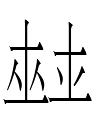
![]() (~
(~![]() ~
~![]() ) and
) and ![]() ,
,
15.4.4:23:40: WHY <SA> MANY?: PART 1
I have already discussed
(~
~
) and
,
two of the eight types of Jurchen <sa>-graphs, at length in "Jurchen Polyphony 2", "That Yu-ni-kŭ Component", and "Un-<sa>rtain-'tea' ", so I will move on to the third which is only attested in two names:
the surname <sa.hala>* (女真進士題名碑 21)
the personal name <udi.sa.e>** (慶源郡女真國書碑 4:2)
Was this <sa> intended solely for use in names, or was it used to write other words absent from the few texts that we have on hand?
*4.5.1:31: Jin Guangping and Jin Qizong (1980: 311) and Jin Qizong (1984: 107) read the second character as xala = my hala. However, the entry for that character in Jin Qizong (1984: 129) listed gal as Jin Guangping's reading and does not include the surname as an example. To confuse matters further, the Chinese transcription of the name is 撒合烈 *saʔhoʔlieʔ with different vocalism that is not harmonic. I would expect something like *saʔhoʔlaʔ.
**4.5.1:35: I cannot explain the nonharmonic sequence -ae. If u and i were neutral vowels, I would expect *udisaa or *udisee. Could the name be of non-'Altaic' origin: i.e., from a language without vowel harmony? But what language would that be? The name is too long to be Chinese.
15.4.3:23:43: WHY <SA> MANY?: PROLOGUE
My previous entry dealt with the mys-'tea'-ry of why the Chinese character 茶 *cha (in Jin Dynasty pronunciation) 'tea' was used as the basis of the Jurchen character
<sa> (not <cha>!)
None of the Jurchen <ca>-characters look like Jin Chinese *cha-characters:
, so far known only in the word
for <ca> elsewhere (with a possible variant
in 女真進士題名碑)
(4.4.1:10: There is an obscure Chinese character 𠮮 attested in the Liao Dynasty dictionary Longkan shoujian with the reading *hua, not *cha. The dotted version vaguely resembles Liao/Jin Chinese 吞 *ten.)
I forgot to ask why a 茶 *cha-based character for sa was needed at all given the existence of seven other types of <sa> in the Jurchen large script:
Why wasn't one - or seven - <sa> enough?
15.4.2:23:59: UN-<SA>-RTAIN-'TEA'
Last Friday, I listed Jurchen
<sa>
as an example of a graph whose reading seemed to be of Liao/Jin Chinese origin: i.e., based on a northeastern dialect of Chinese from the 10th century onward.
<sa> appears to be a derivative of the Chinese character 茶 'tea'.
If Janhunen is right, and if the Jurchen script is derived from the elusive Parhae script, then the readings of Parhae characters would be based on pre-Liao Chinese: e.g.,a 茶-based graph would be read as something like *da (< Middle Chinese *ɖæ) or even *ra or *la (< Old Chinese *rla) if a Manchurian tradition of writing went back very far or if northeastern Middle Chinese retained an archaic liquid-initial reading of 茶.
However, <sa> has an initial fricative that matches none of the hypothetical initials of the Parhae scenario or the *ch- of the Liao/Jin Chinese reading of 茶. Nonetheless, I thought the reading <sa> was of Liao/Jin Chinese origin because <s> and *ch- are both sibilants. But why would the creator of the Jurchen script take a Chinese character pronounced *cha and use it to write Jurchen sa?
Hypothesis 1: Because the source Chinese dialect had initial *s- in 茶.Although Japanese does have the Tō-Sō-on (i.e., post-Middle Chinese) reading sa for 茶 (e.g., in 喫茶店 kissaten 'cafe'), that is not evidence for Jin Chinese *s-, because Japanese lacked an affricate at the time of borrowing, so the s- of sa is an approximation of a Chinese affricate. There are a couple of modern Chinese languages with s- in 'tea', but they are far from the northeast, and their s- might be of recent origin: Qinglong Ping sa and Shitai Wu sʰa.
Hypothesis 2: Because the source Chinese dialect had initial *tsʰ- in 茶.
According to xiaoxue.iis.sinica.edu.tw, some modern Mandarin varieties including Beijing (presumably the colloquial accent as opposed to the Beijing-based national standard) have tsʰ- in 茶. There was no tsʰ- in Jurchen, so the Jurchen might have perceived tsʰ- as s-. But the tsʰ- of 茶 might be of recent origin like s-.
Hypothesis 3: Because of a sound change in Khitan.
Jurchen/Manchu has both sh- and c- corresponding to Mongolic c-:
'white': Jurchen/Manchu shanggiyan : Proto-Mongolic *cagaxan (Janhunen 1996: 197)
'army': Jurchen cau(r)-, Manchu cooha : Middle Mongolian ca'ur 'to fight' (Kane 2006:
My guess is that the sh-forms were borrowed from a nonstandard Khitan dialect (Eastern Khitan?) whose speakers were in close contact with the Jurchen, whereas the c-forms were borrowed from a more prestigious variety of Khitan.
Could Jurchen <sa> be based on a Khitan large script character whose reading shifted from cha to sha due to deaffrication in Eastern Khitan?
There are two problems with this scenario. First, I do not know of any Khitan large script character resembling 茶. The shape of <sa> is either a Jurchen innovation or a carryover from the Parhae script absent in the Khitan large script. Second, the Jurchen character was pronounced sa, not sha.
(4.3.3:10: But maybe this hurdle is not insurmountable, as
seems to have been read as both sa and shang judging from Ming Chinese transcriptions. Was <sa> ever read as sha? Conversely, was 'white' ever sanggiyan in Jurchen? Did Jurchen borrow from three kinds of Khitan dialects: one that retained c, another that weakened it to sh, and yet another that weakened it to s?)
Hypothesis 4: Because of a gap in Jin Chinese phonology.
There may not have been a *sa in Jin Chinese*, so 茶 *cha was used as the basis of <sa>**.
But even if Jin Chinese only had *saʔ with a final glottal stop, wouldn't characters with that reading (e.g., 撒薩颯卅) be a better match for *sa than 茶 *cha?
And if the Jurchen script is based on the Khitan large script (according to the mainstream view) or the Parhae script (according to Janhunen), why not carry over an existing character from one of those scripts for sa? Why create a new character for a syllable that probably existed in Khitan and whatever language the Parhae elite spoke***?
*4.3.3:18: Middle Chinese *sa became Liao/Jin Chinese *so.
I do not know whether Mandarin sa < *shai for 洒灑 can be projected back into Jin Chinese. Mandarin sa could be a borrowing from a much later dialect in which *sh- became s-.
**4.3.3:31: This kind of substitution has a weak parallel in the Old Japanese man'yōgana script. Middle Chinese 娑 *sa was a low-frequency character and prone to be misread as its phonetic 沙 *ʂæ (and in fact 娑羅双樹 can be read as shara sōju as well as sara sōju in modern Japanese). Hence the most frequent phonogram for Old Japanese sa was the high-frequency character 佐 *tsaʰ in spite of its initial. (See the frequency statistics in my 1999 dissertation and 2003 book and on Ueshiba Hiroshi's site.)
***4.3.4:06: Janhunen (1996: 152-153) doubted that Koguryo and its Parhae successor state were "likely to have been dominated by ethnic elements that would have been linguistically ancestral to the modern Koreans" and proposed that "they were dominated by people ethnically ancestral to the Jurchen": i.e., Tungusic speakers. Nonetheless the limited linguistic material available from Koguryo points to Koreanic and even Japonic rather than Tungusic.
15.4.1:23:36: DID OLD CHINESE REALLY HAVE SO MUCH *(-)R-?
Guillaume Jacques (2015: 220) wrote what I've been thinking for years now:In all modern systems of [Old Chinese] reconstruction, *-r- is reconstructed for all syllables with either second division rhyme, chongniu 3 and/or retroflex initials in Middle Chinese. While it has been convincingly demonstrated that clusters in *-r- is indeed one possible origin for these syllables (Yakhontov 1961), there is no definite proof that *-r- should be reconstructed in all cases.
I used to reconstruct a lot of medial *-r- in Old Chinese until 2006 when Zev Handel's "Rethinking the medials of Old Chinese: Where are the r's?" opened my eyes to the possibility of preinitial *r-. Over the years I have wondered if those syllables had even more sources: e.g., in 2012 I wrote that *r- "might be from earlier *l- and/or *t- as well as *r-". Classical Tibetan has preinitial l- and d- as well as r-.
Guillaume's figures confirm my suspicion that there is too much noninitial *r in Old Chinese reconstructions:
As a measure of comparison, over 20% of syllables in Old Chinese as reconstructed by Baxter and Sagart (2014) contain a preinitial or a medial *r, while in Japhug and Tibetan, where consonant clusters including r are attested, we only find respectively 12% and 16% of syllables with non-initial r.
Like Classical Tibetan, Japhug has preinitial l-. Would adding the percentage of syllables with preinitial l- raise 12% and 16% to roughly 20%? Japhug l-syllables are rare and presumably of secondary or external origin (e.g., ld- is from *rl- [Jacques 2004: 314]), as original preinitial *l- became j- (Jacques 2004: 271). Maybe the total of j-, l-, r-, and -r- syllables of Japhug might reach 20%. Do any Tibetan or Japhug preinitial (*)l- correspond to *-r- in a typical modern reconstruction of Old Chinese?
15.3.31:23:59: WERE CLASSICAL GREEK -PHTH- AND -KHTH- PRONOUNCED AS SPELLED?
On Saturday I found this blog post by Mike Aubrey:
Mussies (1971: 51) wrote (with transliteration that I added),I hold, following Mussies that these two clusters [χθ <khth> and φθ <phth>] were pronounced /kth/ and /pth/ in the Hellenistic Period.
-φθ- <phth> and -χθ- <khth> are misleading orthographies and respresent resp. -pth- and -kth-.
Aubrey added,
Non-Alveolar Stop + Aspiration + Alveolar Aspirated Stop [i.e., a sequence like phth or khth] is both difficult to pronounce and also phonologically implausible
I do not know of any modern language that allows such sequences: e.g., in Korean /ph th/ and /kh th/ would be pronounced as [ptʰ] and [ktʰ], not *[pʰtʰ] and *[kʰtʰ]. Similarly in Sanskrit, the rule is to reduce /ChCh/ to /CCh/, though
in the manuscripts, both Vedic and later, an aspirate mute is not seldom found written double—especially, if it be one of rare occurrence: for example (RV.), akhkhalī, jájhjhatī (Whitney 1889: 53; emphasis mine).
Aubrey found examples of the spelling error πθ <pth> that his theory predicts.
Are there also examples of κθ <kth> as a misspelling for χθ <khth>?
Supposing Aubrey is right. Given the fact that Classical Greek spelling is basically WYSIWYG (what you see is what you get [i.e., pronounce]), why were /pth/ and /kth/ properly spelled as φθ <phth> and χθ <khth> instead of *πθ <pth> and *κθ <kth>? The aspiration of the φ <ph> in ὀφθαλμός <ophthalmós> 'eye' is not etymological, as the final consonant of the root op- < *okʷ- < Proto-Indo-European *ʕʷekʷ- 'eye' is unaspirated. (4.1.0:49: Beekes derived this word from Pre-Greek *okʷt-alʸ-(m-). The resemblance between inherited *okʷ- and substratal *okʷt- is coincidental. In any case, the aspiration of φ <ph> is not original.)
Last night, I rediscovered Beekes' "Pre-Greek*: The Pre-Greek loans in Greek" to write "Making Machines". Beekes regarded φθ <phth> as a cluster in the substratum language that he calls "Pre-Greek"**. What if Pre-Greek allowed (allophonic***) aspirate sequences that were carried over into Greek**** and reflected in the spelling? Substratum-influenced pronunciations like [pʰtʰ] and [kʰtʰ] may have coexisted side by side with an inherited pronunciation [ptʰ] and [ktʰ]***** for a time. Then the latter dominated in speech, though the spellings with double aspirates persisted as the norm.
4.1.1:45: My theory implies that if the earliest Greek speakers had moved to Greece and there had been no one there, the clusters φθ <phth> and χθ <khth> would not exist (unless the double aspiration had been of purely Greek-internal origin), and πθ <pth> and κθ <kth> would have been the only possible spellings.
*4.1.1:07: Beekes used the prefix Pre- to refer to an unrelated substratum language, where I generally use pre- (without capitalization) to refer to a largely internal reconsruction of an unattested earlier stage of a language: e.g., pre-Tangut is ancestral to Tangut and not a substratum of Tangut.
I use Proto- to refer to the (potential) result of comparative reconstruction of the ancestor of two or more languages: e.g., Proto-Pumi-Tangut (whose existence is implied by the family tree in Jacques 2014: 2).
However, if I speak of, say, the pre-Japanese languages in the plural, I am referring to multiple substratal languages, not an earlier stage of Japanese such as Proto-Japonic.
It would be nice to have three prefixes to distinguish between the three types of earlier languages: substratal, internally reconstructed, and comparatively reconstructed.
**4.1.0:55: Beekes (2007: 12) noted that φθ <phth> was also possible in inherited words.
Although Beekes did not explictly list χθ <khth> as a Pre-Greek cluster, it does appear in words he regarded as Pre-Greek: e.g., μοχθέω 'be weary with toil'.
***4.1.1:11: According to Beekes (2007: 5), aspiration was not phonemic in Pre-Greek.
****4.1.1:19: What if Pre-Greek had fricative allophones of stops long before the Greek aspirated stops became fricatives? Pre-Greek fricatives could have been borrowed into Greek as aspirated stops.
*****4.1.1:12: I assume that the Sanskrit constraint against aspirate sequences was also in the speech of those who brought Greek to Greece.
15.3.30:23:49: MAKING MACHINES
Seeing the Spanish word máquina 'machine' made me wonder about the origins of machine and mechanism. Those two words don't sound much alike in English, and their Japanese derivatives don't even look alike, as they are written with different kana:
マシン~マシーン~ミシン
<ma.shi.n> mashin ~ <ma.shi.-.n> mashīn 'machine', <mi.shi.n> mishin 'sewing machine'
メカ(ニズム)
<me.ka.(ni.zu.mu)> meka(nizumu) 'mechanism'
They appear to be from Latin borrowings of the same Greek word from different dialects at different periods:
newer mechanismus < Attic-Ionic mēkhanḗ
The ē of mēkhanḗ is from an *ā preserved in Doric (see below and Sihler 2008: 50).
older māchina < Doric mākhanā́
Latin i is from unaccented short *a (Sihler 2008: 60), so māchina must have been borrowed as *māchana before the *a > i shift.
Watkins (2011: 52) derived mākhanā́ from Proto-Indo-European root *māgh-anā (accent unspecified) 'that which enables' with an lenghthened-grade form of the root *magh 'to be able', the source of English may and might.
In a Leiden-style reconstruction without *a, would *māgh-anā be something like *mēʕgh-eʕnēʕ with a root *√mʕgh? Is it worth it to reconstruct so many *ʕ to avoid *a?
But according to Wiktionary, Robert Beekes of the Leiden school derived the word from a pre-Greek substratum in his etymological dictionary which I haven't seen. Why couldn't mākhanā́ be from *√mʕgh?
15.3.29:23:33: THE LIMITS OF LENITION; OR, THE COMMISSIONER'S COMPANIONS
Last night I mentioned the pan-Central Asian title
053-051 <qa.gha> 'qaghan'
as an example of a non-Chinese loanword in Khitan. I wonder if its medial -gh- indicates a late borrowing.
In native Khitan words, medial *-gh- and *-b- were lost between the vowels *a and *u:
/
'hundred' *jaghu > 015 <jau>; cf. Written Mongolian jaghun
/
'five': *tabu > 029 <tau>; cf. Written Mongolian tabun
This loss enabled the graphs for 'hundred' and 'five' in both the large and small scripts to represent the Chinese loanword
<jau.tau> < 招討 'bandit suppression commissioner'.
How many other Khitan words lost their medial consonants: i.e., how many companions did the commissioner have?
At this point, I don't know whether
- *-gh- (= */g/?*) and *-b- were lost between other vowel sequences
- *-d- was also lost (or became something else**) between vowels
In other words, I don't know the limits of lenition in Khitan. Knowing those limits would enable us to date borrowings: e.g., if *-gh- was lost in the environment *a_a, then qagha must have been borrowed after that loss, just as Liao Chinese 招討 *jautau was borrowed after the loss of *-gh- and *-b- in the environment *a_u in 'hundred' and 'five'.
Qagha is certainly not native to Khitan, but what about words which might have -aghu- and -abu- sequences*** such as
189-151-123-348 <a.ghu.ar.e>**** (興宗 28.14) and 189-196-222 <a.bu.ń> (興宗 31.4)
Are these loanwords? If not, have their intervocalic obstruents been restored by analogy? Or are they of secondary origin from earlier clusters***** (e.g., *ambu > abu) or a lost series of obstruents****** (e.g., *abʱu > abu but *abu > au)?
*3.30.0:53: In pre-Khitan, *gh and *g might have been allophones of */g/ appearing before different vowels: */ga/ was *gha, */ge/ was *ge, etc. In any case, gh and g were distinct phonemes in Khitan because /ga/ was possible in Chinese loans (like Manchu g'a):
| Pre-Khitan | Khitan | IPA |
| */ga/ | /gha/ | [ʁɑ] |
| */ge/ | /ge/ | [gə] |
| ([gɑ] not possible) | /ga/ | [gɑ] |
**3.30.0:30: In Korean according to Alexander Vovin (2010), medial *-p-, *-t-, *-s-, and *-k- lenited to Middle Korean -β-, -r-, -z-, and -ɣ- which became -w/Ø-, -r-, -Ø-, and -Ø- in modern Korean. If Khitan was like Korean, then pre-Khitan *-d- might have lenited to a liquid in intervocalic position. But so far I have not seen any evidence for coronal lenition in Khitan. There was no z in Khitan, so if pre-Khitan *-s- lenited, it must have become something else.
***3.30.0:57: The rules for determining whether a graph was pronounced as VC or CV are still unknown, so perhaps those two blocks were read aughare or aubiń: i.e., without -gh- or -b- between a and u. Still other readings are possible since 123 may have been ra as well as ar, and 222 was ńi as well as (i)ń.
****3.30.1:05: If Khitan had Mongolian or Manchu-like vowel harmony, an e would not be expected in a word with a. Could *a be reduced to e [ə] in unaccented positions?
*****3.30.1:08: This was inspired by Vovin's derivation of Middle Korean intervocalic stops from earlier clusters which were mostly *nasal-stop sequences.
******3.30.1:15: In this scenario, voiced aspirates and voiced nonaspirates had distinct reflexes in intervocalic position but might have merged in other positions: e.g., *b(ʱ)- > b-, etc.