

4063 1vɪʳ (stem 1) and 4064 1vɔʳ (stem 2)
14.4.26.23:59: THE TREASURE TWINS
The Tangut verb 'to cherish, treasure, love' (from "A Treasured Tetrad") has two stems written with similar charcters:
4063 1vɪʳ (stem 1) and 4064 1vɔʳ (stem 2)
Here are examples of the use of each stem. Starred forms are reconstructions based on the paradigm in Jacques (2009: 4).
4063 1vɪʳ (3rd person subject and object; many examples in Newly Collected Biographies of Affection and Filial Piety)
*4063 4884 1vɪʳ 2ni (plural object except when both subject and object are 3rd person; see above)
(4884 does not follow stem 2.)
*4063 4601 1vɪʳ 1ŋa 'thou/you/s/he/they love(st) me' (i.e., non-3rd person subject + 1st sg. object)
*4064 4601 1vɔʳ 1ŋa 'I love' (3rd person object)
*4063 4601 1vɪʳ 2nia 'I/we/s/he/they love(s) thee' (i.e., non-3rd person subject + 2nd sg. object)
4064 4601 1vɔʳ 2nia 'thou lovest' (3rd person object; Newly Collected Biographies of Affection and Filial Piety 10.4)
In short:
| Suffix | -Ø | 1st singular | 2nd singular | Plural |
| Stem 1 |
|
|
|
|
| Stem 2 | () if suffix is elided |
 |
 |
- |
4064 is in theory only supposed to appear before first and second person singular subject suffixes unless those suffixes are elided (see Gong 2003: 617 for an example). However, the Mixed Categories of the Tangraphic Sea (4.241) and Homophones (11B46) list the verb
4063 4064 1vɪʳ 1vɔʳ 'to grow fond, pity, take good care of oneself' (gloss from Kychanov and Arakawa 2006: 358)
This seems to be an example of i-o reduplication based on stem 1 (see Gong 2003: 612) rather than a genuine case of stems 1 and 2 combined into a single word. Is this word attested outside dictionaries?
Jacques (2009: 6) traced stems 1 and 2 back to Proto-Tangut *pra and *pra-w with a third person patient suffix. Although I accept his *-ra(-w), I don't understand why he chose initial *p-. Are there internal or external cognates with p-? I reconstruct pre-Tangut
*TI-Pra > *TI-vra > *TI-vria > *T-vria > *T-vri > *T-vɪ > *r-vɪʳ > 1vɪʳ
*TI-Pra-w > *TI-vraw > *TI-vriaw > *T-vriaw > *T-vrew > *T-vro > *T-vɔ > *r-vɔʳ > 1vɔʳ
with a presyllable
- whose coronal initial *T- became *r- before the root initial and conditioned the retroflex vowel
- whose high front vowel conditioned the breaking of the main vowel; the unknown labial *P lenited between those vowels
4.27.0:28: Revised the pre-Tangut above so that *ia monophthongized to *e before *w.
4.27.0:36: Added attestations of 4063 4064 from Mixed Categories and Homophones.
4.27.0:54: Added table of all possible forms of 4063/4064.
14.4.25.23:45: A TREASURED TETRAD
Only one of the six characters in the Tangut title of the Mahāparinirvāṇa Sūtra is a transcription character:
0776 2pa for Sanskrit pa(ri)-
Its right side is a semantic compound:
+
4063 1vɪʳ 'to cherish, treasure' =
top of 4064 1vɔʳ 'to cherish, treasure' (obviously cognate to 4063; has a circular derivation with 4063 and 2417 below)
center of 2417 1ʂwɨo 'to need, want' (the bottom of 4064 above)
center of 5449 1tị 'to place, put, set up'
which occurs in only two other tangraphs which also appear to be semantic compounds:
=
+
2719 2phə 'to throw, abandon' (analysis unknown; my guess below) =
'not' < left of 1918 1mi 'not' +
4063 1vɪʳ 'to cherish, treasure'?
i.e., one only abandons that which one does not treasure
and
=
+
1078 1lhiuu 'stingy, miserly; grudge' =
top of 0930 1diu 'to have' +
all of 4063 1vɪʳ 'to cherish, treasure'
i.e., one is stingy about what one has and treasures?
The Tangraphic Sea also defines 1078 as 4063 and 4064
At first I thought 0776 2pa had the right of 2719 2phə as an abbreviated phonetic, but now I'm not so sure. Are there other a-tangraphs with ə-phonetics (or vice versa)? Moreover, even if the right side is phonetic, what is the function of the left side (Nishida radical 108 / Boxenhorn alphacode hax)?
14.4.24.23:48: NERVĀṆA (SIC)
Yesterday Andrew West brought the Tangut version of the Mahāparinirvāṇa Sūtra at the Institute of Oriental Manuscripts to my attention:
2liẹ 2pa 2diee 1phã 2lwəʳ 2lheʳ
'great (transcription) (artisan) (surname) sutra classic'
Each syllable corresponds to a syllable of the Chinese name for the sutra:
大般涅槃經典
*tha pa ndie phã kiẽ tiẽ (in Tangut period northwestern Chinese pronunciation)
'great parinirvāṇa sutra classic'
Syllables one, five, and six are translations from Chinese whereas syllables two, three, and four are transcriptions of Chinese.
般 *pa in turn obviously transcribes Sanskrit pa(ri)-. (There are longer transcriptions 般利 *pali and 波利 *pali.) But how did Sanskrit nirvāṇa- end up as *ndie phã?
The earliest transcription of parinirvāṇa- that I can find is Lokakṣema's 般泥洹 *pa ne ɣwan from sometime between 168 and 188 AD. 安世高 An Shigao transcribed nirvāṇa- as 泥洹 *ne ɣwan sometime between 148 and about 170 AD. (Dates and transcriptions are from Coblin 1983: 34, 241, and 243.)
At the time, Chinese
- had no syllable *ni or liquid *r; hence the use of open syllables 般 *pa and 泥 *ne for pari- and nir-
(般 also had a more common reading *pan whose final *-n might have been regarded as similar to Sanskrit -r-; Tangut 2pa may reflect a later northwestern *pa from this *pan, as a 2nd century *pa would have become *po in the dialect known to the Tangut)
- had no *v, initial *w- before *a, phonemic vowel length, or syllable-final retroflex *-ɳ; hence the use of 洹 *ɣwan for vāṇa-
At some point a few centuries later, Chinese still lacked the sounds and sound combinations listed above, and nirvāṇa- was retranscribed as 涅槃 *net ban. Syllable-final *-t was an attempt to transcribe Sanskrit -r which still had no Chinese equivalent.
By the early second millennium AD in the northwest,
Chinese *n- had partly denasalized to *nd-
Chinese *e had broken to *ie
Chinese *-t had become *-r (coincidentally matching the *-r of nirvāṇa-!) before disappearing; Tangut vowel length may indicate compensatory lengthening in Chinese after coda loss: *-er > *-ee?
Chinese *b- devoiced and aspirated, becoming *ph-
Chinese vowels nasalized before nasals which were later lost: *-an > *-ãn > *-ã
Hence 涅槃 *net ban became *ndie phã which had lost nearly all resemblance to the original nirvāṇa-.
14.4.23.23:23: ON BUDAPEST ON HUNGARY IN EUROPE
On occasion I am not sure which preposition to write before a location in English. I can't think of an example right now: in and on, perhaps?
English prepositions can seem arbitrary. Imagine a camera pointed at me and zooming out ...
at home
on this street
in or at this place (compare the two in Google Ngram Viewer)
in this town or city
on the island of Oahu
in Hawaii
in the Pacific Ocean
on Earth
in this solar system
in this galaxy
in this universe
Notice how on and at occasionally interrupt a chain of in - a 'cha-in'? What is the logic behind the choice of prepositions?
Someday I'd like to examine the logic behind the choice of postpositions in Tangut which can all be translated as 'in' (examples from Gong 2003: 607):
2ʔəu 'in (the garden)'
1kha 'in (the book, the water)' (probably cognate to 1ka 'center')
2gəu 'in (the water)'
2ɣa 'in (the sky, the heart)'
Locations are indicated by noun cases in Hungarian. Tonight I was looking at section 2.1.1.5.3 on "interior location" in Kenesei et al. (1998: 239-241) which made the following three-way distinction:
| Case type | Nouns | Examples |
| Interior: inessive, illative, elative | "All names of continents, countries [other than Hungary], counties, all foreign cities and towns [other than most formerly belonging to Hungary], and mountains" | Európában 'in Europe' (inessive) |
| Surface: superessive, delative, sublative | "Most of the Hungarian city and town names", 'Antarctica', 'Arctic', 'Hungary' | Budapesten 'in Budapest', Magyarországon 'in Hungary' (superessive) |
| Exterior: adessive, ablative, allative | "Some formerly Hungarian cities" (except for Brassó 'Brașov' and Pozsony 'Bratislava' which take interior cases) | Újvidéknél 'in Novi Sad' (adessive) |
I could roughly summarize the logic there as:
interior: non-Hungarian
surface: Hungary (except for 'Antarctica' and 'Arctic'; I guess the poles are regarded as surfaces)
exterior: ex-Hungarian
How old is this three-way distinction? Did the exterior class only develop after Hungary lost territory? Was, for instance, 'in Novi Sad' Újvidéken (superessive) until 1918? (I don't mean that the exterior case endings didn't exist until those cities became Hungarian. I mean that those cities' names shifted from the surface class to the exterior class.) Are Brassó 'Brașov' and Pozsony 'Bratislava' different in some way from other former Hungarian cities now respectively in Romania and Slovakia? Did they originally take surface cases?
14.4.22.23:54: THE ABSENCE OF THE UNASPIRATED: RECONSTRUCTING KHITAN CONSONANTS
English distinguishes between voiceless aspirated and voiced unaspirated stops and affricates in word-initial position:
| Voiceless aspirated | pʰ | tʰ | tʃʰ | kʰ |
| Spelling | p | t | ch | k |
| Voiced unaspirated | b | d | dʒ | g |
| Spelling | b | d | j | g |
The aspiration [ʰ] is not indicated in spelling. English ph is [f], English th is [θ] ~ [ð], and English kh is phonetically identical to English k [kʰ].
Many East, Southeast, and South Asian languages distinguish between voiceless unaspirated (i.e., [ʰ]-less) and aspirated stops and affricates in word-initial position:
| Voiceless unaspirated | p | t | tʃ | k |
| Voiceless aspirated | pʰ | tʰ | tʃʰ | kʰ |
([tʃ] is only an example of a palatal affricate; the details of affricates or palatal stops vary by language.)
This distinction can be romanized in several ways:
| International Phonetic Alphabet | p | pʰ | t | tʰ | tʃ | tʃʰ | k | kʰ |
| I. No distinction | p | t | ch | k | ||||
| II. Apostrophe | p | p' | t | t' | ch | ch' | k | k' |
| III. Medial -h- for aspirates | p | ph | t | th | c(h) | ch(h) | k | kh |
| IV. Initial h- for aspirates | p | hp | t | ht | c | hc | k | hk |
| V. Voiced letters for aspirates | b | p | d | t | j | ch | g | k |
Type III c and ch are often written with extra h's as ch and chh in English to avoid the mispronunciation of c as [k].
Type II was the most common for Chinese and Korean until the recent rise of apostrophe-free type V romanizations: e.g.,
| International Phonetic Alphabet | [tɑw] | [tɑŋ] | [tɛgu] | [tʰɛkkwəndo]* |
| II. Apostrophe | Tao | T'ang | Taegu | T'aekwŏndo |
| V. Voiced letters for aspirates | Dao | Tang | Daegu | Taegwondo |
While many type II spellings have been replaced by type V spellings in English (e.g., [mɑw tsɤ tʊŋ] as Mao Zedong instead of Mao Tse-tung and [kaŋnam] as Gangnam instead of Kangnam), others are too established to change: e.g., [kimtɕʰi] as kimchi but not gimchi.
Many Chinese and Korean names in English are in type I romanization: i.e., a simplified type II without apostrophes or anything else beyond the basic 26 letters. Hence T'aipei and t'aekwondo are normally written Taipei and taekwondo.
Type III is favored for nearly all Southeast and South Asian languages: e.g., Thai and Khmer (which would be Tai and Kmer in type I and T'ai and K'mer in type II).
I favor type III for Korean since it makes some phonetic processes transparent: e.g.,/tɕoh/ + /ko/ = 좋고 [tɕokʰo] 'good and'
III. choh- + -ko = chokho (-h and -k- 'trade places')
II. choh- + -ko = chok'o (-h 'becomes' an apostrophe after -k-)
V. joh- + -go = joko (the two letters -hg- are replaced by a completely different single letter -k-)
/tɕoh/ + /ta/ = 좋다 [tɕotʰa] 'is good'
Burmese is sometimes romanized with type IV to avoid confusing the aspirated stop ht [tʰ] with the fricative th [θ].III. choh- + -ta = chotha (-h and -t- 'trade places')II. choh- + -ta = chot'a (-h 'becomes' an apostrophe after -t-)
V. joh- + -da = jota (the two letters -hd- are replaced by a completely different single letter -t-)
All of that demonstrates the difficulty in writing the sounds of one language in a script for another.
The Khitan encountered similar problems with Chinese. They generally wrote Chinese voiceless aspirated obstruents with what I'll call 'series 1' small script characters but wrote Chinese voiceless unaspirated obstruents with both 'series 1' and 'series 2' small script characters:
| Liao Chinese | *p | *pʰ | *t | *tʰ | *tʂ | *tʂʰ | *k | *kʰ |
| Series 1 transcription | 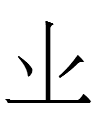 |
 |
- |
 - - |
||||
| Series 2 transcription | 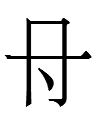 |
- |  |
- |  |
- |  |
- |
I excluded exceptions to this basic pattern requiring investigation.
I conclude that series 1 was voiceless aspirated and series 2 was voiced: i.e., that Khitan obstruents were like those of English rather than Chinese: i.e., without a voiceless unaspirated series. Just as Chinese voiceless unaspirated [t] may sound 'halfway' between an English [tʰ] and [d] (and is romanized as both t and d), Liao Chinese *t may have sounded 'haflway' between Khitan *tʰ and *d and was transcribed as both
series 1
in
<t.ei>, <d.ei>, <t.i>, <d.i>, <t.oi>
for Liao Chinese 德 *təj (corresponding to modern Mandarin [tɤ] which has been romanized as te and de).
Although modern Mongolian and Manchu have a Chinese-style distinction between voiceless unaspirated and aspirated obstruents, that may be due to long-term Chinese influence, and Khitan may have preserved an earlier English-style distinction. (Not that Khitan was ever influenced by English!)
I have wondered if Khitan had an English-style distinction for some time. I thank David Boxenhorn for independently suggesting it and inspiring me to test the hypothesis with the Khitan small script transcription data in Kane 2009.
*The [kk] of [tʰɛkkwəndo] is treated as if it were /k/ in the Korean spelling <thae.kwŏn.to> and in romanization.
14.4.21.23:59: 'VIRTUAL' VARIATION IN THE SMALL KHITAN SCRIPT
Liao Chinese 德 'virtue' corresponded to at least three if not four or five different Khitan small script spellings (Kane 2009: 245, Qidan xiaozi yanjiu 1985: 621, 623):
<t.ei>, <d.ei>, <t.i>, <d.i>, <t.oi>
Kane listed the block for <t.i> with the transcription <d.i>. Both appear in the corpus in Qidan xiaozi yanjiu (許 王 44-12, 道宗 34-15, 許王 7-16), though only the instance of <t.i> (whose initial may not be certain) in 許王 7-16 was identified as 德.
The <t> ~ <d> variation here and elsewhere implies that Khitan and Liao Chinese initial consonants did not quite match. Liao Chinese had a *t- ~ *tʰ- distinction, whereas Khitan may have distinguished between
- t(ʰ)- and d- (cf. English)
- t- and implosive ɗ- (cf. Vietnamese)
- t- and ejective tʼ- (cf. Nez Perce)
- t- and tense tt- (cf. Korean which also has tʰ-)
- t- and pharyngealized tˁ- (cf. Semitic; added 4.22.0:04)
- t- and preaspirated ʰt- (cf. Huautla Mazatec; 4.22.0:25)
Are there any other possibilities?
The variation in rhymes either indicates that the Chinese rhyme was something absent in Khitan or that the Khitan heard more than one version of the Chinese word. Dated Khitan texts may shed light on Chinese dialectal variation during the two centuries of the Liao Dynasty.
4.22.1:27: <t.oi> looks like an unlikely Khitanization of 德 given what we know of earlier and later stages:
Middle Chinese *tək (> borrowed into Korean as 덕 tŏk [tək])
Phags-pa Chinese ꡊꡜꡞꡗ <dhiy> [təj]
Old Mandarin *təj
Beijing de [tɤ]
However, supposing that <t.oi> is 德, perhaps MC *tək underwent these shifts in the dialect known to the Khitan:
*tək > *təɣ > *təɰ > *təj > *toj > *tøj
<ei> ([əj]?), <i>, and <oi> could all be Khitanizations of *-øj.
A couple of Chinese varieties in the 小學堂 database do have front rounded vowels in 德:
Funing Eastern Min tœk
Southeastern Northern Min tœ
Both of these varieties are spoken far to the south of former Liao territory and cannot be descended from the Chinese underlying loans in Khitan. Nonetheless they demonstrate that rounding of original schwa is possible in德.
Unfortunately I do not know of any Chinese words rhyming with 德 that were also Khitanized with <oi>. The only other Chinese word in 德's rhyme class that Kane (2009: 245) listed is 特 corresponding to
<t.ei> and <d.ei>
in the Khitan small script.
It is also possible that <t.oi> is
- an error (doubtful; would the same error be made on both a mirror and a coin?)
- a taboo deformation of one of the other spellings (but did anyone important at the time have 德 in their Chinese name?)
- a unrelated native word for 'virtue'
- a word meaning something other than 'virtue'
14.4.20.23:04: BUC__REST(_)
What accounts for the variation in non-Romanian names for București [bukuˈreʃtʲ]?
1. Why does Irish Búcairist [buːkəɾʲɪʃtʲ] have a long vowel? Is it an attempt to preserve the quality of Romanian [u]? (Irish short u is [ʊ], not [u].)
2. Why does English Bucharest have ch instead of c corresponding to [k]? Was it borrowed from a language which had [x]? Why don't those languages have [k] instead?
3. Why do so many languages have a instead of u for the second vowel? Even two of Romanian's neighbors have a: Hungarian Bukarest [bukɒreʃt] and Ukrainian Бухарест <Buxarest>. Oddly the u somehow crossed the Hungarian 'a-barrier' into Slovak and (then?) Czech Bukurešť.
4. At least I'm pretty sure that [s] in many languages is a spelling pronunciation or transliteration of s sans comma. Initially I thought it was odd that Romanian's neighbor Ukrainian has [s] instead of [ʃ], but perhaps Ukrainian Бухарест <Buxarest> was borrowed from Russian, replacing an earlier name more like Serbian and Bulgarian Букурешт <Bukurešt>.
5. When did -ti become [tʲ] in Romanian? I'm surprised this sound change isn't mentioned in this long article on Romanian phonological history. Does final [t] in most languages reflect [tʲ], a sound absent in most European languages? Ukrainian and Russian Бухарест <Buxarest> has <t> even though both languages have [tʲ].
Does final -ť [tʲ] in Czech and Slovak Bukurešť directly reflect Romanian -ti [tʲ]? In theory, an earlier Romanian [bukaresti] could have been interpreted as a Slovak genitive, dative, or locative singular from which a nominative and accusative Bukurešť could have been created by analogy with kosť 'bone'. Then that Bukurešť could have been borrowed into Czech. However, it would be simpler to assume that both postdate the -ti to [tʲ] shift in Romanian. How did Czechs and Slovaks know the name ended in [tʲ] if neither had direct contact with Romanians? I would have expected the Slovak name to be like the Hungarian name. Was the name a learned borrowing?
Hungarian has final ty [tʲ], but as far as I know, it does not have final -sty [ʃtʲ]. Is that why Hungarian Bukarest [bukɒreʃt] ends in [t]?
Irish Búcairist [buːkəɾʲɪʃtʲ] mixes an un-Romanian a with a final cluster that looks like an attempt to mimic the Romanian original. (A hypothetical English-based name would be *Bucairiost [bʊkəɾʲɪst]. I think the vowel of the final syllable is [ɪ] because unstressed [ɛ] is not possible if I understand this article correctly.)
6. Why do these names have non-i vowels in their final syllables?
Romansh Bucaresta
Slovene Bukarešta
Lithuanian Bukareštas (with masculine nominative singular -s)
Portuguese Bucareste
Latvian Bukareste
Final -o in Japanese ブカレスト Bukaresuto indicates borrowing from a source with final -t.
I wonder if Korean once had an earlier Japanese-like borrowing that was replaced by 부쿠레슈티 Pukhureshuthi [pukʰureɕutʰi] which seems to be a straightforward transliteration of București.
















