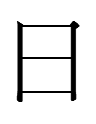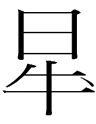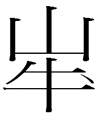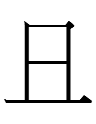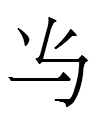

11.10.15.23:59: THE DOTTED OX
Neither Khitan large script graph for 'ox' from "Oxen in Khitan"
strongly resembles Chinese 牛 'ox', but near-lookalikes are in the Khitan large script spellings of
~
muɣoo 'snake' (cf. Written Mongolian moɣai 'id.')
po(o) 'monkey' (no known cognates?)
even though neither word refers to oxen.
The readings are based on Kane's (2009) interpretations of the Khitan small script spellings
The dotted cow
<mu.ɣo.o> 'snake'
~
<p.o> ~ <p.o.o.> 'monkey'
Why was
read o? Could o reflect a Japonic reading like *osi (cf. Jpn ushi 'ox') for a graph resembling 牛 in the Bohai script that Janhunen hypothesized as the precusor of the Khitan large script? A Japonic language was once spoken in Koguryo, and Bohai was founded by a Koguryo general, so it's possible that there were Japonic speakers in Bohai. (However, Vovin 2007 has noted that there are no known Japonic loans in languages of the area.)
The daily dilemma
The Khitan large script graph for 'day'
is identical to Chinese 日 'day'. The History of the Liao Dynasty tells us that the Khitan word for 'day' was 捏咿兒, possibly a transcription of neir(i) (cf. Written Mongolian nara(n) 'sun'). So perhaps the Khitan large and small script graphs for 'day'
were both pronounced like neir(i). However,
muɣoo 'snake'
doesn't contain neir(i) as all. Did the Khitan graphs for 'day' have another reading muɣ(o) in other contexts? In a worst case scenario, those graphs would have as many readings as 日 in Japanese:
二日 futsuka 'two days'
春日 Kasuga (a name)
日下 Kusaka (a name)
日々 hibi 'days' (々 = repeat sign; two readings of 日 in a row)
日向 Hyuuga (a name)
日本 Nihon ~ Nippon 'Japan'
日東 Nittou (a name)
日産 Nissan (a name; 日 = [nis])
日清 Nisshin (a name; 日 = [niɕ])
日光 Nikkou (a name)
一日 ichinichi 'one day'
昨日sakujitsu 'yesterday'
In several cases, a sequence of graphs has an idiomatic reading:
The stacked snake一日 tsuitachi 'first of the month' (lit. 'moonrise'; same characters as ichinichi 'one day'!)
一昨日 ototoi 'day before yesterday'
明日ashita 'tomorrow'
明後日asatte 'day after tomorrow'
日下 Kusaka (a name)
Do Khitan large script graphs like
muɣoo 'snake'
predate or postdate the invention of the Khitan small script in which such stacks are the norm? All dated Khitan texts so far postdate the invention of the small script c. 925, so we cannot look for stacks in texts from the brief five-year period (920-925) between the invention of the two scripts. However, we could see if stacks appear throughout the Khitan large script corpus or are only in texts from certain periods or regions.
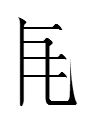
The mysterious mountainThe Khitan large script graph
resembling Chinese 山 'mountain' (pronounced something like *ʃan in the dialect known to the Khitan) was read as śan by itself (Kane 2009: 181). So what is it doing at the top of
po(o) 'monkey'
which was also written
Were
and
interchangeable in other contexts? The first graph looks like 山 with its center stroke detached and rotated 90 degrees. Did both graphs represent a Khitan word po 'mountain' (homophonous with
po 'time'
which had its own large script graph)? Or was the use of 山 to represent po a carryover from some Bohai language with a word like *po for 'mountain'? I know of no Mongolic, Tungusic, Koreanic, or Japonic word like *po meaning 'mountain'.
10.16.00:1:24: Addendum: half a clawKane (2009: 175) listed yet another Khitan large script graph for 'snake'
that is not in his lists of "The twelve zodiac animals" (p. 176) or "Glossary of basic words in the Kitan large script" (pp. 182-184). Was this graph also pronounced muɣoo, or was it an unrelated synonym? Do its components which resemble Chinese 爪 'claw' and 半 'half' (which can be written with 八 instead of \ /) indicate that Khitan or some language in Bohai had words for 'claw' and/or 'half' like parts of muɣoo? Is the 'half'-like bottom half simply a variant of the dotted ox graph, or vice versa?
11.10.14.23:45: AN-CERTAIN ABOUT OXEN IN JURCHEN
The Jurchen (large?) script resembles the Khitan large script (Kane 1989: 24), but is not close enough to be a key to it. The Jurchen graph for 'ox'
wihan > ihan (cf. Manchu ihan)
doesn't look like either Khitan large script graph for 'ox' from my last post
but does look like Chinese 中 'center' plus a dot at the bottom right. Jin (1984: 128) listed no origin for the Jurchen graph. However, I wonder if it is from Chinese 牛 'ox' or its dotted Khitan large script near-lookalike
(more on this graph soon)
with the sides closed and an additional stroke to distinguish it from Chinese 中.
Later on, Jurchen (w)ihan was written with a redundant phonetic clarifier -an:
<(w)ihan.an> = (w)ihan
See Kane (1989: 28-29) for other examples of Jurchen words with early one-character spellings and later two- or even three-character spellings.
The origin of -an is ... an-unknown*.
I had difficulty finding the entry for -an on p. 80 of Jin (1984) because I confused it with
(reading/meaning unknown)
on p. 113 with two vertical strokes and a shorter southwest-pointing stroke.
Kane's (1989: 27, 29) handwritten -an looks like a compromise between
and
Neither should be confused with Chinese 米 'rice'.
*10.15.10:15: an- is Sanskrit for 'not', and the bottom halves of the Jurchen graph for -an and its near-lookalikes resemble Chinese 不 'not'. Janhunen (1994) hypothesized that the Khitan and Jurchen large scripts were based on an unattested Bohai script. If such a script existed, it might reflect a Koreanic language spoken in Bohai ... and Korean for 'not' is 안 an. Could
-an
be based on a Bohai 不-based graph for a Koreanic word *an 'not'?
11.10.13.23:57: OXEN IN KHITAN
Since I wrote about oxen in my last post and I wanted to write about Khitan next, I thought I'd combine the two topics into one here.go
The vocabulary of Khitan is largely unknown, though each discovered text has the potential to reveal new words. Unfortunately, most Khitan texts so far have been in the memorial genre, so they give us a very limited view of the Khitan lexicon. The only (?) animal names that have been identified so far in the Khitan scripts are the names of the twelve animals associated with the Earthly Branches. See table 2.2 of Andrew West's "A Mirror on the Khitan Language" for a complete list. In this post, I only want to look at the Khitan spellings for 'ox' which are completely different in the large and small scripts.
Large script 'ox'
Kane (2009: 176, 180) lists two different graphs:
Could these be derived from Chinese 牛 'ox' and/or 丑 'ox (Earthly Branch)'? Many Chinese characters were recycled as is in the Khitan large script: e.g.,
一 二 三 五 十 廿 百 'one, two, three, five, ten, twenty, hundred' (but not other numerals!)
夏 冬 'winter, summer' (but not 'autumn' which is 禾, the left half of Chinese 秋 'autumn'; 'spring' is unknown)
東 南 北 'east, south, north' (but not 'west'?; all three have variants differing slightly from the Chinese originals)
But no such perfectly recycled characters were used to write the names of the twelve animals, though there are some partial and surprising recyclings that I'm saving for my next post on Khitan. Is this absence of fully recycled animal graphs significant?
Small script 'ox'
looks just like the Chinese character 杏 'apricot'. Why? I have a hypothesis that I'll reveal later. For now, I just want to point out that this small script character also appears in the word for 'night':
The first character in that cluster is ![]() <s>,
so 'night' and
'ox' must rhyme:
<s>,
so 'night' and
'ox' must rhyme:
'night' = <s> + X
'ox' = X
The Written Mongolian words for 'night' and 'cow' almost fit this pattern:
söni 'night'
üniye(n) 'cow'
ö/üni = X?
Assuming that the Khitan words are cognates, Kane (2009) transcribed X 'cow' as <uni>, so 'night' is <s> + X = <s.uni>. On p. 180, Kane mentioned that the second large script character for 'ox' represented *ni in *suni 'night', but did not include 'night' in his "Glossary of basic words in the Kitan large script" (pp. 182-184). Was the large script spelling of 'night' something like
<su.(u)ni>?
Next: The Dotted Ox
11.10.12.23:59: A IS FOR OX
I have often written the names of people I know in extinct scripts on this site to show my appreciation for them. No language, no script is dead as long as it is used.
But I've never seen anyone write my name in an extinct script until Michael Netzer honored me with his calligraphic gift yesterday. Thank you, Michael. I remain deeply moved by your generosity.
Beneath the modern Hebrew spelling אמריטאס of Amritas are the prototypes of each of those letters - and of letters in four other major modern alphabets:
| Drawing of | Transliteration | Letter name | Modern Hebrew | Arabic | Greek | Cyrillic | Latin |
| ox's head | ʔ | ʔaleph | א | ا | Α | А | A |
| water | m | mem | מ | م | Μ | М | M |
| human head | r | resh | ר | ر | Ρ | Р | R |
| hand | y | yodh | י | ي | Ι | І (not И!) | I |
| wheel | ṭ | teth | ט | ط | Θ | Ѳ (extinct) | none |
| ox's head (again) | see above | ||||||
| peg | s | samekh | ס | none |
Ξ | Ѯ (extinct) | none |
The names of the letters (from Swiggers 1996: 262) are acrophonic:
Acrophony (English pronunciation: /əˈkrɒfəni/; Greek: ἄκρος akros uppermost + φωνή phone sound) is the naming of letters of an alphabetic writing system so that a letter's name begins with the letter itself.
The first letter is my favorite:
The name [ʔ]aleph is derived from the West Semitic word for "ox", and the shape of the letter derives from a Proto-Sinaitic glyph based on a hieroglyph depicting an ox's head
Yesterday I realized that the English translation of ʔaleph is ox [ʔaks] in my dialect. The ox head has come full circle*.
Next: Oxen in Khitan
*10.13.7:39: The ox head rotated a lot in Greece. It was written pointing leftward, rightward, or even downward as well as upward. If things had, uh, turned out differently, the first letter in the Greek, Cyrillic, and Latin alphabets would have been ∀.
11.10.11.3:33: SERADE TUMU AISE!
Today is a friend's
birthday
and I wish to tell her in Khitan (in Andrew West's font),
Serade tumu aise!
'To Sarah, ten thousand years (of life)!' = 'Long live Sarah!'
The above words are in the Khitan 'small script' which largely consists of polygrams (blocks of assembled components). Each polygram corresponds to a word. Let's start with the most important polygram:
Serade
which can be broken up into
=
+
Sera 'Sarah' = se + ra
and
de 'to'
Khitan -de 'to' follows nouns, so Sera-de = 'to Sarah'.
tumu 'ten thousand'
isn't combined with anything. It's a logogram - a graph representing an entire word.
The se of Sera appears again at the end of
=
+
aise 'years' = ai 'year' + -se 'plural ending'
The resemblance between the English plural ending -s and the Khitan plural ending -se is coincidental.
The reading of the Khitan expression for 'birthday' is only partly known:
'birthday' = ?-én ?
The first component
means 'born' and is combined with the feminine ending -én indicating that a female was born:
If a male was born, 'birthday' would be
'birthday' = ?-er ?
with the male ending
-er
after 'born'. (One could remember it signified males by thinking of German er 'he'.)
The reading of the logogram
'day'
is unknown.
Sarah's name
Sera
has the same first two syllables as
Serahadiń
father of Abaoji (872-926), founder of the Liao Dynasty. Both the Khitan large script (not shown here; see my previous post) and the Khitan small script (in all of the above examples) were invented during the last years of Abaoji's reign. The inventor of the small script was none other than Abaoji's brother Diela:
Uighur messengers came to [the Liao] court, but there was no one who could understand their language. The empress said to T'ai-tsu [= Abaoji], "Tieh-la [= Diela] is clever. He may be sent to welcome them." By being in their company for twenty days he was able to learn their spoken language and script. Then he created [a script of] smaller Ch'i-tan [= Khitan] characters which, though few in number, covered everything [in the Khitan language].
- History of the Liao Dynasty, tr. by Wittfogel and Fêng (1949)
11.10.10.23:59: "THE FIRST FIND OF ITS KIND"
Today Andrew West told me about Viacheslav Zaytsev's identification of a Khitan large script manuscript - "the first of its kind". Until now, as Andrew wrote last year,
It is almost certain that the Khitans would also have produced dictionaries and phonological texts [like the Chinese and the Tangut], but due to the accidents of geography not a single manuscript or printed text in the Khitan [scripts] has survived.
I haven't seen this manuscript yet and know nothing about it save the fact of its existence. I have three questions:
1. Where was it found?
2. What is it about? Almost all surviving Khitan texts are memorials. We know almost nothing about Khitan words not used in that genre. A Khitan nonmemorial text would reveal a heretofore unknown dimension of the language. The problem is that such a text would be difficult or impossible to read in the absence of a bilingual because it would contain many unidentified graphs. One cannot guess the meanings or readings of Khitan large script graphs on the basis of their similarity to Chinese: e.g.,
| Shape | 10th century NE Chinese | Khitan large script (Kane 2009) | ||
| Reading | Meaning | Reading | Meaning | |
| 至 | *tʃi | to arrive | -an | genitive suffix |
| 午 | *wu | horse (7th Earthly Branch) | iri | name |
| 未 | *wi | sheep (8th Earthly Branch); not yet | o | phonetic symbol |
| 夫 | *fu | man | ś | |
| 坐 | *tso | to sit | oi | |
| 玖 | *kiu | nine | ? | ninety (not 'nine'!) |
3. When was it written? Could it predate the earliest known large script inscription from 986 which was written over sixty years after the large script was said to have been devised in 920? Or is the manuscript from the non-Khitan Jin Dynasty? Although the Khitan state fell in 1125, the Khitan language and both of its scripts were still in official use during the Jin Dynasty until 1191-1192.
10.11.00:33: What if the manuscript were from the Kara-Khitan Khanate? Would that be too much to hope for? Probably.
11.10.9.23:54: TWO TALL FAMILIES
In my last entry, I wrote Michael Netzer's name with
1kew
which is a Tangut transcription character for Tangut period northwestern Chinese 高 *kaw 'high'.
And right before that, I was wondering why Steve Jobs' surname was written as 喬布斯 Qiaobusi in Mandarin with Q- [tɕh]. 喬 also means 'high'. Schuessler's (2007: 428) entry on 喬 lists a number of potential cognates including 高 *kau 'high'. Let me try to reconstruct an expanded version of his proposed word family using my hypothesis about presyllables and (de)emphasis in Old Chinese:
Root: 高 *kaw > *kaw 'high' (*low vowel > *emphatic)
Derivatives with high vowel presyllabic prefix conditioning deemphasis:
Presyllable fusing with root initial and voicing it:
喬 *Nɯ-kaw > *Nɯ-kɨaw > *Nkɨaw > *Ngɨaw > *ŋgɨaw > *gɨaw 'tall'
嶠 *Nɯ-kaw-s > *Nɯ-kɨawh > *Nkɨawh > *Ngɨawh > *ŋgɨawh > *gɨawh 'peak'
蹻 *Nɯ-kaw-k > *Nɯ-kɨawk > *Nkɨawk > *Ngɨawk > *ŋgɨawk > *gɨak 'to lift the feet high'
With root vowel ablaut?:
翹 *Nɯ-kew > *Nɯ-kiew > *Nkiew > *Ngiew > *ŋgiew > *giew 'tall'
but 翹 could be from 堯 *ŋew 'high'
did a prefix cause root *ŋ- to become *g- in 翹?
could 堯 *ŋew also be derived from 高 *kaw?
were there two waves of *NC-fusion in Old Chinese with different outcomes?
early wave:
*N-k- > *ŋ- in 堯
later wave:
*N-k- > *g- in 翹
Presyllable lost; did not fuse with root initial; only left trace in root vowel
憍 *Cɯ-kaw > *Cɯ-kɨaw > *kɨaw 'high, proud, arrogant, to lift the head'
憍 *Cɯ-kaw-ʔ > *Cɯ-kɨaw-ʔ > *kɨawʔ 'to lift, to elevate, high'
Derivatives with low or no vowel presyllabic prefix + vowel ablaut
zero (or schwa?) grade:
皋 *Cʌ-k(ə)w > *ku > *kaw 'high, high land along the water's edge'
but the Taiwanese variants dictionary and Mandarin dictionary also define it as 'lowland'!
隺 *Nʌ-k(ə)w-k > *guk > *gouk 'high'
隺 *rʌ-k(ə)w-k > *gruk > *gɔk 'high spirits'
dubious semantic parallel:
告 *Cʌ-k(ə)w-k(-s) > *kuk(s) > *kowk, *kawh 'to announce'
cf. English raise, bring up (in a discussion)
if this is a source for Thai กล่าว klaaw 'to say', then they cannot be related to *k-w which lacks root-medial *-l-
Baxter and Sagart also reconstruct 皋 *kˤu (= my *Cʌ-k(ə)w) 'to announce' without *-k, but I'd reconstruct *Nʌ-k(ə)w since Jiyun fanqie indicate Middle Chinese *g-
號 *Nʌ-k(ə)w-s > *gus > *gawh 'to call'
*a-grade:
隺 *N(ʌ)-kaw-k > *gawk > *gak 'to fly high' (of birds)
is its homophone 鶴 'crane' derived from 'bird that flies high'?
nasal prefix cannot be Sagart's (1999: 85) *m-prefix for the "names of small animals" since a crane is not a small animal
Extremely speculative: double nasal affixation?
The presyllabic vowel of 卬 could have been high and lost before it could condition deemphasis. Or it could have been low or nonexistent.卬 *N(V)-kaw-k-N > *ŋaŋ > *ŋaŋ 'high, to lift high'
仰 *Nɯ-kaw-k-N-ʔ > *ŋaŋʔ > *ŋɨaŋʔ 'to lift the face, look up'
The Tangut word family for
2bie < *Cɯ-be-H 'high'
potential Qiangic and rGyalrongic cognates suggest a nasal preinitial and medial *-r-
is much smaller. Gong (2002: 53) listed only two cognates:
1biə < *bə 'high'; may have originated as part of reduplicative expression 1biə 2bie 'high'
1biẹ < *Sɯ-be 'to heighten, elevate, promote'
The first cognate 1biə 'high' is homophonous with the first half of the reduplicative expression
1biə 2bi < *bə-bi-H 'low'
whose root is 2bi 'low'.
The second cognate 1biẹ 'to heighten' is parallel in structure to
1bị < *S(ɯ)-bi 'to lower'
which is almost homophonous with the first half of
1bi 2bie 'low and high'
whose structure is parallel to modern Longxi Qiang bè bó 'height' (lit. 'low-high'). Unlike 2bi 'low', 1bi 'low' does not by itself. Is 1bi a reduced (*-H-less) form of 2bi, or is 2bi an *-H-suffixed derivative of an original *bi retained only in the compound?
11.10.9.20:02: ME KEU NE TSIR E MY VI NY
I wish
Me keu Ne tsir = 'eye high* king earth' = 'Earthly King of the High Eye**'
a
my vi ny be re 'happy birthday'
in the
Mi gu 'Tangut language'
which is extinct ... except here in Amaravati.
*Keu does not, strictly speaking, mean 'high' in Tangut. It is the Tangutization of 11th century Chinese 高 kaw 'high'. The graph for keu is a combination of 'person' and 'high':
=
+
**Tsir is normally a noun 'earth', but I intend it to be interpreted as an adjective modifying the preceding noun.is
Tangut has noun-adjective and possessor-possessed order, so
Me 'eye' + keu 'high' = 'high eye'
Ne 'king' + tsir 'earthly' + 'earthly' = 'earthly king'
my vi ny 'birthday' + be re 'happy' = 'happy birthday'
and
Me keu 'eye high' + Ne tsir 'king earthly' = 'high eye's earthly king' or 'earthly king of the high eye'
my vi 'birth' + ny 'day' = 'birthday'