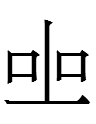
324-090-262 <yên.ó.ui> (蕭敵魯17.22)
16.8.13.23:59: TELL ME WHY THEY SPEAK DIFFERENTLY
I went through the list of 433 verbs in Bucknell's Sanskrit Manual and found three more cases of suppletion. (See my last post for √han ~ √vadh 'kill'.)
√cakṣ 'tell'
the future, desiderative, aorist, absolutive, and perfect participle are formed from √khyā
√paś 'see' (with a rare variant spaś which can mean 'spy' as a noun; cognate to spy)
all non-present indicative forms are formed from √dr̥ś which has no present indicative of its own
√vac 'speak' (cognate to vocal)
the present indicative 3rd pl vadanti is formed from √vad
I learned about √paś 'see' in my beginning Sanskrit class at Berkeley. But the other two are news to me.
I never heard of the root cakṣ - which is not surprising since it only occurs twelve times in the Digital Corpus of Sanskrit. I wouldn't expect suppletion in a word so infrequent that its irregular alternations would be hard to remember. But at least I can guess the reason for the suppletion: √cakṣ is a reduplication of √kāś that was reinterpreted as a separate verb*. It originally must have lacked forms without reduplication, and hence those gaps were filled by forms of √khyā. However, some gaps were later filled by forms of √cakṣ: e.g., the causative 3rd sg cakṣayati (the causative of nonreduplicated √kāś is kāśayati).
The Sanskrit Grammarian does list the the present indicative 3rd pl vacanti, but it's not in the DCS.
√vac is ten times more common than √vad in the DCS. Why replace vacanti with vadanti?
*8.14.23:10: √kāś seems to be to √cakṣ what
- cakar- is to kr̥ 'do' (c-reduplication of a k-root; the palatalization of *kʷ to c reflects an earlier lost front vowel: *kʷe-kʷ- > ca-k-)
- dad- is to dā 'give' (loss of ā in a root preceded by its reduplication)
A similar reduplication that became an independent verb is √jakṣ 'eat' from √ghas 'id.' j is to g(h) what c is to k. gh devoices and deaspirates before s (which becomes ṣ after k).
I just noticed that √khyā has no early attestations. It looks like a borrowing from a Middle Indic descendant of √kśā 'tell' which looks like a zero-grade variant of √kāś plus an ā-suffix like.√yā 'go' < √i 'id.' According to Monier-Williams, "√kśā is mentioned as forming some tenses of √khyā and √cakṣ". Since roots are just artificial abstractions, one could reformulate that by saying there is just one verb with three types of stems: early ā-extended (√kśā), late ā-extended (√khyā), and reduplicated (√cakṣ). Or four if forms like kāśate (√kāś) are included.
16.8.12.23:41: WHAT IS SO APPEALING ABOUT SUPPLETION?
I don't know.
I was looking through Bucknell's Sanskrit Manual whose entry for √han 'kill' has an 3rd sg. aorist avadhīt from an unrelated root √vadh. It is a bit as if the simple past of kill were slew. Bucknell lists other past forms for √han: e.g., the imperfect ahan and the perfect jaghāna. Why not form an aorist from the same root? Whitney's Sanskrit Roots in fact does list four types of such aorists:
1. aghāni passive 3rd sg. ("prescribed or authorized by the Hindu grammarians" but otherwise unattested)
(no type 2 aorist ahanat 3rd sg. active in Whitney - but see below!)
3. ajīghanat 3rd sg. active (from the epics onward)
4. ghān? 3rd sg. active (in the Sūtras); ahasta 2nd pl. active (theoretical)
5. ahānīt 3rd sg.active (Jaiminīya-Brāhmaṇa)
(no type 6 aorist *haṃsīt 3rd sg. active )
(no type 7 aorist *haṃsat 3rd sg. active ; this type is impossible with -an roots)
Conversely, Bucknell lists the 3rd sg. present active of √vadh as ... hanti from √han 'kill'! Yet Whitney lists present system forms for √vadh:
vadha? imperative 2 sg.active
vadheyam optative 1 sg. active (Atharva-Veda), vadhet optative 3 sg. active (Vājasaneyi-Saṃhitā)
The key word is 'system'; the imperative and optative are part of that system, but the most basic part - the present indicative whose 3rd sg. should be vadhati - does not exist in Whitney. (But see below!)
Why were the paradigms of √han and √vadh intertwined? Many forms of linguistic change involve simplification. Suppletion, however, is complication (except from the point of view of counting the total number of forms). I can understand the appeal of analogy - making forms similar makes them easier to generate and recognize. But suppletion has the opposite effect. What is the payoff of replacing vadhati with hanti?
The Wikipedia article on suppletion does not mention a general theory of the origins of the phenomenon, though it is full of Indo-European examples (excluding Sanskrit!) and links to the Surrey Suppletion Database (with non-IE examples but still no Sanskrit). But it did lead me to Greville G. Corbett. I'll be looking at his works soon.
8.13.11:13: The Digital Corpus of Sanskrit lists type 2 aorist forms such as 3rd sg. active ahanat which occurs 23 times in the Mahābhārata alone.
And the DCS lists present indicative forms of √vadh of two different classes: e.g.,1: vadhate 3rd sg. middle (once in Rāmayaṇa)
4: vadhyati 3rd sg. active (twice in Mahābhārata)
Monier-Williams listes the class 1 3rd sg. active vadhati.
So there is textual evidence for fuller paradigms of both verbs. I don't fault Whitney for not including these forms. I cannot imagine the effort needed to make a compilation like his in 1885 without using electronic corpora. Whitney was aware that his book could not be comprehensive (p. vi):
As a matter of course, no such work as the present can pretend to completeness, especially at its first appearance. The only important texts of which we have exhaustive verbal indexes are the Rig-Veda and the Atharva-Veda [...] But I trust it will be found that the measure of completeness here attained is in general proportioned to the importance of the material: that it is the more indifferent forms and derivatives which, having being passed over by the Lexicon, have escaped my glossing also.
I hope to see an exhaustive verbal index of the Tangut corpus someday.
A similar index for the Khitan corpus would also be nice - and difficult since we aren't always certain what is and isn't a verb: e.g., I am not confident that
324-090-262 <yên.ó.ui> (蕭敵魯17.22)
from earlier this week is a verb. The final character
262 <ui>
is a known converb suffix, but not all final instances of it are converbs: e.g.,
334-262 <g.ui> < Liao Chinese 國 *kuj
is a noun 'country'.
Before I conclude, I should point out that the notions of 'root' and 'paradigm' are abstractions. Bucknell (1994: xv) reminds us that roots are "handy labels artificially derived from the actually occurring verb (and noun) forms." Sanskrit students are taught to derive forms from roots, but in reality grammarians derived roots from forms.Similarly, grammarians draw up paradigms based on forms. Sanskrit speakers did not have grids in their heads mixing hanti and avadhīt. How many English speakers are aware that is, was, and be have been grouped together into the same paradigm? On the one hand, discussions of suppletion can be said to be about fictions. On the other hand, it is a fact that unrelated forms can be used in semantically similar contexts - and can completely replace an expected related form. But why? Why do speakers create such complications for themselves? What's the payoff?
16.8.11.23:54: HOW DID THAI BORROW A WORD FOR 'SCORPION' FROM KHMER?
In my last entry, I mentioned Thai ขตอย [kʰà tɔːj] 'scorpion', a borrowing from Khmer. Normally I expect Khmer-Thai words to be spelled more or less as in Khmer. Hence I would predict that the Khmer word corresponding to ขตอย <khtʔy> is *ខ្តយ <khtay> [kʰtɑːj] < *kʰtɔːj. But in fact the standard Khmer word for 'scorpion' is ខ្ទួយ <khduəy> [kʰtuəj] < *kʰduəj which should correspond to a hypothetical Thai *ขทวย <khdvy> [kʰà tʰuəj]. How do I account for this mismatch?
The mismatch of Thai [t] and Khmer [t] < *d (assuming the spelling is etymological*) is easy to explain. The Thai borrowing must postdate devoicing in Khmer:
Before devoicing in both languages, Khmer *d would have been borrowed as Thai *d which became Thai [tʰ].
If Thai devoiced before Khmer, Khmer *d would have been borrowed as Thai *ɗ which became Thai [d].
If Khmer devoiced before Thai, Khmer *d would have become [t] which would have been borrowed as Thai [t].
After devoicing in both languages, Khmer *d would have become [t] which would have been borrowed as Thai [t].
On the other hand, the mismatch of Thai [ɔː] and Khmer [uə] is puzzling. Jenner and Pou (1980-81) regarded Khmer [uə] as phonemically unchanged from the Old Khmer period (when it was written <va>; the vowel symbol <uə> was created later). Does Thai reflect a pronunciation of /uə/ as something like [wɔ] in some premodern Khmer dialect?
Phonological issues aside, why would the Thai borrow a word for 'scorpion' from Khmer at a late (i.e., post-devoicing) period when Khmer was no longer a prestigious language?
*8.12.2:22: I can't find any word for 'scorpion' in Jenner's Old Khmer dictionary. So I don't know how old the spelling ខ្ទួយ <khduəy> is. In theory [kʰtuəj] could be from either *kʰduəj or *kʰtuəj. I can only find one ខ្ត- <kht-> [kʰt-] word in the SEAlang Khmer dictionary; ខ្ទួ- <khd-> is a far more common spelling of [kʰt-]. If 'scorpion' was from *kʰtuəj and was not written until after devoicing, was it written as ខ្ទួយ <khduəy> by analogy with the majority of [kʰt]-words?
16.8.10.23:59: TRANSPARENCY, OPACITY, AND HARMONY IN KHITAN
When I started to look through the small script block index in Wu and Janhunen (2010) to find all the instances of small script character 342my eyes halted at the sight of these two blocks:
006-140 <MOUNTAIN.en> 'mountain*-GEN' (epitaph for 蕭敵魯 Xiao Dilu [1061-?]* 39.12, 1114, and epitaph for 耶律詳穩 Yelü Xiangwen [1010–1091] 37.2, 1091)
and 006-151 <MOUNTAIN.ghu> (耶律詳穩 4.4; perhaps a personal name [Wu & Janhunen 2010: 145])
Why?
140 <en> and 151 <ghu> belong to opposite harmonic categories; the former is yin and the latter is yang.
If Khitan had simple vowel harmony - and it obviously doesn't - 006 <MOUNTAIN> (reading unknown) would only combine with yin or yang characters, not both.
006 seems to mostly combine with yang characters, so it probably represented a yang word. Could that word have been a cognate of Written Mongolian aghulan? There's no way to tell. There is no Khitan-internal evidence for any reading aside from the harmonic hints provided by other characters in its blocks.
If 006 is yang, what is 140 yin <en> doing after it?
I think there are two or three types of Khitan suffixes:
- those that are invariable: e.g., accusative-instrumental <er> and perfective /lUn/
- those that sometimes harmonize with the preceding stem: e.g., genitive <en>
- those that always harmonize with the preceding stem
The third type may not really exist.
Kane (2009: 132-135) lists six types of /n/-genitive suffixes:
<an> <in> <on> <un> <n> <en>
The first four generally appear after stems sharing their vowels. The genitives of <e>-final stems end in <n> rather than <en>. <en> is for consonant-final stems without any regard for vowels: e.g.,
<ta.ang.en> 'Tang dynasty-GEN' (郎君 2.5)
combines a stem with a yang vowel with the yin suffix <en>.
The only (?) consonant stems that do not take <en> might be those ending in <ong> which take <on>: e.g.
,
071-154 <ong.on> 'prince-GEN'
What's going on here? In general, Khitan consonant codas are 'opaque' to harmonic assimilation with the exception of /ŋ/ which is 'transparent' to labial harmonization.
Was Khitan /ŋ/ like Japanese -n which despite its romanization may be perceived by non-Japanese as ŋ and even has vocalic allophones: e.g., 本を /hoN o/ 'book ACC' is [hõũo] (Vance 1987: 36)? If <ong.on> was [õũon], the vowel [ũ] would not be as opaque as a consonant; it would let the labiality of the preceding vowel pass 'through' into the suffix but not its height (which is why <ta.ang.en> above is not *<ta.ang.an> with a low-vowel stem and suffix).
Examples of 'opacity' and 'transparency' in Asian phonology:
In Sanskrit Kṛṣṇena 'by Krishna', retroflexion spreads from ṛ to the adjacent sibilant and nasal but not to the n of the final syllable. Paradoxically, although ṣṇ became retroflex, they are 'opaque' and prevent retroflexion from spreading to the n of the instrumental suffix.
On the other hand, m in Rāmeṇa 'by Rama' is 'transparent', and retroflexion spreads 'through it' and into the n of the instrumental suffix.
In Khmer, vowels developed differently after voiceless and voiced consonants. *kʰɛr would normally become [kʰmae] and *mɛr would normally become [mɛ]. Yet *kʰmɛr 'Khmer' became ខ្មែរ [kʰmae] rather than *[kʰmɛ] because *m was 'transparent' and allowed *kʰ to condition the warping of the vowel.
On the other hand, *ɟ was 'opaque', so *kʰɟɛŋ 'move apart' became *[kʰcɛːŋ] rather than *[kʰcaeŋ] with a warped vowel.
In Thai, tones developed differently after aspirated, unaspirated, and voiced consonants. *kʰɛːn would normally become [kʰɛ̌ːn] with a rising tone and *mɛr would normally become [mɛːn] with a mid tone. Yet *kʰamɛːn 'Khmer' became เขมร [kʰà mɛ̌ːn] with a rising tone rather than *[kʰà mɛːn] with a mid tone because *m was 'transparent' and allowed *kʰ to condition the rising tone on the stressed second syllable. (Unstressed short syllables with voiceless initials developed low tones.)
On the other hand, [t] in ขตอย [kʰà tɔːj] 'scorpion' (also a loan from Khmer) is 'opaque', so the second syllable has a mid tone rather than a rising tone.
*8.11.2:39: Kane (2009: 36) gives 'tomb' and 'tomb cut into a mountain' as alternative glosses for 006 <MOUNTAIN>.
16.8.9.23:59: KHITAN <UL.ÚN> (PART 1)
In my last post, I mentioned the Khitan verb
244-076-261-090-366-144 <s.gho.l.ó.ul.ún> (epitaph for 蕭敵魯 Xiao Dilu [1061-?]* 17.24, 1114)
containing a yang character <gho> ending in the perfective suffix <ul.ún>. I proposed that <ul.ún> might be invariable: i.e., that it didn't have allomorphs like its rough equivalents in its sister Mongolian and Manchu, the descendant of its neighbor Jurchen:
Mo yabu-lugha 'has gone' (allomorph after yang stems)
Mo ükü-lüge 'has died' (allomorph after yin stems)
Janhunen (2003: 24) reconstructed this ending (his 'confirmative [praesens perfecti]') as Proto-Mongolic *-lUxA. Do this ending and the Khitan ending go back to a Proto-Khitan-Mongolic *lU with different suffixes? The Khitan suffix added to *lU might be the nominalizer or participle suffix (?) <ún> after the causative/passive <l.ge> in
254-257-261-349-144 <tem.l.ge.ún> 'awarded' (?) (蕭令公 14.1; see below for more forms of this verb)
Ma susa-ha 'died' (allomorph after yang non-o stems)
Ma gene-he 'went' (allomorph after yin stems)
Ma o-ho 'became' (allomorph after yang o-stems)
I was certainly partly wrong - a price of writing in haste - as the suffix is actually /lUn/ (I use a capital letter to indicate uncertainty about the vowel), and the preceding vowel, if any, depends on the preceding stem, as I will demonstrate in a later part. But so far I do think <ún> is invariable. Here it is following the yin passive suffix <l.ge>:
247-257-261-349-261-144 <tem.l.ge.l.ún> (Kane 2009: 146; source not given) ~ 254-257-261-349-261-144 <d.em.l.ge.l.ún> (蕭仲恭 8.16) 'was awarded'
It seems that Khitan vowel harmony might be obligatory within a root but is only obligatory in certain suffixes - and /lUn/ is not one of them. If Khitan had stress (a detail not indicated in its scripts), roots might have had primary and secondary (and even teritary?) stress whereas suffixes were unstressed and sometimes may have contained neutral vowels that by convention were written with yin characters. (So far I haven't seen any invariable suffixes with yang characters.)
8.10.2:25: The invariable Manchu accusative suffix be [bə] is a merger of Jurchen
~
<ba>, <be>, and <bo>.
Invariable Khitan suffixes may be the results of similar mergers: e.g.,
<er> [ər] (accusative-instrumental) < *ar, *ər, *or?
/lUn/ (perfective) < *lʊn, *lun?
The merger of vowels into schwa is of course not limited to harmonic 'Altaic' languages. English is full of unstressed schwas with multiple origins.
16.8.8.23:58: WHAT IS KHITAN SMALL SCRIPT CHARACTER 342 DOING IN NATIVE WORDS? (PART 3)
Having examined all instances of 342 in Qidan xiaozi yanjiu, I moved on to Wu and Janhunen 2010 which has one word beginning with 324:324-090-262 <yên.ó.ui> (epitaph for 蕭敵魯 Xiao Dilu [1061-?]* 17.22, 1114)
W&J (2010: 95) transliterated this as <üen.ó.ui> and identify it as being in the middle of a sentence, but did not go further than glossing the finite past tense (perfective in my view) suffix <ul.ún> in the sentence-final verb
244-076-261-090-366-144 <s.gho.l.ó.ul.ún>:
The overall meaning of this and the preceding section remains obscure.
W&J 2010 is full of variants of that sentence. At this point it is often simply impossible to do much more with Khitan than to spot finite verb endings and use them to divide unpunctuated text into sentences.
Using my simpliistic yin/yang test and assuming that 076 <gho> is yang, I tentatively regard all other characters in the verb above to be either yang or neutral.
I hypothesize that <ul.ún> could be an invariable suffix like the accusative/instrumental suffix
<er>.
I will provide supporting evidence in my next post.
There is no doubt that 244 <s> and 261 <l> are neutral since they combine with both yin and yang characters. Here they are with the yin characters <g> and <ge>:
244-144-334-261-349-144 <s.ún.g.l.ge.ún> (興宗 20.16, 蕭令公 11.18)
144 <ún> is presumably in the root <s.ún.g> of that verb (<l.ge> is a passive/causative suffix), so I guess that it might be inherently yin in roots (since <g> is yin), though it could appear with roots of all types as part of the suffix <ul.ún>.
Going back to the word with 234, perhaps it was pronounced something like [jɛnɔwi] or [jɛnɔ(ː)j]. I am not sure how to interpret the sequence <ó.ui>. The final [i] or [j] may be a converb suffix. If there is a [w], it may be from a lenited *-b-: cf.
<tau> 'five'
which is cognate to Proto-Mongolic *tabu/n.
8.9.0:26: Janhunen (2003: 6, 397) does not reconstruct *w for either Proto-Mongolic or pre-Proto-Mongolic. Although Khitan is a para-Mongolic language - a sister to the Mongolic languages - there is no guarantee that it too lacked an original [w]. Nonetheless for now I hypothesize that all instances of [w] in Khitan are either in loanwords or transcriptions such as
070-131 <w.u> < Liao Chinese 武 *wu 'martial'
or are secondary: e.g., from *b or in intervocalic hiatus.
*Not to be confused with an earlier, more famous 蕭敵魯 Xiao Dilu (879?-918) who died almost a century earlier.
16.8.7.23:57: WHAT IS KHITAN SMALL SCRIPT CHARACTER 342 DOING IN NATIVE WORDS? (PART 2)
I thought this series of posts might have five or so parts, but there may be as few as three. I went through all the instances of small script character 342
in the corpus in Qidan xiaozi yanjiu and only found two instances of it in non-Chinese (and hence possibly native) words that I didn't list in part 1. One is 342 by itself; another is
324-335-084 <yên.ya.ar> (or <yên.ya.ra>?)
which raises the following questions:
1. Did Khitan distinguish between /ɲa/ and /nja/? Was <yên.ya> phonemically /jeɲa/ or /jenja/? Could it also have been written with
222 <ń>?
2. It seems that at least some Khitan CV characters can also double as VC characters (cf. 𐰹 <oq/uq/qo/qu> and 𐰜 <ök/ük/kö/kü> in Old Turkic). Is the final character 084 <ar> or <ra>? If 084 was <ar>, how did it differ from
123 <ar>?
123 <ar> can be a perfective ending. If 084 is also <ar>, could it too be a perfective ending for a verb whose subject may be the immediately preceding phrase
085 131-236 133-118 <SIX u.ru m.qú> '? [of] the six divisions'?
8.8.0:33: Could 133-118 <m.qú> be a shorter spelling of

133-253-118 <m.o.qú> 'first' (itself a derivative of
133-186 <m.o> 'big, great' [m.])?
If so, then maybe <m.qú> is an adjective modifying a noun <yên.ya.ar>/<yên.ya.ra>, and the final <ar>/<ra> is not a perfective suffix.
16.8.13.23:59: TELL ME WHY THEY SPEAK DIFFERENTLY
I went through the list of 433 verbs in Bucknell's Sanskrit Manual and found three more cases of suppletion. (See my last post for √han ~ √vadh 'kill'.)
√cakṣ 'tell'
the future, desiderative, aorist, absolutive, and perfect participle are formed from √khyā
√paś 'see' (with a rare variant spaś which can mean 'spy' as a noun; cognate to spy)
all non-present indicative forms are formed from √dr̥ś which has no present indicative of its own
√vac 'speak' (cognate to vocal)
the present indicative 3rd pl vadanti is formed from √vad
I learned about √paś 'see' in my beginning Sanskrit class at Berkeley. But the other two are news to me.
I never heard of the root cakṣ - which is not surprising since it only occurs twelve times in the Digital Corpus of Sanskrit. I wouldn't expect suppletion in a word so infrequent that its irregular alternations would be hard to remember. But at least I can guess the reason for the suppletion: √cakṣ is a reduplication of √kāś that was reinterpreted as a separate verb*. It originally must have lacked forms without reduplication, and hence those gaps were filled by forms of √khyā. However, some gaps were later filled by forms of √cakṣ: e.g., the causative 3rd sg cakṣayati (the causative of nonreduplicated √kāś is kāśayati).
The Sanskrit Grammarian does list the the present indicative 3rd pl vacanti, but it's not in the DCS.
√vac is ten times more common than √vad in the DCS. Why replace vacanti with vadanti?
*8.14.23:10: √kāś seems to be to √cakṣ what
- cakar- is to kr̥ 'do' (c-reduplication of a k-root; the palatalization of *kʷ to c reflects an earlier lost front vowel: *kʷe-kʷ- > ca-k-)
- dad- is to dā 'give' (loss of ā in a root preceded by its reduplication)
A similar reduplication that became an independent verb is √jakṣ 'eat' from √ghas 'id.' j is to g(h) what c is to k. gh devoices and deaspirates before s (which becomes ṣ after k).
I just noticed that √khyā has no early attestations. It looks like a borrowing from a Middle Indic descendant of √kśā 'tell' which looks like a zero-grade variant of √kāś plus an ā-suffix like.√yā 'go' < √i 'id.' According to Monier-Williams, "√kśā is mentioned as forming some tenses of √khyā and √cakṣ". Since roots are just artificial abstractions, one could reformulate that by saying there is just one verb with three types of stems: early ā-extended (√kśā), late ā-extended (√khyā), and reduplicated (√cakṣ). Or four if forms like kāśate (√kāś) are included.
16.8.12.23:41: WHAT IS SO APPEALING ABOUT SUPPLETION?
I don't know.
I was looking through Bucknell's Sanskrit Manual whose entry for √han 'kill' has an 3rd sg. aorist avadhīt from an unrelated root √vadh. It is a bit as if the simple past of kill were slew. Bucknell lists other past forms for √han: e.g., the imperfect ahan and the perfect jaghāna. Why not form an aorist from the same root? Whitney's Sanskrit Roots in fact does list four types of such aorists:
1. aghāni passive 3rd sg. ("prescribed or authorized by the Hindu grammarians" but otherwise unattested)
(no type 2 aorist ahanat 3rd sg. active in Whitney - but see below!)
3. ajīghanat 3rd sg. active (from the epics onward)
4. ghān? 3rd sg. active (in the Sūtras); ahasta 2nd pl. active (theoretical)
5. ahānīt 3rd sg.active (Jaiminīya-Brāhmaṇa)
(no type 6 aorist *haṃsīt 3rd sg. active )
(no type 7 aorist *haṃsat 3rd sg. active ; this type is impossible with -an roots)
Conversely, Bucknell lists the 3rd sg. present active of √vadh as ... hanti from √han 'kill'! Yet Whitney lists present system forms for √vadh:
vadha? imperative 2 sg.active
vadheyam optative 1 sg. active (Atharva-Veda), vadhet optative 3 sg. active (Vājasaneyi-Saṃhitā)
The key word is 'system'; the imperative and optative are part of that system, but the most basic part - the present indicative whose 3rd sg. should be vadhati - does not exist in Whitney. (But see below!)
Why were the paradigms of √han and √vadh intertwined? Many forms of linguistic change involve simplification. Suppletion, however, is complication (except from the point of view of counting the total number of forms). I can understand the appeal of analogy - making forms similar makes them easier to generate and recognize. But suppletion has the opposite effect. What is the payoff of replacing vadhati with hanti?
The Wikipedia article on suppletion does not mention a general theory of the origins of the phenomenon, though it is full of Indo-European examples (excluding Sanskrit!) and links to the Surrey Suppletion Database (with non-IE examples but still no Sanskrit). But it did lead me to Greville G. Corbett. I'll be looking at his works soon.
8.13.11:13: The Digital Corpus of Sanskrit lists type 2 aorist forms such as 3rd sg. active ahanat which occurs 23 times in the Mahābhārata alone.
And the DCS lists present indicative forms of √vadh of two different classes: e.g.,1: vadhate 3rd sg. middle (once in Rāmayaṇa)
4: vadhyati 3rd sg. active (twice in Mahābhārata)
Monier-Williams listes the class 1 3rd sg. active vadhati.
So there is textual evidence for fuller paradigms of both verbs. I don't fault Whitney for not including these forms. I cannot imagine the effort needed to make a compilation like his in 1885 without using electronic corpora. Whitney was aware that his book could not be comprehensive (p. vi):
As a matter of course, no such work as the present can pretend to completeness, especially at its first appearance. The only important texts of which we have exhaustive verbal indexes are the Rig-Veda and the Atharva-Veda [...] But I trust it will be found that the measure of completeness here attained is in general proportioned to the importance of the material: that it is the more indifferent forms and derivatives which, having being passed over by the Lexicon, have escaped my glossing also.
I hope to see an exhaustive verbal index of the Tangut corpus someday.
A similar index for the Khitan corpus would also be nice - and difficult since we aren't always certain what is and isn't a verb: e.g., I am not confident that
324-090-262 <yên.ó.ui> (蕭敵魯17.22)
from earlier this week is a verb. The final character
262 <ui>
is a known converb suffix, but not all final instances of it are converbs: e.g.,
334-262 <g.ui> < Liao Chinese 國 *kuj
is a noun 'country'.
Before I conclude, I should point out that the notions of 'root' and 'paradigm' are abstractions. Bucknell (1994: xv) reminds us that roots are "handy labels artificially derived from the actually occurring verb (and noun) forms." Sanskrit students are taught to derive forms from roots, but in reality grammarians derived roots from forms.Similarly, grammarians draw up paradigms based on forms. Sanskrit speakers did not have grids in their heads mixing hanti and avadhīt. How many English speakers are aware that is, was, and be have been grouped together into the same paradigm? On the one hand, discussions of suppletion can be said to be about fictions. On the other hand, it is a fact that unrelated forms can be used in semantically similar contexts - and can completely replace an expected related form. But why? Why do speakers create such complications for themselves? What's the payoff?
16.8.11.23:54: HOW DID THAI BORROW A WORD FOR 'SCORPION' FROM KHMER?
In my last entry, I mentioned Thai ขตอย [kʰà tɔːj] 'scorpion', a borrowing from Khmer. Normally I expect Khmer-Thai words to be spelled more or less as in Khmer. Hence I would predict that the Khmer word corresponding to ขตอย <khtʔy> is *ខ្តយ <khtay> [kʰtɑːj] < *kʰtɔːj. But in fact the standard Khmer word for 'scorpion' is ខ្ទួយ <khduəy> [kʰtuəj] < *kʰduəj which should correspond to a hypothetical Thai *ขทวย <khdvy> [kʰà tʰuəj]. How do I account for this mismatch?
The mismatch of Thai [t] and Khmer [t] < *d (assuming the spelling is etymological*) is easy to explain. The Thai borrowing must postdate devoicing in Khmer:
Before devoicing in both languages, Khmer *d would have been borrowed as Thai *d which became Thai [tʰ].
If Thai devoiced before Khmer, Khmer *d would have been borrowed as Thai *ɗ which became Thai [d].
If Khmer devoiced before Thai, Khmer *d would have become [t] which would have been borrowed as Thai [t].
After devoicing in both languages, Khmer *d would have become [t] which would have been borrowed as Thai [t].
On the other hand, the mismatch of Thai [ɔː] and Khmer [uə] is puzzling. Jenner and Pou (1980-81) regarded Khmer [uə] as phonemically unchanged from the Old Khmer period (when it was written <va>; the vowel symbol <uə> was created later). Does Thai reflect a pronunciation of /uə/ as something like [wɔ] in some premodern Khmer dialect?
Phonological issues aside, why would the Thai borrow a word for 'scorpion' from Khmer at a late (i.e., post-devoicing) period when Khmer was no longer a prestigious language?
*8.12.2:22: I can't find any word for 'scorpion' in Jenner's Old Khmer dictionary. So I don't know how old the spelling ខ្ទួយ <khduəy> is. In theory [kʰtuəj] could be from either *kʰduəj or *kʰtuəj. I can only find one ខ្ត- <kht-> [kʰt-] word in the SEAlang Khmer dictionary; ខ្ទួ- <khd-> is a far more common spelling of [kʰt-]. If 'scorpion' was from *kʰtuəj and was not written until after devoicing, was it written as ខ្ទួយ <khduəy> by analogy with the majority of [kʰt]-words?
16.8.10.23:59: TRANSPARENCY, OPACITY, AND HARMONY IN KHITAN
When I started to look through the small script block index in Wu and Janhunen (2010) to find all the instances of small script character 342my eyes halted at the sight of these two blocks:
006-140 <MOUNTAIN.en> 'mountain*-GEN' (epitaph for 蕭敵魯 Xiao Dilu [1061-?]* 39.12, 1114, and epitaph for 耶律詳穩 Yelü Xiangwen [1010–1091] 37.2, 1091)
and 006-151 <MOUNTAIN.ghu> (耶律詳穩 4.4; perhaps a personal name [Wu & Janhunen 2010: 145])
Why?
140 <en> and 151 <ghu> belong to opposite harmonic categories; the former is yin and the latter is yang.
If Khitan had simple vowel harmony - and it obviously doesn't - 006 <MOUNTAIN> (reading unknown) would only combine with yin or yang characters, not both.
006 seems to mostly combine with yang characters, so it probably represented a yang word. Could that word have been a cognate of Written Mongolian aghulan? There's no way to tell. There is no Khitan-internal evidence for any reading aside from the harmonic hints provided by other characters in its blocks.
If 006 is yang, what is 140 yin <en> doing after it?
I think there are two or three types of Khitan suffixes:
- those that are invariable: e.g., accusative-instrumental <er> and perfective /lUn/
- those that sometimes harmonize with the preceding stem: e.g., genitive <en>
- those that always harmonize with the preceding stem
The third type may not really exist.
Kane (2009: 132-135) lists six types of /n/-genitive suffixes:
<an> <in> <on> <un> <n> <en>
The first four generally appear after stems sharing their vowels. The genitives of <e>-final stems end in <n> rather than <en>. <en> is for consonant-final stems without any regard for vowels: e.g.,
<ta.ang.en> 'Tang dynasty-GEN' (郎君 2.5)
combines a stem with a yang vowel with the yin suffix <en>.
The only (?) consonant stems that do not take <en> might be those ending in <ong> which take <on>: e.g.
071-154 <ong.on> 'prince-GEN'
What's going on here? In general, Khitan consonant codas are 'opaque' to harmonic assimilation with the exception of /ŋ/ which is 'transparent' to labial harmonization.
Was Khitan /ŋ/ like Japanese -n which despite its romanization may be perceived by non-Japanese as ŋ and even has vocalic allophones: e.g., 本を /hoN o/ 'book ACC' is [hõũo] (Vance 1987: 36)? If <ong.on> was [õũon], the vowel [ũ] would not be as opaque as a consonant; it would let the labiality of the preceding vowel pass 'through' into the suffix but not its height (which is why <ta.ang.en> above is not *<ta.ang.an> with a low-vowel stem and suffix).
Examples of 'opacity' and 'transparency' in Asian phonology:
In Sanskrit Kṛṣṇena 'by Krishna', retroflexion spreads from ṛ to the adjacent sibilant and nasal but not to the n of the final syllable. Paradoxically, although ṣṇ became retroflex, they are 'opaque' and prevent retroflexion from spreading to the n of the instrumental suffix.
On the other hand, m in Rāmeṇa 'by Rama' is 'transparent', and retroflexion spreads 'through it' and into the n of the instrumental suffix.
In Khmer, vowels developed differently after voiceless and voiced consonants. *kʰɛr would normally become [kʰmae] and *mɛr would normally become [mɛ]. Yet *kʰmɛr 'Khmer' became ខ្មែរ [kʰmae] rather than *[kʰmɛ] because *m was 'transparent' and allowed *kʰ to condition the warping of the vowel.
On the other hand, *ɟ was 'opaque', so *kʰɟɛŋ 'move apart' became *[kʰcɛːŋ] rather than *[kʰcaeŋ] with a warped vowel.
In Thai, tones developed differently after aspirated, unaspirated, and voiced consonants. *kʰɛːn would normally become [kʰɛ̌ːn] with a rising tone and *mɛr would normally become [mɛːn] with a mid tone. Yet *kʰamɛːn 'Khmer' became เขมร [kʰà mɛ̌ːn] with a rising tone rather than *[kʰà mɛːn] with a mid tone because *m was 'transparent' and allowed *kʰ to condition the rising tone on the stressed second syllable. (Unstressed short syllables with voiceless initials developed low tones.)
On the other hand, [t] in ขตอย [kʰà tɔːj] 'scorpion' (also a loan from Khmer) is 'opaque', so the second syllable has a mid tone rather than a rising tone.
*8.11.2:39: Kane (2009: 36) gives 'tomb' and 'tomb cut into a mountain' as alternative glosses for 006 <MOUNTAIN>.
16.8.9.23:59: KHITAN <UL.ÚN> (PART 1)
In my last post, I mentioned the Khitan verb
244-076-261-090-366-144 <s.gho.l.ó.ul.ún> (epitaph for 蕭敵魯 Xiao Dilu [1061-?]* 17.24, 1114)
containing a yang character <gho> ending in the perfective suffix <ul.ún>. I proposed that <ul.ún> might be invariable: i.e., that it didn't have allomorphs like its rough equivalents in its sister Mongolian and Manchu, the descendant of its neighbor Jurchen:
Mo yabu-lugha 'has gone' (allomorph after yang stems)
Mo ükü-lüge 'has died' (allomorph after yin stems)
Janhunen (2003: 24) reconstructed this ending (his 'confirmative [praesens perfecti]') as Proto-Mongolic *-lUxA. Do this ending and the Khitan ending go back to a Proto-Khitan-Mongolic *lU with different suffixes? The Khitan suffix added to *lU might be the nominalizer or participle suffix (?) <ún> after the causative/passive <l.ge> in
254-257-261-349-144 <tem.l.ge.ún> 'awarded' (?) (蕭令公 14.1; see below for more forms of this verb)
Ma susa-ha 'died' (allomorph after yang non-o stems)
Ma gene-he 'went' (allomorph after yin stems)
Ma o-ho 'became' (allomorph after yang o-stems)
I was certainly partly wrong - a price of writing in haste - as the suffix is actually /lUn/ (I use a capital letter to indicate uncertainty about the vowel), and the preceding vowel, if any, depends on the preceding stem, as I will demonstrate in a later part. But so far I do think <ún> is invariable. Here it is following the yin passive suffix <l.ge>:
247-257-261-349-261-144 <tem.l.ge.l.ún> (Kane 2009: 146; source not given) ~ 254-257-261-349-261-144 <d.em.l.ge.l.ún> (蕭仲恭 8.16) 'was awarded'
It seems that Khitan vowel harmony might be obligatory within a root but is only obligatory in certain suffixes - and /lUn/ is not one of them. If Khitan had stress (a detail not indicated in its scripts), roots might have had primary and secondary (and even teritary?) stress whereas suffixes were unstressed and sometimes may have contained neutral vowels that by convention were written with yin characters. (So far I haven't seen any invariable suffixes with yang characters.)
8.10.2:25: The invariable Manchu accusative suffix be [bə] is a merger of Jurchen
<ba>, <be>, and <bo>.
Invariable Khitan suffixes may be the results of similar mergers: e.g.,
<er> [ər] (accusative-instrumental) < *ar, *ər, *or?
/lUn/ (perfective) < *lʊn, *lun?
The merger of vowels into schwa is of course not limited to harmonic 'Altaic' languages. English is full of unstressed schwas with multiple origins.
16.8.8.23:58: WHAT IS KHITAN SMALL SCRIPT CHARACTER 342 DOING IN NATIVE WORDS? (PART 3)
Having examined all instances of 342 in Qidan xiaozi yanjiu, I moved on to Wu and Janhunen 2010 which has one word beginning with 324:324-090-262 <yên.ó.ui> (epitaph for 蕭敵魯 Xiao Dilu [1061-?]* 17.22, 1114)
W&J (2010: 95) transliterated this as <üen.ó.ui> and identify it as being in the middle of a sentence, but did not go further than glossing the finite past tense (perfective in my view) suffix <ul.ún> in the sentence-final verb
244-076-261-090-366-144 <s.gho.l.ó.ul.ún>:
The overall meaning of this and the preceding section remains obscure.
W&J 2010 is full of variants of that sentence. At this point it is often simply impossible to do much more with Khitan than to spot finite verb endings and use them to divide unpunctuated text into sentences.
Using my simpliistic yin/yang test and assuming that 076 <gho> is yang, I tentatively regard all other characters in the verb above to be either yang or neutral.
I hypothesize that <ul.ún> could be an invariable suffix like the accusative/instrumental suffix
<er>.
I will provide supporting evidence in my next post.
There is no doubt that 244 <s> and 261 <l> are neutral since they combine with both yin and yang characters. Here they are with the yin characters <g> and <ge>:
244-144-334-261-349-144 <s.ún.g.l.ge.ún> (興宗 20.16, 蕭令公 11.18)
144 <ún> is presumably in the root <s.ún.g> of that verb (<l.ge> is a passive/causative suffix), so I guess that it might be inherently yin in roots (since <g> is yin), though it could appear with roots of all types as part of the suffix <ul.ún>.
Going back to the word with 234, perhaps it was pronounced something like [jɛnɔwi] or [jɛnɔ(ː)j]. I am not sure how to interpret the sequence <ó.ui>. The final [i] or [j] may be a converb suffix. If there is a [w], it may be from a lenited *-b-: cf.
<tau> 'five'
which is cognate to Proto-Mongolic *tabu/n.
8.9.0:26: Janhunen (2003: 6, 397) does not reconstruct *w for either Proto-Mongolic or pre-Proto-Mongolic. Although Khitan is a para-Mongolic language - a sister to the Mongolic languages - there is no guarantee that it too lacked an original [w]. Nonetheless for now I hypothesize that all instances of [w] in Khitan are either in loanwords or transcriptions such as
070-131 <w.u> < Liao Chinese 武 *wu 'martial'
or are secondary: e.g., from *b or in intervocalic hiatus.
*Not to be confused with an earlier, more famous 蕭敵魯 Xiao Dilu (879?-918) who died almost a century earlier.
16.8.7.23:57: WHAT IS KHITAN SMALL SCRIPT CHARACTER 342 DOING IN NATIVE WORDS? (PART 2)
I thought this series of posts might have five or so parts, but there may be as few as three. I went through all the instances of small script character 342
in the corpus in Qidan xiaozi yanjiu and only found two instances of it in non-Chinese (and hence possibly native) words that I didn't list in part 1. One is 342 by itself; another is
324-335-084 <yên.ya.ar> (or <yên.ya.ra>?)
which raises the following questions:
1. Did Khitan distinguish between /ɲa/ and /nja/? Was <yên.ya> phonemically /jeɲa/ or /jenja/? Could it also have been written with
222 <ń>?
2. It seems that at least some Khitan CV characters can also double as VC characters (cf. 𐰹 <oq/uq/qo/qu> and 𐰜 <ök/ük/kö/kü> in Old Turkic). Is the final character 084 <ar> or <ra>? If 084 was <ar>, how did it differ from
123 <ar>?
123 <ar> can be a perfective ending. If 084 is also <ar>, could it too be a perfective ending for a verb whose subject may be the immediately preceding phrase
085 131-236 133-118 <SIX u.ru m.qú> '? [of] the six divisions'?
8.8.0:33: Could 133-118 <m.qú> be a shorter spelling of
133-253-118 <m.o.qú> 'first' (itself a derivative of
133-186 <m.o> 'big, great' [m.])?
If so, then maybe <m.qú> is an adjective modifying a noun <yên.ya.ar>/<yên.ya.ra>, and the final <ar>/<ra> is not a perfective suffix.