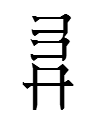
2ziọ < *Sɯ-(T)SoH 'longevity'
12.12.15.23:27:
LONG LIVE LI FANWEN!
I learned from Andrew West that the latest issue of 西夏研究 Tangut
Research has a color section celebrating the 60th anniversary of Li
Fanwen's career as a Tangutologist and his 80th birthday. There is a
large seal script version of the Tangut character
which made me wonder how many other characters contain Nishida's (1966: 243) radical 118 'life' (alphacode: too):
2ziọ < *Sɯ-(T)SoH 'longevity'
Using David Boxenhorn's Tangut Search tool, I found ten other tangraphs with too. I also found one tangraph with half of too (alphacode: caibax).
| Tangraph | Reading | Gloss | Notes |
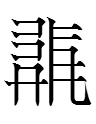 |
2lhie | first half of Lhelon, name of a Tangut ancestor | 'before' (semantic) on the right; was Lhelon a long-lived Tangut Methuselah? |
 |
to butcher, sacrifice | left may be phonetic from the name character above but is said to be 1ʂɨii 'livestock' (below); right is 'food and drink' | |
 |
1ziọ | cow disease | 'die' (alphacode: bux) on the left; phonetic abbreviation of 'longevity' (an near-homophone) on the right; how ironic if the name of a disease that might shorten life sounds like 'longevity' |
 |
variant of above; the left side (alphacode: bilbae) is a variant of bux 'die' | ||
 |
?tʂɨo | permanent, forever | the right two-thirds (alphacode:
daiheu) are 2ziʳ 'back' which is phonetic in 2ziʳ
'long' which in turn is the likely source of the right two-thirds of
'permanent' no entry in any Tangut dictionary, though it appears within entries of Tangraphic Sea and Homophones |
 |
2ʂɨoo | transcription character | no known examples of use the right side (alphacode: fisbia) is not in any other tangraph a fanqie character from 1ʂɨii (below) plus 2khioo 'to look' (alphacode: fisbiabil with fis atop biabil, not just bia) |
 |
1ʂɨii | livestock, domestic animals | borrowed from Chinese 牲 'butcher' + 'livestock' |
 |
2dị | a second syllable in Tangut surnames | left side is phonetic; is right side semantic (for clans with reputations for long life)? |
 |
2gia | old sheep | 'sheep' (< Chn 羊 'sheep' which is more complex than its Tangut graphic cognate despite the reputation of tangraphy for complexity) + 'longevity' |
 |
1nəiʳ | 'sheep' + 'longevity' + 'drink' (why this last part?) | |
|
|
1vəʳ | die young | top left of 'longevity' (caibax) + 'not' + 'whole' (in whole!) |
The functions of too appear to be straightforward in the above eleven tangraphs. I suspect that too is derived from Chn 壽 'longevity' or one of its many variants (81 listed here). Why couldn't too stand alone as a tangraph? Why does
2ziọ 'longevity'
need the extremely common element
alphacode: dex
on the right? Is dex an abbreviation of another tangraph?
12.12.14.23:56: ʻODDITIES IN THE 2012 ALA-LC KHMER ROMANIZATION
I liked the ALA-LC Khmer romanization, so last Sunday I was surprised to see that it had been revised this year. I don't think the new version is much of an improvement for several reasons.
1. The change I like the least is the romanization of អ [ʔ] as "ʻ ʹ (ʻayn + soft sign)" instead of q which is
- easier to type
- known to users of Huffman's Khmer textbooks including myself
- known to Unicode users
First, why should a glottal stop be written with two characters instead of one? Elsewhere in the document, អ <ʔ> is romanized as ʻayn (អក្សរ ʻAksar, អាត្ម័ន ‛ātmăn) not as ʻayn followed by a soft sign. Second, if easily typeable q had to be avoided (why?), why not use ʼalif instead of ʻayn for Khmer glottal stop? There is no ʻayn [ʕ] in Khmer. Third, ʻayn is also used for the rare diacritic ៏.
2. Why is ឪ [ʔəw] romanized as ýu even though it has nothing to do with the vowel ឹ <ý>? I would romanize it as ūv since it is equivalent to អូវ <ūv>. The earlier ALA-LC romanization does not distinguish between ឩ and ឪ; both are romanized as <ū>.
3. Syllabic liquids are indicated with a subscript dot instead of a subscript circle. In the old romanization, <l̥> with a circle was a syllabic liquid and <ḷ> with a dot was a retroflex nonsyllabic liquid, but now both are ambiguously romanized as <ḷ> with a dot.
4. Both ALA-LC romanizations are quasihistorical/etymological, yet ឯ <e> is now romanized as <ae>, reflecting its modern pronunciation [ae] rather than its older value [eː]. Moreover, the dependent counterpart of independent ឯ <e> (ALA-LC 2012 <ae>) is still romanized <e>.
5. In the section on dependent vowels, the consonants that the vowels attach to are represented with soft signs rather than hyphens. One might think that the vowels are supposed to be romanized with soft signs, though they aren't.
6. Dependent ោះ <oḥ> is now romanized as <oaḥ>, reflecting its modern pronunciation [ɑh] ~ [uəh] rather than its older value [oːh].
7. "when ឱ is added as a subscript to យ it looks like ឲ្យ" seems to be an error for "when យ is added as a subscript to ឱ it looks like ឲ្យ".
12.12.13.23:54: И-NIGMATA (logonote*)
Yesterday was 12.12.12, which is ВІ (two-ten; cf. Russian двенадцать) in Cyrilllic numerals. That got me thinking about Cyrillic І.
Why did early Cyrillic have И (from Greek eta) as well as І (from Greek iota) for [i]?
In the Early Cyrillic alphabet there was little or no distinction between the letter ⟨И⟩ and the letter ⟨І⟩ which was derived from the Greek letter Iota (Ι ι). They both remained in the alphabetical repertoire because they represented different numbers in the Cyrillic numeral system, eight and ten, and are therefore sometimes referred to as octal I and decimal I.
What was that "little [non-numeric] distinction"? Were Greek words with eta and iota - both [i] in Greek at the time - etymologically spelled with И and І in early Cyrillic (and the two <i> in Glagolitic: Ⰹ and Ⰻ)?
was used mainly for its numeric value of 800, and rarely appeared even in Greek words.
yet it has not survived in modern Cyrillic, whereas both И and І are in modern Cyrillic alphabets (though only Ukrainian, Rusyn, Kazakh, Khakas, and Komi have both of them, and only Belarusian has І but not И). Why didn't the fate of Cyrillic omega parallel that of И, the much more successful descendant of its front counterpart in Greek? My guess is that Cyrillic omega was doomed to the periphery and ultimate oblivion because eight hundred was much less frequently written than eight and ten.
Similarly, seven hundred (the numerical value of Glagolitic Ⱉ <o>) was much less frequently written than ten and twenty (the numerical values of Glagolitic Ⰹ <i> and Ⰻ <i>). So did Glagolitic Ⱉ <o> have a fate similar to that of Cyrillic omega? What is its frequency relative to that of Ⱁ <o>, the Glagolitic counterpart of Cyrillic omicron?
*The actual Greek plural is αἰνίγματα <ainígmata> with αἰ <ai>, not η <ē> eta. И is not etymological. I chose it because
- it is one subject of this post
- its sound values [ɛː] (in Classical Greek) and [i] (in modern Greek) are close to [ɛ] ~ [ɪ] in English enigma
- it is also the mirror image of the adjacent letter N
I kept the I in "И-NIGMATA" to correspond to Cyrillic І.
12.12.12.23:00: JIRHON JIRHON JIRHON
Today is 12.12.12. The Jurchen might have called it
<jirhon jirhon jirhon>
using the word for 'twelve' (lit. 'two-ten') that they borrowed from some dialect of Khitan (or a related Para-Mongolic language).
By coincidence, Jin (1984: 204) lists three variants of <jirhon> 'twelve' - enough to write each part of the date with a different variant. None of the variants resemble Chinese 十 'ten' or 二 'two' or the characters for the native* Jurchen numeral
<juwa jo> 'twelve' (lit.'ten-two')
The second and third variants resemble hiragana ふ <fu>, but I think all three could be derived from Chinese 尔 which was pronounced something like *ʒi between the mid-Tang and the Song (cf. Sino-Korean zi borrowed from 8th century Chinese, now modern SK i). 尔 *ʒi could have been chosen as the basis for <jirhon> because of its reading's resemblance to ji.
As tempting as it is to call today

<jirhon aniya jirhon biya jirhon inenggi> 'twelfth year, twelfth month, twelfth day'
as far as I know, the Jurchen used 'ten-two' in dates rather than 'two-ten':
<juwa jo aniya> 'twelfth year'
<juwa jo biya> 'twelfth month'
<juwa jo inenggi> 'twelfth day'
Was Jurchen date structure influenced by Chinese and/or Khitan which also have 'ten-two' before 'year', 'month', and 'day'?
Were jirhon and juwa jo ever interchangeable, or did they have nonoverlapping spheres of usage? Was jirhon the colloquial equivalent of more prestigious juwa jo? I suspect jirhon is from a variety of Para-Mongolic spoken in proximity to the Jurchen - a dialect of Khitan or some other Para-Mongolic language - rather than the royal dialect of Khitan.
*The components juwa and jo are native, but it is not clear if the 'ten-two' construction is a calque of Chinese or Khitan 十二 'ten-two'. Khitan 十二 could have been read as something like jirhon 'two-ten' (cf. how 12 is read as двенадцать 'two-ten' in Russian), but it is simpler to assume that the spelling reflects the order of the morphemes it represents.
12.12.11.23:51: A GRAVE È-LTERNATIVE
David Boxenhorn suggested that I use a grave accent instead of a circumflex in my no-digraph Korean romanization. The long counterparts of vowels written with grave accents would have háčeks combining the grave accent for vowel quality with the acute accent I was using for vowel length. However, I would prefer to combine grave and acute accents into circumflexes, reserving the háček for palatalization. Also, a háček over long vowels resembles a breve which indicates short vowels, whereas a circumflex is often used as an alternative to a macron in Japanese romanization. I present both solutions below:
| Hangul: no vowel length distinction | IPA | Short vowel | Long vowel | |
| Boxenhorn | My alternative | |||
| ㅏ | a(ː) | a | á | |
| ㅔ | e(ː) | e | é | |
| ㅣ | i(ː) | i | í | |
| ㅗ | o(ː) | o | ó | |
| ㅜ | u(ː) | u | ú | |
| ㆍ (obsolete) | ʌ(ː) | à | ǎ | â |
| ㅐ | ɛ(ː) | è | ě | ê |
| ㅓ | ə(ː) | ò | ǒ | ô |
| ㅡ | ɯ(ː) | ù | ǔ | û |
| ㅚ | ø(ː) ~ we(ː) | ö | ő | |
| ㅟ | y(ː) ~ wi(ː) | ü | ű | |
The no-digraph Korean alphabet would be either
a á à ǎ b c ć d e é è ě g h i í j k ḱ l m n ṅ o ó ò ǒ p ṕ r s ś š š́ t t́ u ú ù ǔ w y
or
a á à â b c ć d e é è ê g h i í j k ḱ l m n ṅ o ó ò ô p ṕ r s ś š š́ t t́ u ú ù û w y
with 41 letters excluding f, q, v, x, and z. I considered using those remaining letters for the reinforced consonants ć, ḱ, ṕ, ś, t́, but they would be confusing in most cases. q for ḱ and x for ś would work, but the others (f, v, z) imply fricatives, not stops, and there are two labiodentals (f, v) and one alveolar which don't line up well with one labial (ṕ), one dental (t́), and one palatal (ć). Finally, f, q, v, x, and z have no visual common denominator, unlike ć, ḱ, ṕ, ś, t́ which share an acute accent with each other and with the long vowels. Although ć, ḱ, ṕ, ś, t́ are not long consonants, they have been commonly romanized as doubled consonant letters (and are written with doubled consonant letters in Hangul: ㅉ, ㄲ, ㅃ, ㅆ, ㄸ), just as long vowels are often romanized as double vowel letters (though I don't know of any Korean romanization with double vowel letters for long vowels).
Maybe x should represent [ɕ] as in Pinyin. This enables me to
Here's the excerpt from the Universal Declaration of Human Rights again in my newest romanization:- use David's háček unambiguously for long counterparts of vowels written with grave accents
- replace the awkward š́ for reinforced palatal [ɕ͈] with x́ (does such a letter exist in any orthography?)
Módùn ingan-ùn tèònal t́è-butò jàyuroumyò gù jonòm-gwa gwòlli-e iśò doṅdùṅ-hàda. Ingan-ùn cònbujòg-ùro ísòṅ-gwa yaṅxim-ùl búyò badaśùmyò sòro hyòṅjeè-ùi jòṅxin-ùro hèṅdoṅ-hàyòya hànda.
Does any orthography have more grave accents than acute accents in running text? (12.12.00:18: Maybe Pinyin does if all tones are written. The falling tone written with a grave accent is a merger of five earlier tone categories [yinqu, yangqu, and parts of yangshang, yinru, and yangru] whereas the high rising tone written with an acute accent is a merger of only three earlier tone categories [yangping and parts of yinqu and yangqu].)
12.12.10.22:20: DIGR-AE-PH OR BR-Ĕ-VE?
I've been using McCune-Reischauer romanization (McR) for Korean on this blog with modifications: an h instead of an apostrophe for aspiration and sh instead of s before i. (In McR, sh is only before wi: 쉰 <suin> shwin 'fifty'; I romanize 신 <sin> as shin, whereas its McR romanization is sin.)
As I planned my post about 布哇 Phowa(e) [pʰowa] ~ [pʰowɛ], I was troubled by the digraph ae for ㅐ [ɛ] which could be mistaken for a diphthong [ae] or a vowel sequence [a e]. Yesterday afternoon I considered changing ae to ĕ to match ㅓŏ and ㅡ ŭ.
However, breves are difficult for type. Worse yet, they imply that ㅓ ŏ [ə(ː)] and ㅡ ŭ [ɯ(ː)] are shorter than ㅗ o [o] and ㅜ u [u], though they can be either short or long. Writing long [əː] and [ɯː] as ŏ̄ and ŭ̄ with breves and macrons looks like 'either short or long o and u' to me. Perhaps other diacritics could be used:
Korean vowels
| Hangul: no vowel length distinction | IPA | McCune-Reischauer (1939): no vowel length distinction | Revised Romanization of Korean (2000): no vowel length distinction | Proposal without digraphs (2012) | ||
| short | long | notes on long | ||||
| ㅏ | a(ː) | a | a | a | á | acute for length as in Hungarian, Czech, and Slovak |
| ㅐ | ɛ(ː) | ae | ae | ê | ế | accent combination also in Vietnamese though the function is different |
| ㅓ | ə(ː) | ŏ | eo (but ㅝ wo instead of *weo) | ô | ố | |
| ㅔ | e(ː) | e | e | e | é | acute for length as in Hungarian, Czech, and Slovak |
| ㅗ | o(ː) | o | o | o | ó | |
| ㅚ | ø(ː) ~ we(ː) | oe | oe | ö | ő | double acute for length as in Hungarian |
| ㅜ | u(ː) | u | u | u | ú | acute for length as in Hungarian, Czech, and Slovak |
| ㅟ | y(ː) ~ wi(ː) | wi | wi | ü | ű | double acute for length as in Hungarian |
| ㅡ | ɯ(ː) | ŭ | eu | û | û́ | does any existing orthography have this accent combination? |
| l | i(ː) | i | i | i | í | acute for length as in Hungarian |
| ㆍ (obsolete) | ʌ(ː) | a (but ă in Eckhart and the earlier French missionary system and å in Haguenauer) | (none) | â | ấ | accent combination also in Vietnamese though the function is different |
With the exception of ő, all of the accented characters in my proposal are easy for me to type with Windows 7's United States-International and Vietnamese keyboard layouts.
For years I wanted to use a single romanization system for all Asian languages
- with maximum compatibility with Sanskrit romanization
- without Anglocentric digraphs like ch and sh
The use of an acute accent for length is un-Sanskrit, but I could Sanskritize the romanization of McR consonants:
- velar: ㅇ ng > ṅ
- palatal: ㅈ ch > c, ㅊ ch' (my chh) > ch, ㅅ (when palatal) sh > ś
If I wanted to eliminate all digraphs without any regard for compatibility with Sanskrit:
- unaspirated/aspirated pairs ㄱㅋㅈㅊㄷㅌㅂㅍ [k kʰ tɕ tɕʰ t tʰ p pʰ] could be written as
g/k, j/c, d/t, b/p
instead of
k/kh, c/ch, t/th, p/ph- reinforced consonants ㄲㅉㅆㄸㅃ [k͈ tɕ͈ s͈ t͈ p͈] could be written as
ḱ, ć, ś, t́, ṕ (does any existing orthography have t́?)
with an acute accent for 'length' instead of
kk, cc, ss, tt, ppand palatal ㅅ [ɕ] and reinforced palatal ㅆ [ɕ͈] would be š with a háček (continuing the Czech and Slovak influence, though š is Cz/Sl [ʃ], not [ɕ]) and š́ with an acute atop a háček (is this in any existing orthography?).
These proposals are just for fun. This excerpt from the Universal Declaration of Human Rights (세계인권선언 Ségye ingwôn sônôn) will probably be the only example of text in my no-digraph romanization:
모든 인간은 태어날 때부터 자유로우며 그 존엄과 권리에 있어 동등하다. 인간은 천부적으로 이성과 양심을 부여받았으며 서로 형제애의 정신으로 행동하여야 한다.
Módûn ingan-ûn têônal t́ê-butô jâyuroumyô gû jonôm-gwa gwôlli-e iśô doṅdûṅ-hâda. Ingan-ûn cônbujôg-ûro ísôṅ-gwa yaṅšim-ûl búyô badaśûmyô sôro hyôṅjeê-ûi jôṅšin-ûro hêṅdoṅ-hâyôya hânda.
There are hardly any long vowels since vowel length is only distinctive in first syllables (and only for older speakers). I have archaized the romanization a bit so I can demonstrate the usage of â.
12.12.9.23:00: WHY 'CLOTH CRY'?
On December 7, the 71st anniversary of the Pearl Harbor attack, I found a December 9, 1941 毎日申報 Maeil shinbo article about it. The newspaper's Korean name for Hawaii was 布哇, read as 포와 Phowa or more rarely 포왜 Phowae, the reading used by the National Digital Library of Korea. Both are very different from modern 하와이 Hawai 'Hawaii'. (哇 can also be read as hwa and kyu, but 布哇 is never read *Phohwa or *Phogyu with -k- becoming -g- between -o- and -y-.) The spelling 布哇 'cloth-cry' was taken from Japanese 布哇 Hawai 'Hawaii'.
One might think that 布 and 哇 are respectively read as ha and wai in Japanese, but they are never read that way except in 布哇 Hawai. 布哇 looks like it should be read as *Fuwa or *Fuai in Japanese. I learned the spelling 布哇 around 1987 and have been wondering about it for a quarter-century. A solution finally occurred to me on Friday afternoon:
1. Hawaii has an Anglicized pronunciation [həʹwaj] with an unstressed first vowel.
2. A Japanese speaker could have heard [həʹwaj] as if it were [h(u)waj] and approximated it in Japanese as 布哇 Fuai.
3. Later the name was reborrowed as Hawai (influenced by its English spelling Hawaii*) and was assigned to the existing kanji spelling 布哇.
In short, the spelling reflects an 'ear-borrowing' and the pronunciation reflects a later 'eye-borrowing'. But is there any evidence for an earlier reading Fuai for 布哇?
Sometimes kanji spellings that make little sense in Japanese turn out to be Chinese-based, but Chinese readings like Mandarin Buwa, Cantonese Bouwa, etc. also have an unexpected initial and lack -i. So I think the explanation must involve Japanese.
*I presume that 布哇 was coined in the 19th century before the spelling Hawai'i caught on in English.