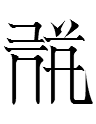
13.12.28.20:14: THE GOLDEN GUIDE: LINE 100: TANGRAPHS 496-500
100. The halfway point at last after over three years!
聂鸿音 Nie Hongyin and Shi Jinbo (1995) interpreted the Chinese surnames in lines 99-100 as a pun on Tangut period northwestern Chinese
秋露宜酥油,渾酒和茵蔯
*tshiw ləu ŋgi səu jiw, xwĩ tsiw xɔ ʔĩ tʂhɨĩ
lit. 'autumn dew suitable butter oil, muddy wine harmonize redstem wormwood'
It doesn't make sense to me. Dew is suitable as oil?
I am uneasy about glossing tangraphs as being specificially for Chinese surnames since native glosses simply state they are for clan names. Moreover, the line between 'Tangut' and 'Chinese' may have been quite blurry a millennium ago; people who identified as Tangut could have had surnames of Chinese origin (and perhaps also vice versa).
| Tangraph number | 496 | 497 | 498 | 499 | 500 |
| Tangraph | |
|
|
|
|
| Li Fanwen number | 5494 | 4324 | 3024 | 0494 | 0298 |
| My reconstructed pronunciation | 2xwəi | 1tsew | 2xa | 1ĩ | 1tʂhɨĩ |
| Tangraph gloss | the Chinese surname Hui | wine | the Chinese surname He | the Chinese surname Yin | the Chinese surname Chen |
| Word | the surname 惠 Hui (*xwi) | the surname 酒 Jiu (*tsiw) | the surname 和 He (*xɔ) | the surname 殷 Yin (*ʔɨĩ) | the surname 陳 Chen (*tʂhɨĩ) |
| Translation | Hui, Jiu, He, Yin, Chen | ||||
496: Analysis unknown. 5494 consists of rare components found in only three other tangraphs:
/
+
?
5494 2xwəi 'the Chinese surname 惠 Hui' =
left of 5493 2xã (transcription of Chinese *xã) or 5495 2xəʳ 'to hum' +
right of 4634 1tshwiu 'to cook'
At first I thought the left-hand component (Boxenhorn code zer) could represent the initial x- of 2xwəi, but the other tangraph with the same right-hand component (Boxenhorn code zae) does not have the rhyme 2-wəi.
497: Did the Tangut use their word for wine to refer to a beverage made from the 1tsə̣ tree?
+
4324 1tsew 'wine' < Chinese 酒 (which is also a Chinese surname) =
top of 4359 1tsə̣ 'a kind of tree' +
all of 5315 2ʂwɨii 'crimson' (a reference to the color of wine?)
498: Analysis unknown. Were the Hes the 'masters of the water' as their tangraph's structure implies?
+

3024 2xa 'the Chinese surname 和 He' =
'water' = left of 3058 2ɮɨəəʳ 'water' +
'master' (Nishida radical 298; Boxenhorn code tue) = left of 0998 2dziee 'teacher'
The elements of 3024 in turn appear in three other tangraphs:
=
+
1998 1pho 'lake' < Tangut period northwestern Chinese 泊 *phɔ (derived from 3058 'water', 2725 below, and 0174 khwəi 'circle')
2725 1wɔ̣ 'circle' (derived from 3058 'water' and 2757 2roʳ 'to circle')
=
+
4686 1khwiã 'commandery; the Chinese surname 權 Quan' (derived from 4719 2kɛ̣ 'boundary' and 2725)
'Commandery' is probably a loan from Chinese 郡, but I would expect the Tangut period northwestern pronunciation of 郡 to be *khwĩ, not ́*khwiã. (權 Quan was *khwɨã.)
499: Was there a relationship between the 殷 Yin and 晉 Jin families in the Tangut Empire?
+
0494 1ĩ 'the Chinese surname 殷 Yin' =
right of 3213 1tsĩ 'the Chinese surname 晉 Jin'
+ left of 2888 2mə 'surname' (semantic)
500: The structure of 0298 implies a relationship between the 陳 Chen family and some Tangut clan with ne in their name: e.g., Tsane, Byne, Nedu, etc. (Could Ne be a surname by itself?)
+
0298 1tʂhɨĩ 'the Chinese surname 陳 Chen' =
all of 0547 2nie 'the Tangut surname (syllable) Ne' +
right of 2107 1tsəiʳ 'earth'
I assume that 'earth' represents some trait of the Chens.
13.12.27.23:06: THE GOLDEN GUIDE: LINE 99: TANGRAPHS 491-495
99. The halfway point of the Golden Guide is almost within reach now.
| Tangraph number | 491 | 492 | 493 | 494 | 495 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3045 | 4153 | 3590 | 3342 | 3939 |
| My reconstructed pronunciation | 1tshew | 2lɨew | 1gii | 1səu | 1jew |
| Tangraph gloss | the Chinese surname Cao | to gather, assemble | the Chinese surname Ni | the Chinese surname Su | the Chinese surname Yao |
| Word | the surname 曹 Cao (*tshaw) | the surname 陸 Lu (*lɨu) | the surname 倪 Ni (*ŋgi) | the surname 蘇 Su (*səu) | the surname 姚 Yao (*jew) |
| Translation | Cao, Lu, Ni, Su, Yao | ||||
491: Were some local Cao known to the Tangut associated somehow with 'water' and 'year'?

3045 1tshew 'the Chinese surname Cao' =
'water' = left of 3058 2ɮɨəəʳ 'water' +
center and right of 3305 1kiew 'year'
492: Analysis unknown. 4153 contains three components. The first may be from a synonym; the functions of the other two components are unknown.
+
+
?
4153 2lɨew 'to gather, assemble' =
'wood' = top of 4236 2ɣa 'to gather' +
'?' (Nishida radical 103 / Boxenhorn code bes) +
2544 2ʂɨẽ 'sage' < Tangut period northwestern Chinese 聖 *ʂɨẽ
493: Were the 倪 Ni in the Tangut Empire somehow associated with the 錢 Qian?
+
3590 1gii 'the Chinese surname Ni' =
'person' = left of 3277 2tshia 'the Chinese surname 錢 Qian' +
right of 1598 1gii 'clear, transparent' (phonetic)
494: 3342 is a straightforward semantic-phonetic compound:
+
3342 1səu 'the Chinese surname Su' =
'person' = left of 2888 2mə 'surname' (semantic) +
all of 1473 1səu 'than' (phonetic)
495: Most first ('level') tone tangraphs have entries in the surviving volumes of the Tangraphic Sea, but 3939 is not one of them, so I can only guess that it is a phonetic-semantic compound:
+
3939 1jew 'the Chinese surname Yao' =
left of 3954 1jew 'oil' < Tangut period northwestern Chinese 由 *jiw (phonetic) +
right of 2888 2mə 'surname' (semantic)
13.12.26.22:46: THE GOLDEN GUIDE: LINE 98: TANGRAPHS 486-490
Three lines left until I'm done with the first half of the Golden Guide.
98. 聂鸿音 Nie Hongyin and Shi Jinbo (1995) interpreted the Chinese surnames in lines 97-98 as a pun on Tangut period northwestern Chinese
更過軍求定,師伸計宋和
*kɛ kwɔ kwĩ khiw thie, ʂɨ ʂɨĩ ki səũ xɔ
lit. 'more pass army seek settlement, master extend plan Song [Dynasty] peace'
史金波 Shi Jinbo's surname happens to be Tangutized with the first character of line 98:
| Tangraph number | 486 | 487 | 488 | 489 | 490 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5442 | 3249 | 5157 | 4921 | 3540 |
| My reconstructed pronunciation | 1ʂʌ | 1ʂɨĩ | 1ki | 1swəĩ | 1xa |
| Tangraph gloss | to send | body | (transcription of Chinese) | the Chinese surnames Sun and Song | the Tangut surname Ha |
| Word | the surname 史 Shi (*ʂɨ) | the surname 申 Shen (*ʂɨĩ) | the surname 嵇 Ji (*ki) | the surname 孫 Sun (*swə̃) or 宋 Song (*səũ) | the surname 合 He (*xɔ) |
| Translation | Shi, Shen, Ji, Sun/Song, He | ||||
486: The Tangutization of Tangut period northwestern Chinese 史 *ʂɨ as 1ʂʌ is reminscent of the premodern Sino-Korean reading sʌ for both 史 and 使.
+
5442 1ʂʌ 'to send' (< Chinese 使 *ʂɨ after c. the 7th century) =
'arm' = bottom left of 4489 1phii 'to cause' (native Tangut equivalent of 使 which can also mean 'to cause') +
center and right of 0749 1phi 'to cause' (1phii above may be from 1phi plus a suffix)
487: Although one out of five tangraphs contains 1886 'person', only a surprisingly small number of tangraphs are derived from it in the Tangraphic Sea: e.g., 3249:
+
3249 1ʂɨĩ 'body' < Tangut period northwestern Chinese 身 *ʂɨĩ =
all of 1886 2dzwio 'person' +
all of 1245 1je 'self'
488: The Tangraphic Sea analysis of 5157 implies that its parts represent the recording of achievements.
+
5157 1ki (transcription of Chinese *ki words like 記 'record') =
'arm' = left of 5404 1la 'to record, write, stele'
right of 2132 2jew 'achievement'
489: Tangut did not have the rhyme -wə̃, so the closest equivalent of the Tangut period northwestern Chinese surname 孫 *swə̃ was 1swəĩ, which also doubled as a Tangutization of Tangut period northwestern Chinese 宋 *səũ.
(Tangut had the rhyme -əũ only in Chinese loans with initial t-, ts-, and x-. These loans may have been borrowed after the Tangutization of 宋 *səũ as 1swəĩ became conventionalized. Conventionalizations can persist even if phonetically closer approximations are possible: e.g., the Korean surname [i] is normally Lee in English even though English speakers could render it as [iː] like the English name of the letter E.)
+
4921 1swəĩ 'the Chinese surname Sun or Song' =
top of 4940 2jə 'the Tangut surname Y' +
all of 5933 1swəĩ 'monkey' < Tangut period northwestern Chinese 猻 *swə̃ as phonetic
Note that the right-hand element of both 4921 and 5933 resembles the 子 of 孫 Sun and 猻 'monkey'.
Were the Y somehow associated with a Chinese Sun or Song family?
490: The Tangutization of Tangut period northwestern Chinese 合 He (*xɔ) as 1xa suggests that Tangut -a may have been back [ɑ].

3540 1xa 'the Tangut surname Ha' =
'water' = left of 3024 2xa 'the Tangut surname Ha' +
'arm' = left of 5683 2iiʳ 'to spread, uphold'
Is 2xa merely phonetic in 1xa, or were the two clans associated with each other in some way? 2xa could be a derived from *xa plus an *-H that conditioned its second ('rising') tone. The 2xa could have been a clan associated with rivers (hence 'water') and perhaps the 1xa were also fishermen, boatmakers, or the like.
'Arm' or 'spread' could symbolize some trait of the 1xa clan.
13.12.25.23:35: THE GOLDEN GUIDE: LINE 97: TANGRAPHS 481-485
I want to finally finish the first half of The Golden Guide by the end of the year. Just four lines to go ...
97. More Chinese surnames ... but are they all surnames?
| Tangraph number | 481 | 482 | 483 | 484 | 485 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 4866 | 1034 | 5045 | 0006 | 3836 |
| My reconstructed pronunciation | 1kɛ | 1kwo | 1kwĩ | 2khiew | 2thie |
| Tangraph gloss | incomplete, fragmentary | first syllable of the Tangut tribal name Kwona | gentleman | (transcription of Chinese) | |
| Word | the surname 耿 Geng (*kɛ) | the surname 郭 Kwo (*kwo) | the surname 君 Jun (*kwĩ) | the surname Qiu 邱 (*khiw) | the surname 鐵 Tie (*thie) |
| Translation | Geng, Guo, Jun, Qiu, Tie | ||||
481: The Tangraphic Sea analysis of 4866 makes no semantic or phonetic sense:
+
4866 1kɛ ' incomplete, fragmentary =
top of 4739 1tseʳw 'joint' +
bottom right of 1832 2lwiẹ < *S-Pɯ-leN-H 'mountain' < Middle Chinese 嶺 *leŋˀ 'mountain range'
12.26.1:57: Moreover, the components of 4866 offer no clues. The function(s) of
the 'horned hat' on top (Boxenhorn code bio; in ~5% of characters)
the 'person' on the bottom left (Boxenhorn code dex; in one out of every five characters; the same four strokes also appear in other components)
the right-hand element (which can never appear in any other position; Boxenhorn code cok; in ~4% of characters)
are largely unknown. ('Person' clearly functions as 'person' in some characters, but usually doesn't.)
482: The Tangraphic Sea analysis of 1034 derives 1034 from one of its obvious derivatives.
+
1034 1kwo 'first syllable of the Tangut tribal name Kwona' =
top left of 0977 1kwo 'bedwetting' (in which 1034 is a phonetic combined with 'flesh' and 'water') +
left of 4562 2zəʳ 'the Tangut surname Zyr'
Were the Zyr (or some clan whose name began with Zyr-) related to the Kwona ('Black Kwo'?; the -na may be
0176 nɨaa 'black'.)
1034 is quasiphonetic (xenophonetic?) in
2937 lhiẹ 'country'
since the Chinese word for 'country' was 國 *kwo. (But what are the functions of the vertical line and 'water' on the left?)
12.26.2:14: 1034 also represents 1kwo in loanwords incorporating Chinese 國 *kwo 'country' (Kychanov and Arakawa 2006: 526-527):
1kwo 2tʂɨi < 國職 *kwo tʂɨi 'state employee/office'
1kwo 1jõ < 國王 *kwo wɨõ 'king of a country' (Chinese 'king' might have been *wiõ or *ɥõ with a palatal vowel *-i- or glide *j- corresponding to Tangut j-)
483: I had never heard of a surname 君. It's not in 百家姓 Baijiaxing or in Giles' (1892: 1357) much longer list of surnames, but here it is on netor.com.
What does 5045 'gentleman' have to do with ... fighting outside?
+

5045 1kwĩ 'gentleman' < Tangut period northwestern Chinese 君 *1kwĩ
top of 4916 1ɣwe 'to struggle, fight'
all of 2536 2vɨe (optative prefix) < *2vɨə- 'outside' + *-j
The top of 0006 is 'upper' which I initially thought might be a reference to one of the Chinese characters that it transcribes: 丘 *khiw 'hill'. But now I suspect it is an abbreviation of a near-homophone 0105 (see below).
The bottom is in only three other tangraphs; it might mean 'sacrifice' (and if it does, why is it in 0006?):
=
+
0078 1tị 'to offer a sacrifice, to pray' with 'upper' from 0105 kiụ 'to pray' and the rest from 1682 (see below)
=
+
1682 2gwie < *N-kwe-H 'to offer sacrifces to gods or ancestors' with the left of 0896 1gwie 'eating one's fill' (phonetic) and the bottom right of 0078 (phonetic).
=
+
4637 1kwiẹ < *S-kwe 'to offer sacrifice' with 'mouth' from 4518 2lɨi 'fragrant' and the right of its cognate 1682 (both share a root *kwe).
485: I suspect 3836 is a distortion of one of the Chinese characters that it transcribes: 定 *thie. So I think that 3836 is the basis of its 'source' characters according to the Precious Rhymes of the Tangraphic Sea:
+
3836 2thie (transcription of Chinese) =
center of 4570 2thie 'scheme'
right of 2637 1dəəu 'slave' < Tangut period northwestern Chinese 奴 *ndəu
I don't know why Tangut has a long vowel in 'slave'.
13.12.25.18:50: KARÁCSONY
Two days ago, I learned from Bitxəšï-史 that the earliest attested Japanese word for 'Christmas' is ナタル Nataru (which I presume is from Portuguese Natal). Did early Japanese Christians say ボン・ナタル "Bon Nataru" (< Bom Natal)?What did the early Christian Mongols call Christmas? Or the Khitan? (Some of the subjects of the Qara Khitai were Christians.)
The title of Bitxəšï-史's post is "Karácsony" [ˈkɒraːtʃoɲ], Hungarian for 'Christmas'. According to Wiktionary, karácsony is
Probably a Bulgarian loanword, compare dialectal крачун (kračun, “winter solstice; a Slavic holiday celebrated at the winter solstice”), also cf. Macedonian dialectal крачун (kračun, “Christmas”), Slovak Kračun (“winter solstice feast”) (dialectal, "Christmas"). From Proto-Slavic *korčiti (“to step”).
The first vowel of Karácsony was inserted to break up an un-Hungarian initial consonant cluster.
Is the length of the second vowel á [aː] significant? It corresponds to a short vowel in Slovak which distinguishes between short a and long á.
I wonder if the third vowel o [o] reflects an [ʊ] like-pronunciation of /u/ in the Slavic source language.
The final -ny [ɲ] is puzzling because the Slavic forms end in -n. If the word ended in a palatal(ized) n in the source language, I would expect the Slovak form to be *Kračuň with ň [ɲ]. Did the word ever end in *-nʲ < *-nĭ? If it did, then Hungarian -ny reflects a consonant that merged with -n in Bulgarian and Macedonian, and the Slovak form ending in -n is irregular and may be a borrowing from a language which merged *-nʲ with *-n.
13.12.24.23:57: DISAPP-JER-ANCE IN SLOVENE
When looking at Kortlandt (2002: 18) while writing "Up High - and 'More' Wrong", I was puzzled by this passage (emphasis mine):10.3. The jers were lost or merged with other vowels under various conditions in the separate languages. They have been preserved as a separate phoneme in Slovene.
But until now, I thought the only modern Slavic language which has a separate phoneme for a jer is Bulgarian which has /ə/ from the strong back jer *ŭ (whereas the strong front yer *ĭ generally merged with /e/). Weak jers (e.g., in final position) were lost (as in every other modern Slavic language to the best of my knowledge):
*dĭnĭ > /den/ (not */dene/) 'day'ア
*sŭnŭ > /sən/ (not */sənə/) 'sleep'
cf. other languages which have merged the strong back jer of 'sleep' with other vowels:
Serbo-Croatian san
Polish sen
Macedonian, Russian, Belarusian, Ukrainian son
According to Priestly (1993: 448-449) Slovene dialects merged yers into either */a/ or */e/ in medieval times. The modern reflexes of */a/ and */e/ are not stated, though on p. 393, Priestly wrote,
In the dialects which were to form the base of standard Slovene [...] the two strong jers [...] change to /aː/ when long, and to /ə/ when short.
I was unaware of this because Slovene has no separate letter for schwa in its Latin alphabet. (If Slovene had been written in Cyrillic, perhaps its schwa would have been written with the letter Ъ for the back jer as in Bulgarian.)
The dialects underlying standard Slovene shifted jers to medieval */a/. So is modern standard Slovene /ə/ from medieval short */a/? Did the old short strong jers lower and centralize to */a/, then rise to */ə/? Does modern standard Slovene prescriptive* /ə/ partly come from original short */a/?
To confuse matters further, the Slovene reflex of Proto-Slavic *sŭlnĭce 'sun' is sonce with long [oː], not long [aː]. Is [oː] a contraction of */aːl/ before */n/? Or did */a/ round before an */l/ which later dropped before */n/? (Cf. Slovene solza < *sŭlza? 'tear' in which *-l- is retained before *z.)
I'm still trying to figure out the basic history of Slavic segments. Slavic supersegmentals remain far out of my reach. Of course, an understanding of the supersegmentals would enhance my understanding of the segmentals ... sigh.
*12.25.0:10: Unstressed vowels may be reduced to schwa in colloquial Slovene (Priestly 1993: 394).
13.12.23.22:45: CATS, HORSES AND CHARIOTS: JERS IN UKRAINIAN, CHINESE, AND TANGUT
The jers of Slavic (*ĭ, *ŭ) have been a major influence on my reconstructions of Old Chinese and pre-Tangut. In the latter two languages, jer-like unstressed short vowels left traces on nearby stressed vowels: e.g.,車 Old Chinese *kɯ-la > *kɯ-lɨa > *klɨa > *kɨa > *kɨə > *kyø > *ky > Mandarin jū [tɕy] 'chariot' (*a partly raised to harmonize with *ɯ)
Perhaps originally *kŭ-kla if a loan from an Indo-European language; cf. Proto-Tocharian *kuk(ä)le 'wagon'.
*kŭ-kla > *kɯ-k(l)ɨa > *kɨa ...
Tangut *mĭ-ro > *mĭ-rø > *mĭ-re > *mĭ-rie > 1rieʳ 'horse' (*o fronted and raised to harmonize with *ĭ; more here)
cf. Ukrainian (more here):
*konĭ > *kʊnʲĭ > *kʏnʲ > *kɪnʲ > kinʲ 'horse' (*o raised to harmonize with *ĭ; *n palatalized before *ĭ)
*kotŭ > *kʊtŭ > *kʏt > *kɪt > kit 'cat' (*o raised to harmonize with *ŭ)
As far as I know, final jers have disappeared in all Slavic languages, though they have left traces: e.g., Ukrainian i from *o and final palatalized consonants. If we knew nothing about Slavic language history except for the modern spoken languages (so we wouldn't have access to Cyrillic spellings preserving jers), we would have difficulty reconstructing jers, though some jers would be recoverable. That situation is like that of Chinese and Tangut, whose 'jers' are only implied at best by the attested evidence. Maybe my whole jer theory is just wrong.
13.12.22.23:55: UP HIGH - AND 'MORE' WRONG
I was wondering how the title of the Hungarian song "Kétszázhúsz felett" ('Over 220') would be translated into Czech, and that got me thinking about the etymology of Czech více 'more'. I initially guessed (wrongly; see below) that the latter was descended from Proto-Slavic *vysĭ 'height', which in turn may be from a Proto-Indo-European *ups (I suppose *-ĭ is a noun-forming suffix). How did *ups become *vys?
1. *v-prothesis: *u- > *vu- (Kortlandt 2002: 11)
2. Delabialization: *u > *y (Kortlandt 2002: 12)
?. Law of Open Syllables: *vypsĭ > *vysĭ (to avoid the closed syllable *vup; this must have happened after *-ĭ was suffixed)
I don't know when the last step occurred relative to 1 and 2 since I can't find it in Kortlandt's extensive chronology. Here are three scenarios:
Before 1: *upsĭ > *usĭ
Between 1 and 2: *vupsĭ > *vusĭ
After 2: *vypsĭ > *vysĭ
12.23.17:36: I got the erroneous notion that více was from *vysĭ because it sounded vaguely like Russian vyše 'higher' which really is from *vysĭ. But the real Czech cognate of Russian vyše is výše 'higher'. více, Slovak viac, Polish więcej, and Slovene več seem to be a descendant of something like *vęč. Does *vęč have East Slavic reflexes, and can it be traced back further to something like *wenk?