




10.9.25.23:59: THE GOLDEN GUIDE: LINE 81: TANGRAPHS 401-405
81. The Tangut word for 'Uyghur' looks like a loan from Middle Chinese 回鶻 *ɣwə ɣwət 'Uyghur'; it has a ɣ- absent from modern Uyghur Uyghur (reborrowed into Mandarin as 維吾爾 Weiwuer; hear both here) and from Tangut period northwestern Chinese *xwe xwə. Did the Uyghur autonym once begin with a fricative?
| Tangraph number | 401 | 402 | 403 | 404 | 405 |
| Tangraph | |
|
|
|
|
| Li Fanwen number | 2062 | 3564 | 3065 | 2739 | 1996 |
| My reconstructed pronunciation | 1ɣwe | 1ɣwə | 1lhiu | 2tshwiəʳ | 2die |
| Tangraph gloss | Uyghur | milk; butter | vinegar; bitter | to drink | |
| Word | whey | ||||
| Translation | The Uyghur drink whey. | ||||
401: The first half of 'Uyghur' is derived from the second half:
2062 1ɣwe 'Uy(ghur)' (diazax) =
3564 1ɣwə '(Uy)ghur' (diabuepik) +
5173 0dʒɨə 'to pull up; rescue' (terzax)
Why dia instead of dex? I presume that
=
+
2078 1thəu 'to draw a bow' (dexzax) =
2495 1dʊ 'to exist, have; to place' (dexjoldex) +
5173 0dʒɨə 'to pull up; rescue' (terzax)
was created first, so dia was chosen to avoid a second dexzax even though there are a handful of tangraphs with double readings: e.g., 4456/4457. Oddly, dex 'person' is more appropriate for 'Uy(ghur)' than in 'to draw a bow'.
Although tangraphs for 'Chinese' have the radical 'bug' (jio), tangraphs for names of non-Chinese, non-Tangut groups do not have insulting radicals.
zax by itself
1lo 'filter'
seems to have no relevance to 'Uyghur'.
402: The second half of 'Uyghur' is derived from the first half:
3564 1ɣwə '(Uy)ghur' (diabuepik) =
2062 1ɣwe 'Uy(ghur)' (diazax) +
1770 1lhwi 'to take, gain' (buepik)
There is no dexbuepik, so dia was presumably chosen to parallel diazax.
1lhwi does not sound like '(Uy)ghur'. Is it semantic?
403: 3065 has a circular derivation:
+

3065 1lhiu 'milk, butter' (cirzio) =
0053 2niọ 'milk' (fexcirzio) +
1338 1dzəu 'to love, like' (bixdiibaedex = zio)
+
0053 2niọ 'milk' (fexcirzio) =
0092 1mia 'mother' (fexbilbilcin) +
3065 1lhiu 'milk, butter' (cirzio)
9.26.2:29: I presume 3065 was created before 0053. cir in 3065 is 'water', so is milk the water of love?
+
'milk' = 'water' + 'love'?
404: Li Fanwen (2008: 449) regarded 2739 as a Chinese loanword, though 2tshwiəʳ 'vinegar' does not resemble the Tangut period northwestern Chinese readings of Li's translations 醋 *tshu 'vinegar', 酸 *swã 'acid', 醬 *tsiõ 'sauce', 辛 *sĩ 'bitter'. Nie and Shi (1995) translated 2739 as 浆 *tsiõ 'syrup' (醬 'sauce' has a different tone).
9.26.1:21: 2739 looks like 'person' (dex) + the left of 1079 'sweet' (cuo) + 'ice' (coe). Hardly components I'd expect in 'vinegar'.
405: 1996 'drink' (analysis unknown) is clearly from 'water' (cir) plus 'mouth' (buk) plus a right-hand radical of unknown function (dal).
10.9.24.23:59: END OF THE EYE, END OF THE FACE
Wikipedia's "In the News" column featured this article on Kosmeratops tonight. The name is
from Ancient Greek κόσμος (kosmos "ornament, decoration"), κέρας (keras, "horn") and ὤψ (ōps, "face")
Kosmos has a wide range of meanings, including 'cosmos'.
Keras is cognate to Latin cornu (e.g., unicorn 'one-horn') and English horn.
Ōps 'face' originally meant 'eye'. It has the same root as optic. It is even cognate to English eye, despite the lack of phonetic similarity.
The use of 'eye' for 'face' reminds me of Vietnamese
mắt 'eye' < *hmat
traditionally written as 末 mạt 'end' (phonetic) plus 目 mục 'eye' (semantic)
mặt 'face' < *mat
traditionally written as 末 mạt 'end' (phonetic) plus 面 diện 'face' (semantic)
Their different tones (indicated with an acute accent and a subscript dot) reflect earlier different initial consonants (*hm- and *m-). Could these two words be cognate? Do they share a common root *(h)mat? Is the *hm- of 'eye' from a voiceless prefix plus *m-, or is the *m- of 'face' from a voiced prefix plus *hm-?
9.25.10:50: The root *mat 'eye' is widespread throughout Austroasiatic.
Is its resemblance to Proto-Austronesian *maCa 'eye' (often mata in Austronesian languages) and Proto-Kra *m-ʈa (Ostapirat 2000: 220; cognate to Thai taa 'id.') coincidental? Did Proto-Austroasiatic, Proto-Austronesian, and Proto-Kra-Dai (ancestor of the Kra languages and Thai) each borrow it from an extinct Southeast Asian substratum language? Or was it borrowed from one into the others?
As a general rule, Tangut alveolar and alveopalatal (retroflex?) fricatives and affricates are in complementary distribution:
| Tangut Initial \ Grade | I | II | III | IV |
| Alveolars (ts- tsh- dz- s- z-) | yes | no | no | |
| Alveopalatals (tʃ- tʃh- dʒ- ʃ- ʒ-) | no | yes | yes | |
This pattern is similar to that of Middle Chinese and surely reflects Chinese influence.
But there are exceptions to this pattern. I found one last night:
has a Grade I/IV initial dz- with a Grade III rhyme -ɨu.
4973 1dzɨu 'love'
It must be cognate to the Grade I word
1338 1dzəu 'to love, like'
I normally derive -əu and -ɨu from pre-Tangut *-u, but likely cognates in Sino-Tibetan end in -ə or -a (see Schuessler 2007: 633 for details):
Old Chinese 慈 *dzə 'affectionate, loving, kind' < *N-ts-
Written Tibetan mdzaH-ba 'to love'
Written Burmese caa 'to sympathize with; be considerate to; have consideration for'
The -u of 'love' may be from a pre-Tangut *-k:
*dzək > 1dzəuGrade IV 2dziu never had this *-k:*Cɯ-dzək > *Cɯ-dzɨək > 1dzɨu
*Cɯ-dzuH > *Cɯ-dziuH > 2dziu
*-k in the words for 'love' may be the "sporadically attested velar suffix *-k that occurs mostly after verb roots" discussed in Matisoff (2003: 479):
9.24.1:28: I presume that the complementary distribution of tones in dzVu-syllables is coincidental:
| Syllable \ Tone | Tone 1 ('Level Tone') | Tone 2 ('Rising Tone') |
| Grade III dzɨu |
    1dzɨu |
(no 2dzɨu!) |
| Grade IV dziu |
(no 1dziu!) |    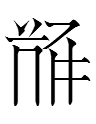 2dziu |
In Homophones (29A35-29A44), the four Grade IV 2dziu tangraphs were placed in one group with the four Grade III 1dzɨu tangraphs directly following them. Does this imply that the two were considered nearly homophonous? I wonder if both groups were Grade IV dziu in some Tangut dialects.
10.9.22.23:55: THE GOLDEN GUIDE: LINE 80: TANGRAPHS 396-400
80. This concludes the first forty percent of the Golden Guide. I can't believe it took me ten days to finish this entry. I worked on it a bit last week, then left it untouched from last Tuesday until tonight.
| Tangraph number | 396 | 397 | 398 | 399 | 400 |
| Tangraph |  |
 |
 |
 |
|
| Li Fanwen number | 5882 | 0010 | 2764 | 4797 | 1338 |
| My reconstructed pronunciation | 1zaʳ | 2zi | 1məuʳ | 2ʔwɨəʳ | 1dzəu |
| Tangraph gloss | Chinese | all | vulgar, stupid | writing | to love, like |
| Word | |||||
| Translation | The Chinese all like vulgar writing. | ||||
396: I have no idea why the Chinese were called 1zaʳ, a name that doesn't resemble any Chinese autonym: e.g., Han. 1zaʳ could be an extended usage of a native Tangut word: e.g., 1zaʳ 'pungent'. Could 1zaʳ be cognate to Ronghong Qiang ʁəʳ 'Chinese'?
5882 looks like gux 'small' + jio 'bug', indicating what the Tangut thought of the Chinese. Its analysis is circular. Although the analysis of 2431 is unknown, it surely must derive from 5882:
+
5882 1zaʳ 'Chinese' (guxjio) =
2431 2khwa 'Chinese' (barguxjio; semantic) +
1887 1kie 'bug' (jio; semantic)
2431 2khwa also doesn't sound like any Chinese autonym. I can't find any plausible Tangut-internal etymology. The tangraph may have 亻 bar, the left side of 2730 2khwa 'cloth', as a phonetic:
?
The radical bar resembles Chinese 亻 'person' but may actually be derived from 禾, the left side of Tangut period northwestern Chinese 科 *khwo < Middle Chinese *khwa.
397: 0010 has a circular analysis:
+
0010 2zi 'all' (bambuoheu) =
0027 2ŋõʳ 'every' (bambuocia; semantic) +
4683 2to 'all' (biobuoheu; semantic)
=
+
4683 2to 'all' (biobuoheu) =
4859 2to 'end' (top of wei; phonetic)
0010 2zi 'all' (bambuoheu; semantic)
Was wei really abbreviated as bio, or is wei a homophone whose upper part happened to match the bio of 4683 which is from some other tangraph?
398: 2764 1məuʳ 'vulgar, stupid' is an extended use of 1məuʳ 'black' which is on its right side:
+
2764 1məuʳ 'vulgar, stupid' (dexgirdilcin) =
2914 1biẹ 'stupid' (ciadexfak) +
3925 1məuʳ 'black' (girdilcin)
I doubt the dex of 2764 was extracted from the center of 2914. But what is that dex doing? Is it merely an arbitrary addition to distinguish 2764 from 3925?
1məuʳ 'black' may be from a pre-Tangut *r-mək cognate to Old Chinese 黑 *hmək (< *s-mək?) 'black'.
399: 4797 may be derived from Chinese 文 'writing', though its shape reminds me of Chinese 夜 'night'
2ʔwɨəʳ vaguely resembles Tangut period northwestern Chinese *wə̃, but the latter lacks an initial glottal stop. Could that glottal stop be a native Tangut prefix? The retroflexion of the Tangut vowel may correspond to the Chinese nasal vowel: cf. the borrowing of Mandarin -n and -ŋ as vowel retroflexion in Ronghong Qiang ̣(LaPolla and Huang 1996: 28).
1məuʳ 2ʔwɨəʳ 'vulgar writing'
might refer to sinography.
400: 1338 has a circular analysis. 2963 must postdate 1338, rather than the other way around. 1338 may have originated as a drawing of two people (dii and dex, if dii is 'person' like dex) plus other lines which may indicate a loving relationship between them.
+
1338 1dzəu 'to love, like' (bixdiibaedex) =
2963 2no 'love' (carzio; zio = bixdiibaedex) +
4973 1dzɨu 'love' (biodiibaedex)
+
4973 1dzɨu 'love' (biodiibaedex) =
4868 2gii 'hope' (biofeafer) +
1338 1dzəu 'to love, like' (bixdiibaedex)
9.23.0:10: 1dzəu 'love' and 1dzɨu 'love' are probably cognate to each other and perhaps even to Old Chinese 慈 *dzə 'affectionate, loving, kind'. I'll discuss these words tomorrow.
I was looking at the December 30, 1944 editorial page of the Korean newspaper 每日申報 Maeil Shinbo and realized I was simultaneously reading left to right and right to left within the same line: e.g.,
| Text | 活 | 生 | 戰 | 决 | 과 | 策 | 對 | 레 | 푸 | 인 |
| Letter breakdown | n/a | ㄱㅗㅏ | n/a | ㄹㅔ | ㅍ ㅜ |
ㅇㅣ ㄴ |
||||
| Letter breakdown (romanized) | k o a | r e | ph u |
Ø i n |
||||||
| Chinese character readings | hwal | saeng | chŏn | kyŏl | n/a | chaek | tae | n/a | ||
| Words | saenghwal | kyŏlchŏn | kwa | taechaek | inphure | |||||
| Gloss | life | decisive battle | and | policy | inflation | |||||
| Reading of entire line | inphure taechaek kwa kyŏlchŏn saenghwal | |||||||||
| Translation of entire line | Inflation Policy and Life During a Decisive Battle | |||||||||
The Chinese characters and Korean letter combinations are read from right to left, but the letters within each letter combination are read from left to right! (Or top to bottom: e.g., 푸 phu is ㅍ ph over ㅜ u.)
Did Koreans reading this kind of text process Korean letter combinations as units or as letter sequences? Did they see 인 as in (a unit) or as Ø-i-n (a sequence of three letters)?
Modern Korean is written from left to right, so directions are no longer mixed within a single line.
Notes on words:
inphure is probably from Japanese インフレ infure. (Korean has no f.) This word belongs to a class of English-through-Japanese loans that has been replaced by direct English loans. The current Korean word 인플레 inphŭlle has a -ll- that is closer to the -l- of inflation than the earlier -r- from Japanese -r-. (Korean does not allow a single -l- between vowels.)
The Korean alphabet has no letter for w. Korean -w- is spelled as either -o- or -u- depending on the following vowel. -o- precedes 'yang' (low) vowels and -u- precedes 'yin' (high) vowels. Hence kwa is spelled k-o-a.
The Chinese character 决 kyŏl 'decide' is now obsolete in Korea. I cannot find it in the Korean dictionaries I have on hand. They only list its basic form 決 with 氵 'water' on the left instead of 冫 'ice'. Neither radical has any obvious relevance to 'decide'. (But see below.)
Conversely, in the PRC, the basic form 決 has been replaced by the simpler variant 决.
決 originally represented Old Chinese *kmet 'open a passage for a stream'. I presume the graph was recycled for an unrelated homophone 'decide' unless 'decide' somehow originated as a metaphorical use of 'open a passage'.
I reconstruct an *m in 決 Old Chinese *kmet to account for Old Chinese 袂 *k-met ~ *kɯ-met-s (> Mandarin mei) 'sleeve' with the same phonetic. As far as I know, Bodman (1954: 64) was the first to propose medial *-m- in 袂.
Why does Korean Nobul mean 'Taoism and Buddhism'? Hints:
1. See the previous entry on rhotic aversion.
2. Who is the founder of Taoism?
3. There is no initial L- in Korean. Hence Lautrec was borrowed as Rothŭrek.
4. 'Taoism and Buddhism' is Togyo wa Bulgyo in Korean.5. Korean borrowed roots from Middle Chinese which had no final -d.
6. Middle Chinese -t became -r in northern dialects.
7. Korean no longer has a final -r.
Select the blank space below for the solution:
Korean -gyo corresponds to 'ism' in Togyo wa Bulgyo 'Taoism and Buddhism'.
The founder of Taoism is Laozi.
Given that
- Tao(ism) corresponds to Korean To
- There is no L- in Korean
- Rhotic aversion rules out R- in Korean; R- becomes N- except before i and y
Chinese Lao corresponds to Korean No. A Koreanization of half of Laozi stands for Taoism.
If Bul-gyo is Buddh-ism, then Bul is 'Buddha'.Bul is an abbreviation of Bud(dha). There is no -d in Middle Chinese, so Bud was borrowed into MC as But which developed into Bur in northern dialects. This Bur was borrowed into Korean and shifted to Bul.
(MC Bur was also borrowed into Uyghur and became the first half of Burxan 'Buddha'. The second half is 'khan' and may correspond to raja in a compound Buddharaaja 'Buddha-king' [Clauson, quoted in Drompp 2005: 232].)
10.9.19.19:36: RHOTIC AVERSION IN 'RUSSIA'
I ended my last entry with a reference to the Urum whose names begins with an u- to avoid an un-Turkish initial r-. Urum reminded me of Mongolian Oros 'Russia', borrowed into Chinese as 俄羅斯 Olosɨ, now Mandarin Éluósī, shortened to 俄 É in terms like 俄语 Éyǔ 'Russian language' (not to be confused with 恶语 èyǔ 'slander', 鳄鱼 èyú 'alligator, crocodile', or 阿谀 ēyú 'fawn on' which have different tones). 俄 É, like English bus from omnibus, doesn't contain the original root.
The graph 俄 originally represented Old Chinese *ŋaj 'in a moment'* which became Middle Chinese *ŋa, borrowed into Vietnamese over a millennium ago as nga. Hence the Vietnamese word for 'Russia' is Nga, the Vietnamese reading of 俄. Nga is even further from Oros than Mandarin É.
One might expect the Japanese and Korean monosyllabic names for Russia to be their respective readings for 俄, but in both those languages, the abbreviation of 露西亞 'Russia' is 露 Ro 'dew; reveal' which obviously corresponds to the first syllable of Россия Rossija. The initial R- of Ro marks it as a borrowing since both Japanese and Korean originally shared an aversion to initial r- with Turkish, Mongolian, and Manchu. The reason for this common aversion among 'Altaic' languages is unknown. Did these languages originally lack *r- or did they lose *r- due to mutual influence?
(Pulleyblank 1991 went further and reconstructed such an aversion in non-'Altaic' Old Chinese**, though other Chinese historical linguists frequently reconstruct initial *r- in OC.)
In Korean, Ro 'Russia' becomes No- initially due to r-aversion:
r- became n- and then zero before i and y: e.g., in these surnames borrowed from Chinese:露日 No-Il 'Russo-Japanese'
but 韓露 Han-Ro [hallo] 'Korean-Russian'
n- also became zero before i and y:李 Ri > Ni > I (usually romanized Yi, Rhee, or Lee; cf. Mandarin Li)
劉 Ryu > Nyu > Yu
니 ni > i 'tooth'
匿 nik > ik 'hide'
녓 nyes > yet 'old'
女 nyŏ > yŏ 'female'
r- > n- (and > Ø when applicable) shifts only occur in Sino-Korean readings like 露 Ro and 李 Ri.
n- > Ø shifts only occur in native words (ni 'tooth', nyes 'old') and older borrowings (匿 nik 'hide', 女 nyŏ 'female').
Recent borrowings retain r- and n-: e.g.,
러시아 Rŏshia 'Russia' (not Nŏshia; was this based on Rossija or Russia, is it a postcolonial borrowing, and was there ever a Japanese-based borrowing 로시아 Roshia < Jpn ロシア Roshia?)
리오 Rio 'Rio' (not Io)
니케 Nikhe 'Nike' (not Ikhe)
뉴욕 Nyuyok 'New York' (not Yuyok)
*俄 is no longer an independent word 'in a moment', but appears in the disyllabic word 俄顷 éqǐng 'in a moment' combined with 顷 qǐng 'a little while'.
Old Chinese 我 *ŋajʔ 'I' is phonetic in OC 俄 *ŋaj 'in a moment'. The 亻 'person' on the left appears arbitrary and is reminiscent of the many instances of the corresponding Tangut radical 'person' which also has no obvious function in many Tangut characters.
**In Pulleyblank's Old Chinese reconstruction, the unusual phonemes *ŋɥ- and *ɥ- correspond to *r- in other reconstructions.




