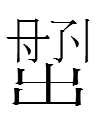
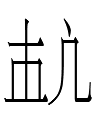
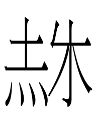
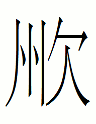15.4.11.23:54: THE LATE GREAT CHU
Today I downloaded the latest version of Andrew West's BabelStone Han PUA font containing 194 楚 Chu script transcription characters.
In 1127, 1350 years after the fall of the original Chu and less than a decade after the creation of the Jurchen (large) script, the Jurchen Empire established 大楚 Great Chu as a buffer between them and the Southern Song. This puppet state only lasted a month.
How would the Jurchen have written 大楚 *Dai Cu 'Great Chu' in their then-new script?
There were two different types of Jurchen graphs for dai.
Jin and Jin (1984: 81, 136) only list a single word-final example for one type:
<ja.hu.dai1> 'the name Jahudai'
The other type was much more common and used to transcribe Jin Chinese 大 *dai 'great' as well as representing the syllable dai in the native Jurchen names
<dai2.ju.hu> and <dai2.su> (Jin and Jin 1984: 5)
What was the original reasoning behind having two graphs for the same syllable? Were they originally nonhomophonous? My guess is that the common <dai2> was read as dai from the start, whereas the rare <dai1> was originally for some other syllable that merged with dai: e.g., *daai.
Was there also been a lost phonetic distinction between the two kinds of <cu>? Both could be used to write native words, and both even appeared side by side in
<cu1.cu2.wa.hai> 'according to'?
But only <cu2> appeared in Chinese transcriptions, so I conclude that *Dai Cu would have been written as
<dai2.cu2>.
4.12.2:42: <cu2> could represent the monosyllabic auxiliary verb cu- 'to be able' (Jin and Jin (1984: 81, 259). Perhaps <cu2> was originally a logograph for that verb, whereas <cu1> may have a phonogram from the beginning.
<dai2> resembles Chinese 大 *dai 'great' and could have initially been intended to write that word (and homophonous Chinese loanwords?), unlike <dai1> which might have been reserved for dai in native words.
15.4.10.23:59: PROTO-SINO-TIBETAN-AUSTRONESIAN *PONUQ 'BRAIN'?
Old Chinese (OC) 腦 *nuʔ 'brain' was a type A syllable* with vowel lowering. According to my theory, *u partly lowered to harmonize with a low unstressed vowel in a lost presyllable:
*Cʌ-nuʔ > *Cʌ-nouʔ > *nouʔ > *nauʔ > Mandarin nao
However, Laurent Sagart (2002: 5) regarded 腦 *nˁuʔ 'brain' as cognate to Proto-Austronesian (PAN) *punuq with a high first vowel *u. If OC had a high presyllabic vowel in 'brain', it would have matched the high main vowel, and there would have been no lowering:
*pu-nuʔ > *nuʔ > *ɲuʔ > Mandarin *rou
Can both Laurent and I be right? PAN had only four vowels (*a *e [= *ə] *i *u), whereas OC had six (*a *e *ə *i *o *u). Laurent (2002: 8) reconstructed seven vowels in Proto-Sino-Tibetan-Austronesian (PSTAN) to account for the following correspondences in main vowels:
| PSTAN | Environment | OC | PAN |
| *u | before labials | *ə | *u |
| elsewhere | *u | ||
| *o | before labials | *a | |
| elsewhere | *o | ||
| *a | before *y | *i | *a |
| elsewhere | *a | ||
| *æ | (everywhere) | *e | |
| *e | after grave consonants | *e | |
| elsewhere | *i | ||
| *ə | (everywhere) | *ə | |
| *i | in open syllables | *i | |
| in closed syllables | *i |
I only reconstruct two vowels in OC presyllables: high *ɯ and low *ʌ**. I have long thought each resulted from the merger of various unstressed vowels. Let's suppose that those earlier vowels were identical to the seven vowels in PSTAN final syllables:
| PSTAN | OC | PAN |
| *i | *ɯ | *i |
| *u | *u | |
| *ə | *e | |
| *e | *ʌ | |
| *æ | *a | |
| *a | ||
| *o | *u |
Above I assume that PAN first vowels developed more or less like second vowels. A study of OC syllable types and PAN fist vowels may reveal a different course of development.
My OC *ʌ could be from PSTAN *o which raised to *u in PAN:
*ponuq > OC *pʌ-nuʔ and PAN *punuq 'brain'
4.11.1:10: If OC and PAN are not related, the word could be a borrowing from one into the other when the source language had *o as the first vowel.
4.11.1:35: Of course OC is not the only Sino-Tibetan language. STEDT lists nu-words for 'brain' in other languages. The Proto-Sino-Tibetan form may have ended in a *-q that
- was retained in Proto-rGyalrongic
- became *-k in some languages: e.g., Written Burmese ūḥnok
- became a glottal stop in OC
- was lost in Tangut

0118 and 0127 2no1 < *noH 'brain'
Was the mid vowel in some of these forms lowered before *-q? Jacques' (2004: 266) Proto-rGyalrongic reconstruction does not have *-uq. Maybe there was a chain shift: *-uq > *-oq > *-ɔq.
4.11.2:17: I am agnostic about PSTAN. Currently I think Austronesian is more likely to be related to Kra-Dai than to Sino-Tibetan.
If the correspondences above are valid, they do not entail a genetic relationship. They may tell us about patterns of borrowing.
Conversely, if the correspondences are due to common ancestry, exceptional forms may have been borrowed after a split (cf. how the loanword paternal has p instead of the regular Germanic f from Proto-Indo-European p).
*4.11.1:56: Type A syllables were characterized by secondary pharyngealization (a.k.a. 'emphasis') at some point. I do not know of any other Sino-Tibetan language with pharyngealization. I suspect that pharyngealization was a Chinese innovation which may have been due to contact with a substratum or neighboring language. I have omitted pharyngealization in this discussion to focus on the vowels.
**4.11.2:15: I got the symbols *ɯ and *ʌ from my phonetic notation for Middle Korean which had a two-class height harmony system like my Old Chinese reconstruction. I chose them because they are visually distinct from the letters for my six vowels. Their actual phonetic values may have overlapped with two of the vowels: e.g., they could have been *ə and *a. It is easier to type *ɯ than a phrase like "unaccented presyllabic higher vowel" or *ə̆ with a breve.
15.4.9.23:59: DO AUSTRONESIAN AND SINO-TIBETAN SHARE A WORD FOR SETARIA ITALICA?
Today I saw Laurent Sagart's "Austronesian and Sino-Tibetan words for Setaria italica and Panicum miliaceum: any connection?" (2014) and was surprised to see him mention Khitan in a paper about prehistory (emphasis mine):There is a complication with the semantics of this comparison: certain modern authors (Li 1983:29; Hu 1984; Chai et al. 1999:9) claim jì 稷 did not mean 'Setaria italica' in early Chinese but 'Panicum miliaceum'. This view, widespread among Chinese agronomists, is based on statements by various Chinese authors from c. 1000 CE down to modern times, to the effect that jì 稷 is the same plant as 穄 *[ts][a][t]-s > tsjejH > jì ‘Panicum miliaceum’. Thus Chai et al. (1999:9) observe that in the three provinces of Shandong, Henan and Hebei, (glutinous) Panicum miliaceum varieties are today usually referred to as jì 稷.
However, this is a confusion arising from the phonetic convergence of these two words after Middle Chinese (a standard reading pronunciation from the sixth century CE, known to us through the dictionary Qie Yun 切韻, prefaced in 601 CE, and its later editions). In Modern Standard Chinese, Middle Chinese (MC) 稷 tsik and 穄 tsjejH have both evolved, quite regularly, to jì [ʨi 51]. The merger had already occurred in northern Chinese during the Khitan or Liao dynasty, which occupied parts of north China, including Hebei, from 916 to 1125 CE. Phonetic transcriptions in Khitan small script of the 11th and 12th century Chinese show that while MC final -k was still represented by a glottal stop in poetry, it had disappeared in everyday speech (Kane 2009:252sq.). thus in everyday Chinese of the Khitan period, 稷 'Setaria italica', MC tsik, was probably [tsi]. At the same time, the character 祭, a MC homophone of 穄 'Panicum miliaceum' on Middle Chinese (both MC tsjejH), and the phonetic element in 穄 'panicum', was also [tsi] (Shen 2014:318). It is significant that there are no statements equating 稷 tsik and 穄 tsjejH from time periods preceding the phonetic merger of the two forms [i.e., from before c. 1000 CE]. Thus we can be satisfied that 稷 tsik and 穄 tsjejH were distinct cereals in early Chinese times, and that (since there is no question that jì 穄 meant ‘panicum’) jì 稷 tsik must be the name of Setaria italica.
I would like to add that Kane's argument is based on Chinese-internal data: the poetry in question is in Chinese, and the loss of final glottal stop is implied in 沈括 Shen Gua in 夢溪筆談 Mengqi bitan 'Dream Pool Essays' (1088; Kane's translation):
Even now the Heshuo [= Hebei; i.e., north of the Yellow River] people pronounce 肉 [*zhiwʔ] as 揉 [*zhiw], and 贖 [*shu] as 樹 [*shu].
In the Khitan small script,
[g]enerally speaking there is no consistency in the use of the graphs used to transcribe syllables which ended in stops in MC and probably a glottal stop in Song Chinese. This does not prove that Liao Chinese did not have a glottal stop in such words, just that the Kitan [= Khitan] transcription does not indicate it. (Kane 2009: 254)
For instance, the Khitan small script character
339 <i>
was used to transcribe syllables whose MC readings ended in -i and -it (both corresponding to Song *-iʔ). The one instance of a word whose MC reading ended in -ik like 稷 tsik 'Setaria italica' was written as
087 <tz>
which also transcribed the open syllables 知 *ji (MC trje) and 旨*ji (MC tsyijX).
The Sino-Tibetan forms for Setaria italica look like a good match for Proto-Austronesian *beCeŋ (*e = [ə]) with the exception of the coda:
Probable Tibeto-Burman cognates of the Chinese word [稷 Old Chinese *[ts]ək] are Trung tɕjaʔ55 ‘millet’, Lhokpu cək ‘Setaria italica’ (van Driem, p.c. to LS, June 24, 2004; not phonologized): if the shape and semantics of this last form are confirmed, the Proto-Sino-Tibetan word for 'Setaria italica' might sound something like #tsək (pre-reconstruction).
Both Proto-Sino-Tibetan (PST) and Proto-Austronesian (PAN) had . I would expect the following correspondences which are in Sagart (2002: 7):
OC (and probably also PST) *-k : PAN *-k
OC (and probably also PST) *-ŋ : PAN *-ŋ
Yet Sagart also found examples of the correspondence
OC (and probably also PST) *-k : PAN *-ŋ
which has Sino-Tibetan-internal parallels: e.g.,

Tangut 1siw4 < *sik, Written Burmese sac < *sik : OC 新 *sin < *siŋ? 'new'
I presume there is morphological variation within Sino-Tibetan. But if the Sino-Tibetan and PAN forms for Setaria italica are related, how can the different codas be explained? Are they different reductions of *-ŋk, a cluster lost in ST and PAN?
Genetic scenario:
Proto-ST-AN *-ŋk > PST *-k but PAN *-ŋ
Nongenetic scenario (i.e., borrowing):
pre-PAN *-ŋk > borrowed as *-k in PST but became *-ŋ in PAN
4.10.4:40: The first vowel of PAN *beCeŋ (*e = [ə]) is consistent with my theory that presyllables with higher vowels (*i, *ə, *u) conditioned type B syllables in Old Chinese such as 稷 Old Chinese *[ts]ək].
Sagart (2002: 8) found the following correspondences between OC syllable types and PAN segments:
OC type A : PAN penultimate syllable initial voiceless stop (except *q-) or zero (i.e., no penultimate syllable)
OC type B : other PAN penultimate syllable initials including *q-
If PAN preserved Proto-ST-AN penultimate syllable initials, I do not understand why bare syllables and syllables preceded by voiceless stops developed type A with pharygealization. And why would *q- block pharygealization which was the default (!) development? (Normally pharygealization is marked: i.e., nondefault.)
PSTAN *(tV)CV > OC *CˁV (type A)
PSTAN *qVCV, *sVCV, *nVCV > OC *CV (type B)
In Semitic terms, type A is 'emphatic', and Semitic q is an 'emphatic' consonant, so I would expect it to be associated with type A.
15.4.8.23:59: DID KOREANS WRITE THEIR OWN LANGUAGE IN THE KHITAN SMALL SCRIPT?
Last night I found these translated sections of the History of the Liao Dynasty translated in Wittfogel and Fêng (1949: 261):
戊辰,高麗遣童子十人來學本國語。
On the day mou-ch'ên [of the eleventh month in the thirteenth year of T'ung-ho [= 995 AD*] ] Korea sent ten boys to study the [Ch'i-tan [= Khitan] ] national language.
庚戌,高麗復遣童子十人來學本國語。
On the day kêng-ch'ên [sic for kêng-hsü] [of the third month in the fourteenth year of T'ung-ho [= 996 AD] ] Korea again sent ten boys to study the [Ch'i-tan [= Khitan] ] national language.
歸州言其居民本新羅所遷,未習文字,請設學以教之,詔允所請。
[On the day chia-shên of the twelfth month in the first year of K'ai-t'ai [= 1012 AD] ], Kuei Prefecture reported that its inhabitants, who had originally been moved from Silla [= Korea], were illiterate, and that schools should be set up to educate them. This request was approved by imperial decree.
I wondered which Khitan script(s) those Koreans learned: the large script, the small script, or both.
David Boxenhorn suggested that those Koreans might have tried to write their own language in the small script. That would have been easy to do, since Korean a thousand years ago
- had *CV(C) syllables like Khitan without the consonant clusters of a few centuries later (and even such clusters coud have been written with sequences of small script consonant symbols)
- had roughly the same consonants as Khitan minus the uvulars
- shared most of its vowels with Khitan (*i, *e [> later Korean yŏ], *ə, *a, *u, *o)
Only the apparent absence of the vowels *ɯ and *ʌ (> later Korean a/ŭ) in Khitan might be a problem. Existing CV, V, and VC characters could do double duty for those vowels: e.g.,
273 <un>
could represent both Korean *ɯn as well as *un. That would parallel the current use of the Roman letter u to transcribe both Korean [ɯ] and [u]: e.g., Kim Jong-un is [kimdʑəŋɯn].
Also, dots could be added to indicate non-Khitan uses of characters, just as the Khitan added a dot to <pu> to write the Chinese syllable <fu>:
>
241 <pu> > 261 <fu>
4.9.3:13: David's scenario makes me wonder if the Jurchen used the small script to write their language.
When I saw this passage in Wittfogel and Fêng (1949: 253),
In 1150 a distinguished Jurchen statesman is said to have written a confidential political letter to his son in the small Ch'i-tan script; this interesting document, translated into vernacular Chinese, is preserved in the Chin Shih [= History of the Jin Dynasty] (CS [= Chin shih 76, 2a ff.; 84, 3a ff.).
I wondered if the statesman wrote in Khitan or in Jurchen using the Khitan small script. Wittfogel and Fêng raised the possibility of the latter:
Many Chin records describe the continued use of the Ch'i-tan script during the early and middle years of the Chin dynasty. Unfortunately, they do not make it clear whether this also involved the use of the Ch'i-tan language. There must have been a number of Jurchen who spoke Ch'i-tan, but the question still arises whether such knowledge was necessary to the use of the Ch'i-tan script. In the formative period of their power the Mongols wrote their documents in the Mongol language but in the alphabetic Uighur script (Browne 28 II, 441; cf. Barthold 28, 41). The Manchus until the year 1599 wrote their documents in Mongol and used the Mongol script (KHTSL 3, 2a-b). The Jurchen may have availed themselves of either method exclusively, or of both at different periods of time, first adopting an alien language and script and later using the alien script for transcribing their own language. In the latter case the smaller script would seem particularly appropriate, for as an alphabetic system of writing it could easily be adjusted to the needs of another language, especially if this language belonged to the same Altaic complex [as Korean does!]
*4.9.2:49: Although I suspect the eleventh month of Tonghe (= T'ung-ho) 13 is in the start of 996 AD, Wittfogel and Fêng referred to 995 AD in their footnote (emphasis mine):
This record is confirmed by the Korean official history which relates that in 995 the Korean government sent ten boys to Liao [the Khitan Empire] to study the Ch'i-tan language (KRS [= Koryŏ-sa 'History of Koryo'] 3, 46). However, this effort seems to have produced very poor results. In 1010, when the Liao vanguard general sent a document written in Ch'i-tan to the Korean court, no one could read it (KRS 94, 86).
Did any of the ten boys return as men to serve the court, and if so, were any of them still at the court in 1010?
4.10.4:54: Andrew West pointed out that the eleventh month of Tonghe 13 is equivalent to 25 November-24 December 995, so Wittfogel and Fêng's date is correct.
15.4.7.23:59: THE LID OF THE EPITAPH OF XIAO ZHONGGONG (1150)
I wanted to see 'on the tomb' from my last post in context, so I looked at the text on the lid of the epitaph for 蕭仲恭 Xiao Zhonggong as copied in Qidan xiaozi yanjiu (1985: 594):
1. 139-051-290-253 <na.gha.án.ô>
2. 188-169 <?.qó>
3. 081-140 <MONTH.en>
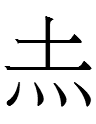
4. 081-348 <MONTH.e>
5. 334-262 <g.ui>
6. 071 <ong>
7. 076-020-361-140 <gho.y.én.en>
8. 251-084-205 <n.ra.de>
9. 052-334-361 <?.g.én>
Let's go through it block by block:
1. Kane 2009 (51, 106) translated

139-051 <na.gha> and 139-051-290 <na.gha.án>
as 'uncle' and 'maternal uncle' (cf. Written Mongolian naghachu 'maternal uncle'; Ji Shi 1982). Neither occur alone in Qidan xiaozi yanjiu's index of Khitan small script words. Have they been found in isolation in the texts discovered in the three decades since the publication of that book?
Could 290 <án> be the plural suffix also in

311-151-290 <b.ugh.án> 'children' < 311-168 <b.qo> 'son, child'
which also has unexpected medial voicing in the plural? Is -gh- a contraction of *-qw- < *-qo-?
The final character
252 <ô>
is an error for
341 <er>
which Kane (2009: 106) regarded as the invariable (and in this case, nonharmonic) accusative-instrumental suffix ('via the maternal uncle'?). However, I would expect the genitive: 'junior tent of the maternal uncle'.
Could <er> be a plural suffix?
<
?
222-362-222-341 <ń.iau.ń.er> 'siblings' < 222-362 <ń.iau> 'sibling'?
is another plural ending in <er>, though the suffix may be <ń.er>. I don't know of any plural suffix <ń>, so I don't think <.ń.er> is a double plural suffix.
Could <er> be a plural genitive suffix if <na.gha.án> is a singular?
Could <na.gha.án.er> be a doubly marked plural like Japanese ko-domo-tachi, English child-r-en, and Dutch kind-er-en (cf. German Kind-er with only one suffix)?
2. <?.qo> is 'junior' (Kane 2009: 25). Kane interpreted this as an adjective modifying the previous noun ('junior maternal uncles'), though if that was the case, it would be in an un-'Altaic' position: i.e., following instead of preceding hte noun.
Aisin Gioro read the first character
188 <?>
as <od> in 2004 and as <oji> in 2011. If it is <od>, how did it differ from
and
which Aisin Gioro read as <ad> ~ <od> and <od> ~ <do>?
3.
081 <MONTH>
is an error for

380 <TENT>.
Kane (2009: 25) translated blocks 1-3 as 'the tent of the junior maternal uncles'; I would add an 'of' before 'the' to correspond to the genitive suffix
140 <en>.
4.
081 <MONTH>
is an error for
082 <yw>
with a dot. Hence <yw.e> is a transcription of the Liao Chinese name 越 *Ywe.
5. Transcription of Liao Chinese 國 *gueiʔ 'state'*.
6. Transcription of Liao Chinese 王 *ong 'prince'.
Blocks 4-6 means 越國王 'prince of the state of Yue'.
7. 076-020 <gho.y> may be a verb stem.
361 <én> could be a nominalizing suffix, though I would not expect <é> after <gho.y> if Khitan vowel harmony was like Mongolian or Manchu vowel harmony.
Is 140 <en> a genitive before 'tomb': 'on the tomb of ...'?
8. 'tomb-LOC': 'on the tomb'.
9. Kane transcribed 052 as <RECORD>, and stated that it "is only found in the word
[052-334] <RECORD.gi> [= my <g>] 'record'
with various suffixes." However, it can occur in isolation and with characters other than 334, though it cannot occur in noninitial position (Qidan xiaozi yanjiu 1985: 201-202, 690-691). That suggests 052 is not a logogram. Aisin Gioro read it as <cu> in 2004 and <ce> in 2011.
361 <én> is a nominalizing suffix. Kane (2009: 155) translated 052-334-361 <?.g.én> as 'inscription'.
*4.8.3:48: Although the Khitan may have borrowed Liao Chinese 國 as gui [guj], I suspect the Liao Chinese pronunciation was *gueiʔ [kwəjʔ]. In Middle Chinese, 國 was *kwək, and has developed in at least two different ways in modern Mandarin dialects:
1. *kwək > *kwəɰk > *kwəɰʔ > *kwəjʔ > [kwej] (e.g., Jinan)
2. *kwək > *kwəʔ > [kwo] (e.g., Beijing)
Forms like Linquan [kwɛ] or 13th century Phags-pa Chinese ꡂꡟꡠ <gue> may be from either *kwəjʔ or *kwəʔ with fronting of the schwa.
The Khitan borrowed from a dialect with the first path of development.
Prescriptive 15th century Sino-Korean 귁 kuyk might be a conscious compromise between actual Sino-Korean 국 kuk and Ming Mandarin [kuj].
15.4.6.23:54: THE TOMB OF VOWEL HARMONY
According to my harmonic unwritten vowel hypothesis,
251-084 <n.ra> 'tomb'
in the Khitan small script was read nara without the apparent harmonic violation of Kane's (2009: 123) nera. So far, so good. But the dative-locative suffix for 'tomb' is de, not *da:
251-084-205 <n.ra.de> 'tomb-LOC'
This is not an isolated spelling. It occurs seven times in four texts over a span of a century:
- twice in 蕭令公 (1.10, 26.14; 1057)
- once in 許王 (2.17; 1105)
- once in 耶律撻不也 (1.10; 1115)
- thrice in 蕭仲恭 (lid 3.2, 1.8, 44.38; 1150)
I wonder if there are even earlier occurrences. Did the harmonic form *nara-da ever exist: e.g., at the time of the invention of the small script c. 925?
Here are other examples of seemingly nonharmonic dative-locative -de:
051-251-205 <gha.n.de> '?-DAT/LOC'? (蕭令公 12.17) instead of *ghan-da (assuming ghan is the stem though it is not attested in isolation)
071-205 <ong.de> 'prince-DAT' (蕭仲恭 4.51) instead of 071-217 <ong.do> (quoted in Kane 2009: 137; source not specified)
076-189-099-205 <ogh.a.ad.de> '?-DAT/LOC' (耶律撻不也 21.1) instead of *ogha(a)d-da
141-205 <dolo.de> 'seven-LOC' (蕭仲恭 8.12) instead of *dolo-do
But -de is expected if Aisin Gioro's (2004, 2005) reconstruction of 'seven' as dil is correct.
248-118-205 <jal.qú.de> '?-DAT/LOC' (許王 50.17) instead of *jalqu-du
The reading <jal> is from Aisin Gioro (2004).
Was nara-de a harbinger of the ultimate fate of the Khitan dative-locative? If Khitan had survived, would it have an invariable -de [də], just as the Jurchen dative-locative suffixes
<do> and <du> (= Kiyose's dö)
merged into Manchu de [də]? Could such an invariable -de already have existed in late colloquial Khitan, emerging occasionally in texts that otherwise reflected harmonic allomorphy lost in speech?
4.7.0:56: Khitan had an invariable accusative-instrumental suffix -er, though the homophonous perfective suffix had -ar and -or allomorphs (Kane 2009: 131, 145-146). Would as yet undiscovered 10th century small script texts also have accusative-instrumental -ar and -or? Why did merger occur in the accusative-instrumental before the dative-locative? Was disambiguating the former from a homophonous verb suffix a factor?
Unlike Khitan, Jurchen had three allomorphs of the accusative suffix:
~
<ba> (written with two types of characters), <be>, <bo>
All three merged into Manchu be [bə].
15.4.5.23:09: DID THE KHITAN SMALL SCRIPT HAVE HARMONICALLY PREDICTABLE UNWRITTEN VOWELS?
On Friday I was looking for the name of Yelü Abaoji's father
244-084-051-099-222 <s.ra.gha.ad.ń>
transcribed in Chinese as 撒剌汀 *saʔlaʔding or 撒剌的 *saʔlaʔdiʔ* in Kane (2009). Last night I found it on page 129. I also rediscovered my 2014 post on the name.
Last year I interpreted 084 as ar and read the name as Sargha(a)diń. But if 084 was ar, what was the difference, if any, between it and 123
which also represented ar?
Kane (2009: ) read 084 as ra and tentatively reconstructed an inherent vowel e in 244. Hence he read the name as Seraghadiń. The coexistence of e and a is unexpected in Mongolic or Jurchen/Manchu. There is no guarantee that Khitan vowel harmony was like Mongolic or Jurchen/Manchu vowel harmony, but the limited evidence suggests some degree of similarity. So I am skeptical that the name contained an e. However, other alternatives also have problems: e.g., Sargha(a)diń above. A zero-vowel interpretation of 244 results in Sragha(a)diń with an un-'Altaic' (and hence unlikely) initial cluster. The Chinese transcriptions cannot help us, as Liao Chinese had no *se or *sr-, so 撒剌 *saʔlaʔ- could represent Khitan Sar-, Sera-, or Sra-.
A fourth possibility is that the name was Saragha(a)diń with an unwritten first vowel. Were Khitan small script readers able to supply unwritten vowels with the aid of vowel harmony rules? Perhaps 244 was read as s, sa, or se depending on context. In this case, it was read as sa because sr- would be an impermissible initial cluster and sera- would violate vowel harmony.
Similarly,
244-084-254 <s.ra.d> '?' and 251-084 <n.ra> 'tomb'
which Kane read as serad and nera would be read as sarad and nara according to my harmonic hypothesis.
In these cases, the reader would have to look ahead to determine whether the vowels of 244 <s> and 251 <n> would be a or e.
Conversely, readers of the traditional Mongolian script keep previous vowels in mind to disambiguate later vowel letters: e.g., the second vowel letter of
ᠡᠵᠡᠨ
<eja/en> 'lord'
has to be read as e because the first vowel is e. Although a medial a looks exactly the same as a medial e, *ejan would violate vowel harmony.
*撒剌的 is from the History of the Liao Dynasty. I don't know where Kane (2009: 129) found 撒剌汀.