And reinterpreting the second character as <nggiyan> isn't going to work because
<RED.nggiyan?> 'red'
can't be fulnggiyan which violates Jurchen
phonotactics. And
the phonotactics of any language I've ever seen. But what if 'red' was fulanggiyan
with an a to breakup the bizarre sequence -lngg-?
(2.25.21:11: I did not pick a at random to be a filler
vowel; Janhunen (2003: 7) reconstructed Proto-Mongolic *xulaxan
'red'. That *x- is from an even earlier *p-. Is there
any reason to suppose that Mongghul fulaan
'red' has f- from *x- < *p- as opposed to
straight from *p-?)
The Jurchen and Khitan large script characters for 'tiger'
are probably related via a shared Parhae prototype distinct from Chinese 虎 <TIGER>.
2.26.18:50: Curiously that Khitan character is not in N4631 which has two near-lookalikes:
0335 and 0280
I do not know whether those are variants of <TIGER>. I have not seen 0280 in calendrical contexts (but perhaps its contexts involve physical tigers), and I have never seen 0335 in context. Here are four instances of 0280 that I have seen:
...
...
Epitaph for the 蕭袍魯 Great Prince of the North, line 3 (1041)
...
...
Epitaph for 蕭袍魯 Xiao Paolu, lines 4-5, 7 (1090)
...
...
Epitaph for 耶律褀 Yelü Qi, line 23 (1108)
I have no idea where word divisions are. I have provided the
characters preceding and following 280 without knowing whether they
represented words or parts of words.
2. I just mentioned the South Korean writer 全光鏞 Chŏn Kwang-yong ... and he turned out to be one of S. Robert Ramsey's informants for the 咸鏡南道 South Hamgyŏng Province dialect of 北青郡 Pukchhŏng County in Accent and Morphology in Korean Dialects (1978).
Ramsey's other informant is a woman with the unusual (to me) name 趙五木禮 <cho o.mok.rye> Cho Omongnye. Are the characters of her trisyllabic personal name simply phonograms (there is a native word omok 'concave' - a strange morpheme for a name - and no native rye; nye 'yes' cannot possibly be relevant) or is the name really a meaningful sequence of three morphemes 五 'five', 木 'wood/tree', and 禮 'ceremony/decorum'?
I was hoping South Hamgyŏng would support my hypothesis of
Proto-Korean *e, but ... I'll have to describe how my dream
crumbled some other time.
3. I saw an online ad for Rocketman starring Taron Egerton, a graduate of Ysgol Penglais School, a name that is structually like the equally redundant Mount Fuji-san in reverse: Ysgol at the beginning is Welsh for 'school', just as -san at the end is Sino-Japanese for 'mountain'.
4. 2.27.21:14: BONUS FOURTH ITEM: I forgot
to mention a solution I had on the 22nd to this problem: How can Jurchen
<sol.go> 'Korea' (cf. Manchu solho 'id.')
and Middle Mongolian 莎郎中合思 solangqa-s 'Koreans'
with -o- be reconciled with the Late Old Chinese transcriptions
斯盧 ~ 斯羅 of Old Korean *sela
with *-e-?
斯盧 and 斯羅 appear to be from two different strata of transcriptions
reflecting different stages of Late Old Chinese:
斯盧 *sie la (in more precise notation, *sie lɑ) predates the shift of *-a to *-ɔ and the shift of *-aj to *-a. At this stage, 羅 was read *laj and was not yet appropriate for transcribing foreign la.
斯羅 *sie la postdates the shift of *-a to *-ɔ and the shift of *-aj to *-a. At this stage, 盧 was read *lɔ and was no longer appropriate for transcribing foreign la.
At neither stage did Late Old Chinese have a syllable *sio.
Sio, er, so what if 斯盧 ~ 斯羅 were attempts to write an Old
Korean *sjola? Or - now it occurs to me - *søla?
(But nothing else indicates Old Korean had front rounded vowels.) The
Jurchen/Manchu and Mongolian names for Korea could be based on *sjola
with the simplification of *sj- to s- to fit their
phonotactics. Then later Old Korean shifted *jo (or *ø?)
to *e.
That idea generates more problems, though.
First, how can Middle Korean sjó 'cow' exist if *jo
became *e? sjó would have to come from something other than *sjo
in Old Korean: e.g., *siro with an *-r- blocking the
fusion of *i-o into *e.
But there is no evidence for a disyllabic early word for 'cow'. The
earliest attestation of a Koreanic word for 'cow' is as 首 in the
sinographic spelling of a Koguryo toponym.首 was read as *ɕuʔ in
Late Old Chinese which lacked *sju or *sjo, so 首 might
have been a viable phonogram for a North Koreanic *sjo.
Second, if the Koreanic word had *ø, that vowel should correspond to Mongolian ö, not the o in solangqa-s.
My guess is that the Jurchen/Manchu and Mongolian names for Korea are borrowings from a North Koreanic *sjola or the like which differed as much from Shilla *sela as Polish Lwów [lvuf] differs from Ukrainian Львів [lʲʋiw] 'Lvov' (But are there any other cases of northern *jo : southern *e?) 'Old Korean' or 'early Koreanic' or whatever we call it must have been as diverse as Slavic or perhaps even Romance are today.
The same must have been true of the Chinese of the time; the
reconstructions here are generic without the regional flavoring that
must have existed. It would be great to see an update of Paul LM Serruys'
1959 study of the 方言 Fangyan
'Regional Words'.
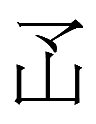
19.2.21.23:59: THE DAY OF THE YELLOW OX
Or, in Jurchen,
<so.giyan OX.an DAY> sogiyan wihan inenggi
1. I've been meaning to post this since 2.7: I wonder if <so>
orignated as a Parhae script cognate of Chinese 牛 <COW>. What if
that cognate were used to write a North Koreanic cognate of Middle
Korean syó? Then in turn this logogram for a North Koreanic
word was then recycled as a phonogram for Jurchen so. (Although
Jin Qizong [1984: 185] glossed this graph as 'yellow', it appears in
spellings for various unrelated so-words, so it may just be a
phonogram.)
2. Anthony Burgess wrote and slept in a Dormobile. Nice portmanteau word. Is there a Chinese equivalent of portmanteau words? Imagine the possibilities in hangul or the Khitan small script.
3. LOL, best use of the button choice meme I've seen yet by noealz (via Jay Lim via Gerry Bevers). Knowing which words are Sino-Korean helps a lot in remembering which words are spelled with ㅐ ae and which ones have ㅔ e: there are hardly any Sino-Korean morphemes with -e: the only one that immediately comes to mind is 揭 ke. And knowing the etymologies of native words helps: e.g., 내- nae- 'to put out' is from 나 na- 'to come out' + the causative suffix -이- -i-. But that won't help with monomorphemic 개 kae 'dog' and 게 ke 'crab' which can't be broken down any further.
4. LOL 2:
"Today, a good working knowledge of Chinese characters is still important for anyone who wishes to study older texts (up to about the 1990s)"
When I first started learning Korean in 1987, I saw mixed-script texts and figured I'd better start learning Chinese character readings right away. I added Sino-Korean readings in pencil to my copy of Nelson's The Modern Reader's Japanese-English Character Dictionary (still in print after 57 years, and for good reason!). Now I hardly see Chinese characters in current Korean texts: e.g., on dongA.com's front page I only see
中文 'Chinese writing' (top of page) and 中國語 'Chinese language' (bottom of page) for the Chinese-language edition; the latter is a Korean word Chunggugŏ which shouldn't be used to indicate a Chinese edition for Chinese readers
日文 'Japanese writing' (top of page) and 日本語 'Japanese language' (bottom of page) for the Japanese-language edition; the latter is a Chinese word which shouldn't be used to indicate a Japanese edition for Japanese readers
Those characters aren't for Korean readers; these nine are.
4 characters used as abbreviations of country names:
北 Puk for Pukhan 'North Korea'
美 Mi for Miguk 'America'
日 Il for Ilbon 'Japan'
獨 Tok for Togil (/tok/ + /il/) 'Germany'
3 characters for political abbreviations
靑 Chhŏng for 青瓦臺 Chhŏngwadae 'Blue House'
野 ya for 野黨 yadang 'opposition'
文 Mun for 文在寅 Moon Jae-in
2 characters for disambiguation with homophones
母 mo 'mother'
前 chŏn 'previous': without characters could be interpreted as 'Commander Chŏn'.
5. TIL about the first Cherokee script (and first Native
American-language) newspaper, the ᏣᎳᎩ ᏧᎴᎯᏌᏅᎯ <tsa.la.gi
tsu.le.hi.sa.nv.hi> Cherokee Phoenix,
which was first published 191 years ago today. It appropriately came
back to life in modern times.
6. I found 朱震球 Patrick Chu's study
of correspondences between Cantonese and Sino-Korean readings. I
worked out the correspondences between Sino-Korean and Sino-Japanese on
my own as I added Sino-Korean readings to my copy of Nelson's
dictionary.
7. I guessed that 'railroad' in Manchu would be a calque of Chinese 鐵道 'iron road', and voila: sele-i jugūn 'iron-GEN road' for 鐵路 'railroad' (lit. 'iron road'; close enough).
8. It is tempting to try to link Manchu sele to Korean 쇠 soe < Middle Korean sóy 'iron', but
- the vowels are too different (e is higher class and nonlabial, whereas o is lower class and labial)
- if sóy were from a Proto-Korean disyllable, its Middle Korean form should have rising pitch rather than a high pitch: †sǒy < *sòrí with a low pitch syllable followed by a high pitch syllable
- if I understand Vovin (2017) correctly, if there ever were a lost liquid in 'iron', it would have to be *-r-, not *-l-, and Jurchen/Manchu retain an r/l-distinction lost in Korean, so sele cannot be from *sere
9. Wiktionary gives अङ्कसङ्गणक aṅkasaṅgaṇaka as a Sanskrit translation of 'laptop (computer)':
aṅka- 'lap'
-saṅgaṇaka- < sam- 'com-'¹ + gaṇaka- 'calculator' (< gaṇa- 'number')
That led me to the Hindi Wikipedia article
संगणक अभियान्त्रिकी saṁgaṇak abhiyāntrikī 'computer engineering'
The first word is just another spelling of -saṅgaṇaka- 'computer'. Hindi drops the final -a of Sanskrit-based forms. (I hesitate to say 'loanword' here, since I suspect the word was coined out of Sanskrit for Hindi before being used in Sanskrit. I can't imagine a Sanskrit neologism for 'computer' predating a Hindi term.)
The second word is puzzling. yāntrikī is the feminine of
'relating to instruments (yantra)'. But what
is abhi- doing? It is hard to translate. Monier-Williams'
definition:
(a prefix to verbs and nouns, expressing) to, towards, into, over, upon. (As a prefix to verbs of motion) it expresses the notion or going towards, approaching, &c (As a prefix to nouns not derived from verbs) it expresses superiority, intensity, &c
Does it correspond to the en- of engineering? At
first I thought the word was derived from a verb abhi-√yam
in which abhi- was an idiomatic prefix, but there is no such
verb.
10. Try
Viacheslav Zaytsev's Tangut eye exam.
11. It's always good to see a new name in the tiny field of Tangutology: 橘堂晃一 Kitsudō Kōichi, who coauthored "Tangut Text Printed in the “Illustration of the Ten Realms of Mind Contemplation 観心十法界図” in the Collection of the State Hermitage Museum, Russia" with Arakawa Shintarō.
12. And here's a solo paper by Kitsudō on Khitan influence on Uyghur Buddhism and a paper by Kitsudō and Peter Zieme on an Old Uyghur text with Tangut and Khitan parallels. I happened to see them right after I was thinking about how someday I might wish I knew more about Turkic.
How I wish there were Buddhist texts in Khitan. Something other than funerary texts. But I fear written Khitan was never a vehicle for Buddhism. Spoken Khitan, however ... oh, to hear a conversation about Buddhism in Khitan!
13. Does the South Hamgyŏng dialect of Korean preserve pre-vowel
harmony
vocalism? E.g., is manjŏ 'ahead' (mixing the lower vowel a
with the higher vowel ŏ) more conservative than Seoul mŏnjŏ?
See Ramsey (1978: 61) for more examples of South Hamgyŏng a
corresponding to Seoul ŏ.
<sol.go> 'Korea' (cf. Manchu solho 'id.')
and Middle Mongolian 莎郎中合思 solangqa-s 'Koreans' have -o- in the first syllable if they are based on Old Korean *sela (transcribed in Late Old Chinese as 斯盧 ~ 斯羅; later respelled as 新羅 <sin.la> - now read Shilla) with *-e-? The Jurchen/Manchu forms made me think the labiality of some suffix spread into the first syllable, but there is no labiality in the noninitial syllables of the Middle Mongolian form.
¹2.24.15:08: Although it's tempting to regard sam- and com- as cognates, Proto-Indo-European *kóm should have become Sanskrit śam, not sam.
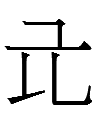
19.2.20.23:59: THE DAY OF THE YELLOW RAT
Or, in Jurchen,
<YELLOW.giyan sin.ge DAY> sogiyan singge inenggi
1. I would expect 'rat' to be †singger since the Manchu word is singgeri, and Jurchen mudur 'dragon' corresponds to Manchu muduri 'id'. But the second graph is <ge>, not <ger>.
The first looks like Chinese 利 'profit' which was read *li in Jin Chinese. But other versions of it look less like 利:
I don't know why Jin Qizong reconstructed its reading as ʃïn
with a nonfront ï (IPA [ɨ] or [ɯ]?). Was he influenced by the
nonfront vowel in the modern Mandarin pronunciation shen [ʂən]
of the character 申 used to transcribe sing-?
If one believed that Jurchen had frontness harmony, the e in
the second syllable should go with a front vowel i in the first
syllable, not ï.
On the other hand, I think Jurchen had height harmony, and the higher series vowel i is what I expect to go with e [ə], the higher series counterpart of a. If i had a lower series vowel, that would have been ī [ɪ] which would not coexist with the higher series vowel e [ə] within a root.
Lastly, the *ʂ- of the Ming Chinese transcription 申 *ʂin reflects a Jurchen s- [ɕ] that is more likely to have palatalized before a high front vowel i than a nonfront ï or a less high ī [ɪ].
2.23.11:13: Jurchen s-, like Korean or Japanese /s/,
palatalizes before /i/.
2. I had been wondering what it's like for Tibetan refugees to move to the West. A firsthand account by བསམ་གཏན་རྒྱལ་མཚན་མཁར་རྨེའུ། bSamgtan rGyalmtshan mKharrme'u (Samten Gyeltsen Karmay):
In September 1961 we all arrived in England, which somewhat reminded us of India. I recall one day David invited us to lunch at Claridge’s, where he was staying. He led us into the hotel garden and on the lawn beside the swimming pool gave us exercise books and pencils and began teaching us the Roman alphabet.
And from his late benefactor David Snellgrove's perspective:
Before starting the journey to the West, we spent a few weeks together in the frontier town of Kalimpong, in British times the beginning of the old route from India into Central Tibet, then easily reached by rail from Calcutta where we would start our air-journey to Europe. Here I started some lessons in English and in world-geography and bought them all European style clothes, which they wanted to have so as not to be so conspicuous in there new setting.
3. At last I see (but can't read, alas) Graham Thurgood's PhD
dissertation The
Origins of Burmese Creaky Tone and a much shorter book Notes on the
Origins of Burmese Creaky Tone.
4. I should look into what caused Roger Blench to change his mind
about the classification of Kman (Miju). Compare:
2011 (with my former student Mark Post):
Miju does have more Tibeto-Burman roots than some of the other languages considered here, so it is provisionally classified as an isolate within Sino-Tibetan.
2015:
Kman is usually considered a Tibeto-Burman language, part of the ‘North Assam’ group, a characterisation which goes back to Konow (1902). However, there is no published argument defending this classification andBlench & Post (2013) consider it equally likely to be a language isolate.
I need to review Blench
& Post (2013).
5. I can't believe I never saw EG Pulleyblank's 1965
article
interpreting the Middle Chinese transcription 突厥 *dot kut
simply as
'Türk' until now.
6. Two different descriptions of Kman (Miju) consonants:
Wikipedia has labialized velar fricatives /xʷ ɣʷ/ without nonlabialized counterparts /x ɣ/.
They seem to correspond to Roger Blench's unaspirated and aspirated /hʰ h/. I've never seen an aspirated /hʰ/ before.
By "consonant prosodies" which "include "labialisation,
palatalisation, lateralisation and rhoticisation", does Blench mean
clusters with [w j l r] after a consonant?
7. I noticed that the Tangut characters
𗄠 4524 2ngwu1 < *P.ŋoH or *Pʌ.ŋəH 'leader'
𗄟 4528 2ngwu1 < *P.ŋoH or *Pʌ.ŋəH 'official'
(the two characters probably represent the same word in two different contexts)
have the same element as the 'sorcerer' characters in my previous entries:
𗄞 4539 1vyq3 < *S.wi(p/t) 'wizard, witch, sorcerer'
𗄦 4527 2jeq2 < *S.NdreH or Sɯ.NdraŋH 'wizard'
𗄤 4536 2ror4 < *Cɯ.roH 'wizard, witch, sorcerer'
𗄥 4550 1lheq4 < *Sɯ-ɬe or *Sɯ-ɬaŋ 'wizard, sorcerer'
So is 𘠋 a semantic element for a person of authority? Not always - what is it doing in
𗄡 4529 2kyq4 < *S.kiH 'burnt'
whose analysis is unknown?
8. Only now did I discover Andrew West's BabelStoneHan font
has hentaigana!
9. How is Nadsat translated into Russian?
10. I had no idea Anthony Burgess had such a rich linguistic background: e.g.,
Burgess attained fluency in Malay, spoken and written, achieving distinction in the examinations in the language set by the Colonial Office. He was rewarded with a salary increase for his proficiency in the language.
[...]
During his years in Malaya, and after he had mastered Jawi, the Arabic script adapted for Malay, Burgess taught himself the Persian language, after which he produced a translation of Eliot's The Waste Land into Persian (unpublished).
11. I wish Gerry Bevers wrote posts at Literary Chinese for Korean Learners. I've never seen anything on learning hanmun in English!
12. Bevers is not afraid to touch the radioactive Liancourt Rocks / Dokdo / Takeshima issue.
19.2.19.23:59:
THE DAY OF THE RED PIG
Or, in Jurchen,
<RED.giyan PIG DAY> fulgiyan uliyan inenggi
1. The Jurchen logogram <PIG> is clearly cognate to the Khitan large script logogram
<PIG>
but neither seems to have any cognate Chinese character unless I put on my pareidolia glasses and see a resemblance to 亥 'pig (in the 12-animal cycle)'.
I have shown the late form of the character from the vocabulary of the Bureau of Translators (#162; early 1400s?). Interestingly the earlier form of the character from the 進士 jinshi candidate monument (1224)
looks less like the Khitan form. Unfortunately, the character is not in what remains of the Jurchen Character Book thought to contain the earliest forms of characters.
2.22.: THEORY HERE
2. Shimunek (2017: 45) reads the Old Mandarin transcription of a
Khitan river name as *niawlaka. He regards the Chinese
transcription of a Serbi river name as a cognate *ñawlag.
He rejects attempts to connect the river name to Khitan
<n.i.gu> 'gold';
the words are too dissimilar. Instead he sees a possible link to *ñaw
'lake'.
One problem is that *a had shifted to *o in Old Mandarin, so was read *niawloko. In an earlier period, those graphs would have been read as *niawlaka, but in that period, a final *-g would have been transcribed as *-k (as in the Serbi hydronym's transcription), whereas Old Mandarin lacked final stops, necessitating a whole syllable *-ko to transcribe foreign *-g.
I think that *-g may have been uvular *-ɢ or *-ʁ
to harmonize with *a.
3. Shimunek (2017: 44) regards the transcriptions of an ethnonym that Pulleyblank (1983) reconstructed as *tägräg as "further evidence in support of Beckwith's (2007a) of dialectal variation between coda *g and *ŋ in northern frontier varieties of Old Chinese and Early Middle Chinese."
| Transcription |
丁零 |
鐵勒 |
敕勒 |
狄歷 |
特勒 |
| Shimunek |
*tɛyŋ liayŋ | *tʰɛr (< Beckwith's *tʰêk) lək |
*ṭʰik lək |
- |
- |
| This site |
*teŋ leŋ | *tʰe(ik/t/r) lək |
*ʈʰɨək lək |
*dek lek |
*dək lək |
(2.20.1:15: The last two columns are my additions.)
I don't think such variation is necessary. *-k and *-ŋ are simply two different strategies to transcribe foreign *-g. There is no need to project *-g into Chinese.
Wikipedia avoids the issue of what the ethnonym was at the time by
taking the easy (though anachronistic) option of reading 丁零 in standard
Mandarin as Dingling,
鐵勒 as Tiele, etc.
4. Vovin (2003: 97) proposed that Cheju 굴레 kulle 'mouth' "is likely to be connected with Japonic *kutu- 'mouth'." He repeats this proposal on p. 24 in the section on a possible Japonic substratum of Cheju in his 2009 book.
Three apparent problems: If the Proto-Japonic word for 'mouth' was *kotu-i:1. Cheju has -u- instead of -o-
(Japonic *o raised to *-u- in Pelagic Japonic but not Peninsular Japonic)
2. Cheju has -ll- instead of †-l- which is the expected reflex of intervocalic *-t-
3. Cheju has -e instead of -wi
But Cheju historical phonology seems like unexplored territory and
my Proto-Japonic form could be wrong, so maybe the gaps can be bridged.
5. Speaking of Cheju, Wikipedia says,
This kingdom [on Cheju] is also sometimes known as Tangna (탕나), Seomna (섬나), and Tammora. All of these names mean "island country".
Really?
섬 sŏm < *sema is 'island', a word shared with Japonic (e.g., pre-Old Japanese *sema 'id.').
But 'country' in Korean and, as far as I know, Cheju is 나라 nara, not 나 na: e.g., Cheju 여나라 Yŏnara ~ 예나라 Yenara 'Japan'.
I don't know of any 탕 thang 'island'.
Ah, I see now, somebody phonetically respelled two old names for
Cheju, 涉羅 <sŏp.ra> [sʰɔmna] and 乇羅 <thak.ra> [tʰaŋna] in
hangul. Neither 涉 Sŏp nor 乇 Thak mean 'island'. Nara
cannot be abbreviated to 羅 -ra. See more old
names for Cheju here.
And Vovin (2009: 25) thinks 耽牟羅 Thammora has "a transparent Japonic etymology": it is either cognate to Japanese tani 'valley' + mura 'village' or Japanese tami 'folk' + mura 'village'.
耽 Tham could reflect a reduction of *tani- to *tam- before *m-.
牟 was read as *mu 'moo' in mainstream Old and Midlde Chinese. But the Sino-Korean reading 모 mo may indicate an eastern dialect with *mo for 'moo', as there was no *u to *o shift in Korean. 牟 represented a word for 'to moo' (as well as various homophones: see Karlgren [1957: 285] and Schuessler [2009: 184]), and such an onomatopoetic word might plausibly have vocalic variation. If 牟羅 was read *mora as in modern Sino-Korean, it could be evidence for a Proto-Japonic *mora 'village' whose *o raised to u in Japan but not on Cheju.
Again, no 'island' or 'country'.
6. Oddities in this Wikipedia entry on Cheju mythology:
6a. The translation gets off to a bad start, mentioning a "Ying
Prefecture" not in the actual text. The
Japanese translation
has similar problems; it starts with 瀛州 'Ying Prefecture'. (Or Yŏng if
one prefers to read it in Korean rather than Mandarin. Both readings
are anachronistic.)
6b. Conversely, the translation ignores a lot before the mention of the first god 良乙那.
6c. It would be lazy and anachronistic to read 良乙那 with Sino-Korean readings as ryang + ŭl + na. 乙 is probably a phonogram for *r (Vovin ). 良 is a problem. Did it transcribe a syllable beginning with *r- which would be unusual in initial position in an Altaic language (but see here)? Or did it transcribe a syllable beginning with an *l- (cf. its Middle Chinese reading *l) which is possible in Altaic but unusual for Koreanic?
7. I just ordered Robbins Burling's book Spellbound. What would he say about modern Lhasa Tibetan spelling: e.g.,
གཙང་པོ་ <gtsaṅ.po> ˉtsaṅko 'river'
གཟུགས་པོ་ <gsugs.po.>ོˊsuku 'body'
དོ་པོ་ <do.po.> ˊthopo 'luggage'
(Examples from 星 実千代 Hoshi Michiyo, 現代チベット語文法(ラサ方言) Gendai
Chibetto-go bunpō (Rasa hōgen) [A Grammar of Modern Tibetan (Lhasa
Dialect)]. Transcriptions in italics are in her orthography.)
8. New words for today:
zilant (this neo-tamga for Kazan is a neat example)
wyvern (first encountered 29 years ago in Megadeth's "Five Magics" but I only looked it up today)
enosis (The agreements leading to the proclamation of independence of Cyprus from the United Kingdom were made sixty years ago today.)
I found that last word in Language
and Culture in Northeast India and Beyond: In Honor of Robbins Burling
co-edited by my former student Mark Post.
2.20.1:51: Burling, last seen here, gave me my first introduction to Lolo-Burmese via the data in his 1967 book which I used to write my own reconstruction. I just realized he used Robert B. Jones' Karen data in the same way for his book Proto-Karen: A Reanalysis (1969)!
19.2.18.23:59: THE DAY OF THE RED DOG
Or, in Jurchen,
<RED.giyan DOG DAY> fulgiyan indahūn inenggi
1. I've now been doing this Jurchen calendar shtick long enough to recycle the colors (red last came up on the 9th). Here's the whole cycle:
blue/green > red > yellow > white > black (and back to green again)
Soon I'll be recycling the animals and won't have to make the
occasional new character image from Jason Glavy's font anymore. Yay! (I
love his font; I just don't love the inconvenience of creating an image
for every character I want to display.)
1a. Jin Qizong (1984: 235) derived <RED> from Chinese 金 <GOLD> (not <RED>!). 金 cannot be a phonetic loan, as it did not sound anything like fulgiyan; its Jin dynasty reading was *kim. (I don't agree with Shimunek [2017: 106-108] on the absence of *-m in Jin Chinese; I should go into why later.)
The Khitan large script character
<RED>
looks nothing like the
Jurchen character or Chinese 金 <GOLD>. I thought it might be
related to Chinese 赤 <RED>, but that
character has no similar variants. And to complicate matters
further, Liu and Wang (2004: 23, #84) read this character as a
transcription of Liao Chinese 金 *kim 'gold'!
A problem for the ex Khitanis hypothesis of the origin of the Jurchen script is why the Jurchen chose to copy the script of their "worst enemies" (as Janhunen [1994: 7] put it) in some instances but not others. As Janhunen asked, why didn't they just adopt the Chinese script or the simpler Khitan small script? Why seemingly modify the more complex Khitan large script at random? My view and his is that they did not do that; rather, they adapted the Parhae script, which, as Vovin (2012) demonstrated, predates the Khitan scripts. According to this ex Parhis hypothesis, the Khitan and Jurchen large scripts are sister derivatives of the Parhae script rather than a random deformation of the Chinese script and a derivative of that deformation.
1b. Shimunek (2017: 227) reconstructs the Khitan equivalent of 'red
dog'
as lyawqu ñaq (Yelü Dilie 14.27-28, 1092) with an initial
cluster ly-.
Going by what (Kane 2009: 255) says, I think Nie (1988) may have
been the first to suggest that Khitan had initial clusters.
Altaic languages generally avoid initial clusters. The big exception
is
Middle Korean whose clusters were the short-lived products of the
reduction of word-initial syllables: e.g., pstaj < *pVsVtaj
'time'. Did Khitan initial clusters have similar origins?
2. Shimunek (2017: 225) reads the Khitan small script character
as
<qai> and translates it as 'a discourse deictic demonstrative'
borrowed from and corresponding to (Jin) Chinese 該 *kaj
(my reconstruction) in the bilingual Sino-Khitan Langjun inscription.
But I don't see 該 in the Chinese text. That loan proposal is
phonologically interesting for reasons I should go into later.
3. After I mentioned a blog post on the pronunciation of postvocalic r
in "Please Please Me" on the day of the green monkey, David
Boxenhorn made me listen to it again for the first time in years. Do
you hear an r after a vowel, and if you do, in which words?
4. Almost thirty years ago I was talking to H. Mack Horton about 南總里見八犬傳 Nansō Satomi hakkenden (The Tale of the Eight Dogs of the Satomi of Nansō). I'm glad to see there's a specialist in it who just published a book on it and is translating it. (Here's an unrelated online translation in progress. It's not clear to me whether the online version is based on 曲亭馬琴 Kyokutei Bakin's original or on a modern translation.)
Glynne Walley's courses show a lot of breadth - I guessed correctly
that manga would be one topic, but he's done much more spanning the
last millennium, going beyond the written word into rakugo, noh, and
kyōgen (the latter two in a course with the great title "Monkey Fun").
I once thought I was going to be a Japanese literature scholar, but
as you can obviously tell from this blog, I took a big detour and never
turned back.
5. I'd like to learn more about JD Wisgo who runs selftaughtjapanese.com and
who just published Two
of Six: A Captain's Dilemma, a translation of an online SF
novella with parallel Japanese and English text.
I love parallel texts; my favorite is the Korean-English edition of 全光鏞 Chŏn Kwang-yong's 꺼삐딴 리 Kkŏppittan Ri (Kapitan Ri, 1962) translated by the late Prof. Marshall R. Pihl¹ who was my Middle Korean teacher. I just bought the book on Kindle; it's one of the few stories I've read that has stayed with me for three decades. Disappointingly the Kindle version lacks the Korean text which is in the print edition. At least Prof. Pihl's biography appears in both Korean and English, as does editor Bruce Fulton's - but Chŏn's own biography is only in English!
My Amazon account was hacked over the past few days. Had to contact Amazon for intervention. My account ended up being wiped and terminated.
2.20.22:41: Here's a description of the story by Michael Kociuba who read the same edition I did about thirty years ago:
In the story "Kapitan Lee," by Chon Kwangyong, the struggle to improve one's fortune seems to have taken precedence over loyalty to family or nation. The protagonist -- Dr. Yi Inguk, alias Kapitan Lee -- constantly strives to amass wealth and protect himself even at the expense of his fellow countrymen. As he refuses to treat patients who are unlikely to pay his fees, most of his clients are Japanese before liberation and members of "the moneyed class" after 1945.
Dr. Yi is divided in his loyalties, and that would all depend on who is in control. He served the oppressor during Japanese rule, and when the U.S. is the overlord, he donates a national treasure to the consul's collection without the slightest sense of guilt. Editor [Peter H.] Lee compares the physician to a chameleon, changing his colors to match the world which surrounds him, no matter how servile his efforts are.
I think Peter
H. Lee
was the translator of that edition. I agree with Gerry Bevers; it's a
shame Prof. Lee doesn't have a Wikipedia entry. In lieu of an entry, I
recommend Bevers'
page on him, including his own memories of the man. Is Prof. Lee
still alive? I also recommend Bevers' entire site, Korean Language Notes.
After all these years I finally figured out that 꺼삐딴 Kkŏppittan in the title is based on the pronunciation rather than the spelling of Russian капитан <kapitan> [kəpʲɪˈtan]. Until now I had been expecting a transliteration-like rendering of the word as 까삐딴 Kkappittan. The Russian word has been transliterated in the English translations of Kkŏppittan Ri; if it weren't, the name would be something like †Cuppitan with -u- as an attempt to indicate [ə]. (See A Clockwork Orange for other examples of Russian in English 'phonetic' spelling: e.g., gulliver for голова <golova> [ɡəlɐˈva] 'head'. It just occurred to me that Chinese transcriptions of foreign names are like gulliver: attempts to approximate foreign names using preexisting elements - though in the case of gulliver, the preexisting element is the trisyllabic name Gulliver rather than a syllable.)
6. Here's an interesting name reading I found on Wisgo's
site:
犬吠埼一介 Ikkai Inubōsaki
介 is normally read suke in final position in men's names.
The real surprise is bō for 吠 which is normally read ho-
in hoeru < poyu.
*inu-nə poyu-ru saki > Inubōsaki
'dog-GEN bark-ATTR cape' = 'cape where a dog barks'
There are two problems:
First, although *nə-p > *Np > *Nb > b is possible, the genitive marker nə in a subordinate clause should not be reduced to N, at least not in Western Old Japanese. But maybe the name originates from a different dialect.
Second, neither premodern -oyuru nor modern -oeru can compress to -ō, unless one posits an ad hoc development in the source dialect.
I would expect bō to be from an earlier *nə-popu or *nə-papu. There was no verb †popu, but there is a papu which became modern 這う hau 'to crawl'. It seems then that the name is from
*inu-nə pap-u saki > Inubōsaki
'dog-GEN crawl-ATTR cape' = 'cape where a dog crawls'
without any ad hoc compression (apart from the unexpected
reduction of *nə). The name could theoretically be
written as †犬這埼 'dog-crawl-', but 吠 'howl' is semantically preferable
to 這 'crawl'.
2.19.0:38: I didn't realize 犬吠埼 Inubōsaki contains the animal for this entry until the start of the next day, the day of the red pig!
2.20.22:03: I also hadn't known Inubōsaki was a place name.
Wikipedia's Japanese
and English
articles on Cape Inubō take the 'bark' character at face value.
7. Lastly, here's today's incremental addition to the Tangut sorcerer thread: characters without the 'grass' element for near-synonyms:
𗄞 4539 1vyq3 < *S-wi(p/t) 'wizard, witch, sorcerer'
𗄦 4527 2jeq2 < *S-NdreH or Sɯ-NdraŋH 'wizard'
2.20.23:05: The absence of 𘤃 'grass'
(herbal medicine?) in those characters makes me wonder if 1vyq3
and 2jeq2 were not 'medicine men' unlike the other two words
I've mentioned so far:
𗄤 4536 2ror4 < *Cɯ.roH 'wizard, witch, sorcerer'
𗄥 4550 1lheq4 < *Sɯ-ɬe or *Sɯ-ɬaŋ 'wizard, sorcerer'
Is the shared *S- in three out of the four words so far
significant?
I wouldn't take the slight differences in the definitions from Li Fanwen (2008) too seriously. Ditto for the Chinese definitions I haven't quoted. I suspect neither the English nor the Tangut captures the true differences between the words. Which is not Li's fault - there is nothing to go on but the brief, circular definitions from the Tangut dictionary tradition which define them in terms of each other.
I'm glad these words have survived at all; a wealth of pre-Buddhist Khitan and Jurchen - and Pyu! - vocabulary has probably vanished without a trace. But who knows what lurks among the undefined words in extant Khitan and Pyu texts?
¹2.21.19:05: It's a shame that Prof. Pihl doesn't have a Wikipedia entry. Far Outliers honors him.
I wonder if the
Marshall R. Pihl papers collection contains the materials from the
1994 Middle Korean class that I took.
19.2.17.23:59:
THE DAY OF THE GREEN CHICKEN
Or, in Jurchen,
1. The Jurchen logogram <CHICKEN> might be related to the Khitan large script character<nion.giyan CHICKEN DAY> niongiyan tiko inenggi
<CHICKEN>
but the resemblance is vague at best.
The Jurchen and Khitan words may also be related somehow - the small script spelling of the Khitan word
tells us that 'chicken' was something like t-Qa, but there is no agreement on what was between the t- and -a. The latest reconstruction I've seen is Shimunek's (2017: 372) taqa <t.aq.a>.
The vocabularies of the Bureau of Translators and
Interpreters have different transcriptions of the second syllable of
'chicken': 和 *xo (BoT #152) and 課 *kʰo (BoI
#332, #424). The Chinese forms are only approximate, but there is no
doubt that one had an initial fricative and the other had a stop.
Vovin
(1997: 274) proposed that Jurchen/Manchu intervocalic *-k-
became -h-, Other Tungusic forms for 'chicken' point to a
medial stop. So it seems then that Jurchen tiqo [tɪqʰɔ] in the
later Bureau of Interpreters vocabulary is from a conservative dialect
that didn't lenite *-k-, whereas the earlier Bureau of
Translators form tiho [tɪχɔ] is from an innovative dialect that
did. There is no evidence for a nasal that would have blocked lenition:
*-nk- > -k-.
Manchu coko [tʂʰɔqʰɔ] may be a borrowing from a conservative dialect preserving a medial stop. The first vowel of the Manchu form seems to have assimilated to the second vowel.
2.19.19.24: Wu and Janhunen (2010: 260) noted the similarity of Khitan small script character 39
with the modern simplified Chinese character 开 kai which in turn also happens to resemble Jurchen <CHICKEN>. Since 雞 'chicken' in Middle Chinese was *kej (something like *kaj in the south - far from the Jurchen!), it is tempting to come up with a pseudoexplanation for the Jurchen graph: tiko was written as a variant of 开 which almost sounded like 雞 'chicken'. But that would be anachronistic.
As far as I know, no one has proposed a reading for 39. The diacritic <ˀ> in Kane's (2009: 301) <kải> indicates that it is a placeholder transliteration chosen purely for visual similarity with 开 kai; it is not meant to indicate that Kane thinks 39 was pronounced kai.
39 probably did not stand for a single segment. It is only attested
twice in the corpus in Research on the Khitan Small Script
(1985): once in the epitaph for Empress 宣懿 Xuanyi (18.10.1) and once in
the epitaph for the 許王 Prince of Xu (39.9.2). It occurs just once in
the epitaph for Xiao Dilu (45.4). It is in initial positon before
<is>
in Xuanyi and Dilu and before
<as>
in Xu. Could its reading end in a consonant? Or in i if
<as> is an error for <is>?
2. It took me thirty years to figure out that the Korean honorific nominative/ablative particle kkesŏ is an example of double indirectness as politeness. That explains why it is both nominative and ablative (not a combination I'm used to from an Indo-European perspective):
曾組ᄭᅦ셔 나시면
tsɯŋtso-skəj-sjə na-si-mjən
great.grandparent-DAT.HON-ABL go.out.HON.if
'if the great-grandparents go out ...' (家禮諺解 Karye ŏnhae 2.2, 1632; example found in Lee and Ramsey 2011: 271-272)
아버지께서 온 便紙
abŏji-kke-sŏ o-n phyŏnji
father-DAT.HON-ABL come-REAL.ATTR letter
'a letter that has come from Father' (a modern example from Martin 1992: 637)
In the second phrase, the ablative refers to the source of a physical object, whereas in the first phrase, it refers to the metaphorical 'source' of an action (i.e., its performer).
3. The modern honorific dative particle 께 kke < skəj above is the result of layers of contraction:
- 께 kke is a compound of -s 'GEN' and kəj 'to that place'
- kəj is a contraction of kɯ 'that' + ŋəkɯj 'to that place'
- ŋəkɯj 'to that place' is "derived from" kəkɯj 'to that place' (Lee and Ramsey 2011: 190)
- kəkɯj 'to that place' contains the dative-allative marker -ɯj 'to', so presumably kək was once a noun 'place' - but how did the -ŋ- ~ -k- variation come about? Vovin (2003: 96, 2009: 96 [on the same page in two different publications!]) proposed that Middle Korean intervocalic -k- is from Proto-Korean *-nk-. Two possibilities:
- the demonstratives used to have a final *-n (related to the realis attributive -n?) that was reanalzyed as part of the following word: *kɯn + kəkɯj > kɯ + ŋəkɯj (with irregular fusion of *-nk- to ŋ- in that phrase but regular fusion to -k- in kəkɯj?)
- the original word for 'place' was disyllabic nVkək, reduced to ŋək ~ kək
Martin (1992: 577) analyzed Middle Korean iŋəkɯj 'to this place' as i-ŋək-ɯj. There is no doubt that i is 'this' and ɯj is 'to', but initial ŋ- is odd in a native word.
4. David Boxenhorn asked me about Altaic vowel harmony.
I don't have time to say much, but I can type a few introductory
remarks here.
Altaic can be thought of as a continuum of five families in contact
from east to west:
| West: front harmony |
Central red
zone: height harmony |
East: no vowel harmony |
||
| Turkic |
Serbi-Mongolic |
Tungusic |
Koreanic |
Japonic |
Turkic has frontness harmony like Uralic languages to the west:
Languages in what I call the red zone (after their shared word for 'red') have height harmony:
I believe Old Chinese and possibly also Tangut went through a height
harmony phase influenced by Altaic neighbors.
Japonic has no vowel harmony beyond Arisaka's law: a tendency
against having *ə coexist with *a, *o, or *u
within a root. See section 7.1.1.3 of this
file by Bjarke Frellesvig (who writes *ə as *o and *o
as *wo). In Japonic, there are no sets of harmonizing
affixes like those in other Altaic languages.
Wikipedia led me to Yoshida
(2006) on i becoming e to assimilate to an e
in the same word in modern Kyoto Japanese, but that is not like any
other form of Altaic vowel harmony.
5. When discussing the problem of naming language groupings, David Boxenhorn suggested calling the South Arabian languages (which are not closely related to Arabic and not descended from Old South Arabian) Felician after Arabia Felix. That sounds better than my ideas:
- Mehric after the language with the most speakers
- Mehri-Soqotric, after the two languages with the most speakers
6. Robbins Burling in Proto-Karen: A Reanalysis (1969: 12) used phonostatistical arguments against Robert B. Jones' (1961: 100) reconstruction of twelve final nonglottal stops in Proto-Karen. (Compare with Proto-Karen's relative Old Burmese which only had four final stops: -k, -c, -t, -p; -c was ultimately secondary. Pyu had only three final stops: -k, -t, -p.) All appear only 1-3 times in Jones' reconstruction and are hence suspicious.
When I encounter rarities in Pyu, I note them and file them away instead of immediately granting them phonemic status.
Looking at Burling's (1969: 30-31) own reconstruction, I see asymmetries in his rhymes that I want to explore later.
7. Burling's (1969: 21) comments on Karen tones seem to apply to
tone
systems throughout the Sinosphere:
The tones fall readily into 6 major correspondence patterns. Little phonetic sense can be made of these correspondences. A high rising tone in one language may correspond regularly with a low falling tone in another, and in some cases even checked tones in one language correspond to smooth tones in others. Nevertheless, since the number of tones is small, and the number of examples of each is large, the correspondences hardly seem questionable.
My first encounter with this phenomenon was when I first read about Cantonese in 1990. I was accustomed to standard Mandarin, whose tones correspond with those of Cantonese as follows in sonorant-final syllables (*stop-final 'checked' syllables are complicated):
| Mandarin |
high level |
high rising |
low falling-rising |
high falling |
| Cantonese *voiceless initial |
high level or high falling |
- |
high rising |
mid level |
| Cantonese *voiced initial | - |
low falling |
low rising |
low level |
That was easy to learn. The Taiwanese correspondences were not:
| Initial class |
*voiceless |
*voiced |
||||||
| Cantonese |
high level or high falling | high rising | mid level |
high or mid checked |
low falling | low rising |
low level |
low checked |
| Cantonese |
high level |
high falling |
low falling |
low checked |
mid rising |
high falling (again) |
mid level | high checked |
8. I didn't know there was a living Old
South Arabian language!
9. I've never seen a
term like this for an unidentified language before.
10. Sort of answering my own question, I finally got around to hearing Rihanna's pronunciation of care at about :31 in "Work". It sounds like [kjɛɹ] to me. "Sort of" because I don't know how representative that pronunciation is.
Old Japanese ke might have been something like [kʲɛ].
11. What is the origin of
Geronimo's English name which doesn't sound like his name
[kòjàːɬɛ́] in Mescalero-Chiricahua?
12. No time to look into Tangut
𗄤 4536 2ror4 'wizard, witch, sorcerer'
tonight. I'll just say that it has a near-mirror image
(near-?)synonym
𗄥 4550 1lheq4 'wizard, sorcerer'
with 𘤃 'grass' (herbal medicine?) and 𘤧 'small' (referring to the size of the herbs?)
in opposite places under 𘠋 '?' and
stop there for now.
13. Shimunek (2017: 218) reconstructed Khitan
'was caused to serve' (Shimunek's translation)
as [r̩lgər] which is doubly un-Altaic: Altaic languages do not have native words with r- (Khitan may prove that to be a myth) or syllabic liquids. Typology aside, there is nothing phonetically implausible about his proposal. However, others would read that word very differently: e.g.,
| Khitan small script character |
 |
 |
 |
 |
| Khitan small script character number |
137 |
261 |
349 |
341 |
| Chinggeltei 1979 | ? |
l |
kə | uai |
| Jishi 1996 |
ər | ? |
? |
kəi |
| Chinggeltei 2002 |
rə | l |
gə / ɣə | wei |
| Kane 2009 |
? |
l(e) |
ge |
er |
| Liu 2009 |
ku / tsh |
lə | nie |
li |
| Chinggeltei 2010 |
rə | l |
gə / ɣə | ər / er |
| Wu and Janhunen 2010 | ir |
l |
ge |
er |
| Takeuchi 2012 |
ir |
ɪl |
e' |
er |
| Liu 2014 |
ku / tsh | lə | ni |
li |
| Shimunek 2017 |
r |
l |
ge |
er |
(2.19.19:27: I expanded this list greatly using Andrew
West, Viacheslav Zaytsev, and Michael Everson's wonderful compilation
of readings. I'm surprised Jishi 1996 doesn't have a reading for
261 which is an extremely common character whose [l] can easily be
verified by its presence in transcriptions of Chinese *l-syllables.)
Note that transliterations do not necessarily equate pronunciations:
e.g., compare Shimunek's <r.l.ge.er> with [r̩lgər].

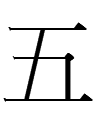






























{kind=link}
{kind=link}