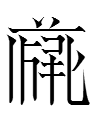
10.6.12.23:48: THE GOLDEN GUIDE: LINES 25-26: TANGRAPHS 121-130
Whew, no new GIFs to make for the ten tangraphs in these two lines!
| Tangraph number | 121 | 122 | 123 | 124 | 125 |
| Tangraph | |
|
|
|
|
| Li Fanwen number | 2019 | 1906 | 1771 | 3818 | 3678 |
| My reconstructed pronunciation | 1thia | 1nɔ̃ɔ̃ | 2siẹ | 2mieʳ | 2to |
| Tangraph gloss | 3rd person pronoun; that; other | after; also; more; besides | wisdom | suffix for persons | to be born; to rise; to climb |
| Word | |||||
| Translation | After that, the wise (people) arise, | ||||
121 has
'water' < Chinese 氵
on the left, but has nothing to do with water. The 'water' is from 2590 2vɨə, the 'outside' directional perfective prefix which also has nothing to do with water:
+
The right two-thirds are from 0388 2thia which is also a third person pronoun and distal demonstrative pronoun.
Both 1thia and 2thia sound like the Mandarin third person pronoun 他 ta [tha] and may have been borrowed from Chinese. Although I reconstruct the two thia with Grade IV -i- because they belong to rhyme 20, both were consistently transcribed in Tibetan as tha instead of thya or thiHa (Tai 2008: 246, 273). I have considered reconstructing R20 without -i- as -ea or -ɐ or -æ, but such reconstructions would require a radical redefinition of Grade IV that would be quite different from Chinese Grade IV. Did the Tangut create a grade system only loosely inspired by Chinese?
1thia, like Chinese 他, can also mean 'other; else'. One of its Tangraphic Sea definitions is the 'outside' directional perfective prefix 2590 2vɨə.
Another definition of 1thia includes 0388 2thia:
1do 2thia
1do is normally a locative suffix: e.g., 2thia-1do 'there' (九 232 in Li Fanwen 2008: 859). Li Fanwen (2008: 426, 859) translates 1do 2thia as 於其 'in its'. Is the Tangraphic Sea definition a mistake or a calque of Chinese 於其?
Inserting a radical between the two halves of 2thia results in its homophone
0396 2thia 'there'
defined in Tangraphic Sea as 'not here'. Could the center radical be from
3349 2lieʳ 'direction'?
122 has nine meanings in Li Fanwen (2008: 316-317), but only one is relevant here. Its Tibetan transcriptions nyo (x 3), nu (x 1) and its Tangut period northwestern Chinese transcription 娘 *njo make me wonder if its rhyme (1.57) should be reconstructed as Grade IV -iõo,̃ the level tone counterpart of rising tone rhyme 50 -iõo.̃
122 should not be confused with 1918 1mi 'not' on the right:
The left two-thirds of 122 is from a phonetic 2361 1nəu 'to violate':
+
The right radical is from 2312 1pe 'outer; exterior; behind' (< loan from Tangut period northwstern Chinese 背 *pej 'back'?) which is supposed to be from 2533 2diəʳ 'outer; surface' plus ...122:
=
+
My guess is that 2361 was created before 122, which in turn was created before 2312.
123 2siẹ 'wisdom' is from *Sɯ-seH, a variant of
3469 2sie < *Cɯ-seH 'passion; knowledge'
which has different radicals.
124 is a suffix indicating 'one who is':
2siẹ-2mieʳ = 'wise-person' = 'the wise'
124 is cognate to
2344 2mi 'Tangut' and 0607 1miəʳ 'people; tribe'
which in turn are cognate to Written Tibetan mi 'person'.
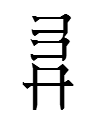
125 has a rare radical (alphacode war) which I'll discuss in my next post.
| Tangraph number | 126 | 127 | 128 | 129 | 130 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5306 | 5113 | 3740 | 1910 | 0009 |
| My reconstructed pronunciation | 1dzwiə | 1vɨi | 1kɪ | 2tiẹ | 1ʃwɨo |
| Tangraph gloss | emperor | to do; to make | commandment; Buddhist discipline | ceremony, rite, manner | to appear; to raise |
| Word | |||||
| Translation | And they establish commandments and rites for the emperor. | ||||
Nie Hongyin and Shi Jinbo translate 126 127 as 'for the emperor'. 127 is the Tangut equivalent of Chinese 爲 'to do' which can also mean 'for'. Could 127 also mean 'for'? If 127 was a verb, I would have to translate this line as 'The emperor makes; commandments and ceremonies appear' which doesn't make much sense. I assume the subject of the verb 130 is 'the wise' from the previous line.
126 is the source of the left side of the locative suffix 1do:
=
The right side is from 2815 1khəu 'to give tribute'.which shares
'sage'
with 126 'emperor'. 2815 has a circular analysis:
=
127 1vɨi 'to do' may be from pre-Tangut *vɨəi < *vəi, cognate to Old Chinese 爲 *waj 'to do'.
Guillaume Jacques (2004: 160) linked 127 to Somang rGyalrong ka-pá 'to do'. If Guillaume's etymology is correct, 1vɨi is from *Cɯ=pa with intervocalic lenition of root-initial *p-.
128 1kɪ is almost certainly from Chinese 戒 'commandment', but doesn't sound much like Middle Chinese *kɛjh or Tangut period northwestern Chinese *kɛj. I would expect Tangut *1kɛ. Could the rhyme of 1kɪ be reconstructed as -ɛi or -ʌi with a nonhigh first vowel?
The center of 128 is from 1918 1mi 'not' and the right is the radical 'pass' from 1640 1dziẹ 'to cross; to pass; to exceed':
+
Li Fanwen (2008: 317) reconstructed the analysis of 129 on page 84 of Precious Rhymes of the Tangraphic Sea as
+
2tiẹ 'rite' = 2708 1riaʳ 'to manage; ministry' + 0467 1tsiiʳ 'law'
I can't confirm this since my copy of this page is missing one of the four tangraphs and the other three are only partly visible and illegible.
2708 is in turn derived from 0467 plus the conjunction 5913 1riaʳ (phonetic):
+
which is part of an analytic chain leading back to 2708:
=
+
5913 = 5840 1kii 'commerce' (why?) + 0819 1riaʳ 'wonderful' (phonetic)
=
+
0819 = 3319 2bạ 'luxuriant; majestic' (semantic) + 2708 (phonetic)
130 1ʃwɨo 'to appear; to raise' is from the top of 0094 1ʃwɨo 'broom' (with 'grass' on the bottom left) plus the bottom of 4469 2ʃɨi 'to go' (with 'motion' on top):
+
'Broom' is from 130 (phonetic) + 2147 1riuʳ 'to sweep; broom':
I suspect that 130 was created before 'broom' and that the analysis of 130 does not reflect its true origin.
130 and 'broom' belong to the Grade III/IV rhyme 50 -wɨo/-wio which precedes Grade I rhyme 51 -(w)o, Grade II rhyme 52 -ɔ, and Grade III/IV rhyme 53 -(w)ɨo/-(w)io. I don't understand the reasoning behind this ordering or the split of -wɨo/-wio into two rhymes.
10.6.12.15:21: TANGUT L : SANSKRIT R?: SEE-ING THE RE-ASONS WHY
In "Reconstruction of a Tangut phonetic group" in Analysis of the Tangut Script, Eric Grinstead (1972: 272) noted that
2lie 'to see' (derived from Chn 見 'see' with the 目 turned sideways into a 罒 shape?)
is "[a]lso a very common phonetic in Sanskrit transcriptions for -re."
This is initially surprising because Tangut has a syllable reʳ which would be a closer match to Sanskrit re [ree], retroflexion and length aside. Tangut requires retroflex vowels after r-, and there are no long retroflex e rhymes*, though I can't imagine why the Tangut couldn't simply have a syllable reeʳ for 'Indo-Tangut' loans.
I initially thought that Tangut 2lie is based on Chinese transcriptions of Sanskrit re like
黎 Middle Chinese *lej > Tangut period NW Chn *liej (also transcribes Skt ri, rii, ra, raya, rya, ṛ, r, li, lii, la)
隸 Middle Chinese *lejh > Tangut period NW Chn *liej (also transcribes Skt le)
Chinese had no *r- at the time of the transcriptions, so Chinese *l- was the closest substitute for Sanskrit r-. Tangut 2lie would reflect both this Chinese *l- and the breaking of Early Middle Chinese *e to Late Middle Chinese (and TPNWC) *ie.
Grinstead (1972: 184) listed eight other tangraphs as transcriptions of Sanskrit r(V). If Tangut borrowed Sanskrit through Chinese, these tangraphs' readings should have initial l-. However, all but LFW2640 and LFW2643 with ph- (which may be mistakes for a similar-looking tangraph I can't identify) have r-, indicating that they must represent borrowings directly from Sanskrit or mediated through Tibetan (which preserved Sanskrit r-).
| Sanskrit | Tangraph | Li Fanwen number | Sofronov number | Rhyme | My reconstruction | Arakawa-style reconstruction | Gong Hwang-cherng reconstruction | Sofronov reconstruction |
| r(a) |  |
0795 | 5042 | R92 | 2riəʳ | 2rI:r | 2rjɨr | 2ri̭ə̣ |
| ra |   |
2643, 2640 (on p. 194) | 3723, 3729 | R43, R51 | 1piẽ, 1pho | 1phyen, 1pho | 1pjɨj, 1pho | 1pɪ̭e, 1pho |
 |
5523 | 2425 | R87 | 1riaʳ | 1ra:r | 1rjar | 1ri̭ạ | |
| ri |  |
1700 | 0309 | R84 | 2riʳ | 2ri:r | 2rjir | 2ri̭ẹ |
 |
1599 | 4911 | 1riʳ | 1ri:r | 1rjir | 1ri̭ẹ | ||
| ru |  |
5736 | 2735 | R81 | 2riuʳ | 2ryur | 2rjur | 2ri̭ụ |
| re |  |
3639 | 3693 | R79 | 2rieʳ | 2ryeq'2 | 2rjijr | 2ri̭ẹ |
Grinstead's table does not overtly include Sanskrit long vowels and has no transcriptions of Sanskrit ro.
I am not entirely sure if the conversions of my reconstructions into Arakawa's system are correct.
I hope to discuss the mismatches between the Sanskrit vowels and Tangut rhymes elsewhere.
Back to the initials: Why aren't there other instances of Sanskrit r(V) transcribed with Tangut l-? The simplest answer is contrary to Grinstead (1972: 272), 2lie 'to see' represented Sanskrit le, not re. I came to that conclusion for three reasons:
1. Grinstead's (1972: 184) handwritten table of Sanskrit transcriptions equates 2lie 'to see' with Sanskrit le, not re. Although the table is generally in Indic alphabetic order, for some reason the r- and l-rows which should be adjacent are separated by three sibilant rows. The cells for re and le are separated by three blank cells for śe, ṣe, and se. Thus it is improbable that Grinstead accidentally wrote 2lie in the l-row instead of the r-row.
2. The entry for 2lie 'to see' in Nevsky 1960 (II: 199) lists a transcription of Sanskrit śakale (locative singular of śakala 'fragment'?):
The transcription of the first two syllables is reminscent of Tangut period northwestern Chinese 釋迦 *ʃi-kja < Late Old Chinese *ɕɨak-kɨa for Śakya.2ʃɪ-1kɨaa-2lie
3. 2lie 'to see' belongs to Nishida's (1964: 137) liquid-initial homophone group 108, whose member(s?) transcribe Sanskrit le. Nishida (1964: 135-149) only reconstructed Tangut r- for tangraphs transcribing Sanskrit r-.
All of the above do not rule out the possibility that 2lie 'to see' could transcribe Sanskrit re as well as le, but I would expect a Tangut l- : Sanskrit r- correspondence to occur more than once: e.g., there should be cases of Tangut la for Sanskrit ra, etc.
Accoridng to Kwanten (1982: 23-24),
1lo 'young gentleman (< TPWNC 郎 *lo; husband; a surname (< TPNWC 羅 *lo)
transcribed both Sanskrit ra and la (with -a, not -o!) in the Tangut translation of the Suvarṇaprabhaaṣaasuutra.
Li Fanwen (2008: 747) gives an example of 1lo
corresponding to Sanskrit ra in
0ʔa-1lo-1xã 'arhat' < TPWNC 阿羅漢 *ʔa-lo-xã < Middle Chinese *ʔa-la-xanh < Skt arhant-
from Nishida (1966: 266) which does not specify a textual source for the word. That page also has two more examples of that correspondence:
1po-1lo-1dzəu < TPNWC 波羅密 *po-lo-mi < Middle Chinese *pa-la-mɨit < Skt paramitaa
(Nishida reconstructed the last tangraph LFW1338 as mi on p. 266, but reconstructed it as ndzǐu on p. 323. Did Nishida think this tangraph had two readings? On p. 540, he wrote that "a single Hsi-hsia [Tangut] character had not only a Hsi-hsia reading, but a Chinese pronunication as well". Would his mi be the 'Sino-Tangut' pronunciation of LFW1338? If it were not for 'paramita', I would not expect LFW1338 to be read mi, since it means 'to love; to like' and 密 means 'dense; close; secret'.)
1thõ-1lo-1dʒɨi < TPNWC 陀羅尼 *tho-lo-ndʒi < Middle Chinese *da-la-ɳi < Skt dhaaraṇii
(The Tangut nasal vowel -õ is unexpected.)
Note that I wrote "correspondence" rather than transcription. These cases of 1lo : ra are actually Tangut borrowings of Chinese words from Sanskrit rather than direct transcriptions of Sanskrit. They reflect Chinese-internal changes that have nothing to do with Sanskrit or Tangut: e.g.,
*a > *o
*d- > *th-*ɳ- > *ndʒ-
The question I cannot answer is: Was 2lie 'to see' like 1lo: i.e., did it transcribe an l-syllable borrowed from a Chinese transcription of a Sanskrit r-syllable?
*The distribution of long retroflex vowels is uneven. There are no Grade II long retroflex rhymes.
| Vowel type | u | i | a | ə | e | o |
| Grade I | none | R99 -əəiʳ | R88 -aaʳ | none | R102 -ooʳ | |
| Grade II | ||||||
| Grade III/IV | R101 -ɨiiʳ, -iiʳ | R89 -ɨaaʳ, -iaaʳ | R100 -ɨəəʳ, -iəəʳ | R103 -iooʳ (Grade IV only) |
The order of long retroflex rhymes is also strange. i-rhymes normally precede a-rhymes, but they are reversed here with a huge gap between them filled with short retroflex rhymes. Why is R100 between R99 and R101? I have followed Gong's arrangement here, but I would not be surprised if I significantly revise my reconstruction of the retroflex rhymes (R77-R103) in the future: e.g., should R100 and R101 switch places?
Arakawa's (1999) reconstructions of these rhymes are almost completely different:
| Rhyme | Chinese transcriptions | Tibetan transcriptions | Grade (this site) | This site | Grade (Arakawa) | Arakawa |
| 88 | *-a, *-ə | None known | I | -aaʳ | I | -ar' |
| 89 | *-jew | III/IV | -ɨaaʳ, -iaaʳ | II | -yar' | |
| 99 | None known |
I | -əəiʳ | -ywor | ||
| 100 | *-ə, *-i | -i (5), -iH (3), -aH (2) | III/IV | -ɨəəʳ, -iəəʳ | -yIr | |
| 101 | *-jẽ, *-aw, *-ə | -e (19), -i (1) | -ɨiiʳ, -iiʳ | -yer2 | ||
| 102 | *-o | -a (1) | I | -ooʳ | I | -woq2 |
| 103 | *-jo | None known | IV | -iooʳ | II -y- + III long vowel | -ya:n |
I can't find any transcription data for R99. My R99 -əəiʳ is simply a mechanical conversion of Gong's -eer. Gong assumed that R99 is the Grade I counterpart of R101 (but not adjacent R100), whereas Arakawa assumed that R99 is the Grade II -y- counterpart of his R98 -wor (= my -iõʳ and Gong's -jowr).
Arakawa's -yer2 more closely matches the Tibetan transcriptions of R101. I do not know how it differs from his R94 -yer (without final -2 which does not represent a tone).
The single extant Tibetan transcription of R102 (lha) may be missing a superscript o letter.
10.6.11.2:44: ERIC GRINSTEAD ON TANGUTOLOGY IN 1974
I first picked up Eric Grinstead's book Analysis of the Tangut Script around 1994 and have been using it almost every day for the past 4 1/2 years. (The 'TT' [Tangut Telecode] numbers I used for a long time were from his revision and expansion of the numbers in Sofronov 1968.) For the past 16 or so years, I've assumed that Grinstead was English or Danish. But it turns out he's from New Zealand! I knew almost nothing about him until I read this Wikipedia article tonight. He's 88 now and will turn 89 next month. I'm looking at his "News of the Field" of Tangut studies as of 1974:
The desiderata at the moment, apart from more archaeology, are the establishment of a working transcription that can be accommodated to the typewriter and the linotype machine, the drawing up of a computer-driven set of Tangut characters, and a central bibliographic depot that would be sure to have all the little pamphlets and articles specifically on Tangut.
I wonder if Grinstead still keeps up with Tangutology. Others have continued his pioneering efforts to bring Tangut into the computer age. What would he think of the Tangut fonts by Mojikyo and Andrew West that I use? Of Unicode Tangut? Of Sven Osterkamp and David Boxenhorn's Tangut searching software? Of David Boxenhorn and Alan Downes' independent alphabetic transliterations of Tangut characters? Of the Tangut bibliographies by Nathan Hill and Viacheslav Zaytsev? Of Li Fanwen's massive 1997 and 2008 Tangut-Chinese dictionaries and Andrew's online indexes for them? Even I couldn't have dreamed of such things back in the mid-90s when I first got started in Tangutology.
10.6.10.23:20: TURNING IN THE SOLDIER'S THEATER: AN IRREGULAR THAI-KHMER CORRESPONDENCE
Although Tangut is my favorite writing system, I am fascinated by scripts in general and historical spelling in particular. Thai spellings of loanwords preserve many features of non-Thai languages that are completely absent from Thai pronunciation. For example, written Thai final ร <r> [n] corresponds to written Khmer final រ <r>, now phonetically zero: Thai [khameen] 'Khmer' is spelled เขมร <khmeer> with ร <r>, which matches the Khmer spelling ខ្មែរ <khmeer> (though not the current [r]-less Khmer pronunciation [khmae]).
One of the first Thai words I learned was ทหาร <dahaar> [thahaan] 'soldier', the name of the Thai letter ท. Native Thai words don't end in <r>. Nor do Chinese loanwords. Indic loanwords can end in <r>, but there is no Sanskrit or Pali word dahaara 'soldier'. (Indic final -a is usually lost in Indo-Thai borrowings.) So by process of elimination, I guessed that it must be Khmer. But to my surprise, the corresponding Khmer word was ទាហាន <daahaan> [tiəhiən] with ន <n> (and a long first vowel <aa> corresponding to short <a> in Thai!).
Conversely, one of the first Khmer words I learned was ល្ខោន <lkhoon> [lkhaon] 'drama' (not very useful, I know). I was surprised to learn that it corresponded to Thai ละคร <laḥgar> [lakhon] with an unexpected ร <r>, a short vowel <a> [o], and even ค <g> instead of น <n> and ข <kh>. (Thai ะ <ḥ> indicates a short preceding vowel.) There is also a Thai word โขน <khoon> [khoon] for another kind of Thai drama. <khoon> has most of the expected correspondences but is missing ละ <laḥ>. <khoon> could be borrowed from a old colloquial Khmer form *khoon without *l-, but why would the longer form be less accurate?
Why does written Thai <r> correspond to both Khmer <r> and <n>?
| Thai | Khmer | ||||
| Letter | Transliteration | Transcription | Letter | Transliteration | Transcription |
| ร | <r> | [n] | រ | <r> | zero |
| ន | <n> | [n] | |||
Is the Thai <r> for Khmer <n> due to hypercorrection: e.g., Thai thinking that foreign words with final [n] are often spelled with <r>, so [thahaan] and [lakhon] should be spelled with <r>? That's what I assumed until I looked at Vickery (1992) which mentions that Old Khmer *veer (vera in Vickery's transliteration) 'turn' corresponds to modern Khmer វេន [veen] with [n]. Did some OK words with *-r shift to -n in modern Khmer? I wish I knew what the Old Khmer words for 'soldier' and 'drama' were.
There is yet another possible explanation for [veen]. Headley's (1977) dictionary derives it from Thai เวร <weer> [ween] with <r>. Moreover, Headley's (1997) dictionary lists Khmer វេរ <veer> [vee] 'turn' with <r>. And to complicate matters, there is also a Thai form เวียน <wian> [wian] 'to go in a circle'. What's going on here? My guess is:
- Old Khmer *veer was borrowed into Thai as เวร <weer> [ween] with regular correspondences.
- A nonstandard, unwritten early Khmer *viar was borrowed into Thai as เวียน <wian> [wian] without regard for Khmer spelling.
- Thai [ween] was borrowed back into Khmer as វេន <veen>, coexisting alongside inherited Khmer វេរ <veer>.
One last twist: Thai เฉวียน <chwian> [chawian], a synonym of เวียน <wian> [wian], looks like it should be from a Khmer ឆ្វៀន *chvian with a prefix ch-, but I can't find any such form in Headley's dictionaries or Jenner and Pou's (1980-81) Lexicon of Khmer Morphology.
Has anyone written an article or book on Khmer loans in Thai that is equivalent in scale to Gedney's 1947 dissertation on Indo-Thai? Such a work would ideally answer all of the above questions.
Zhu Qingzhi (1995) identified five parallel expressions in Old Chinese and Sanskrit:
| Gloss | Old Chinese | Literal gloss | Sanskrit | Literal gloss |
| fourth finger | 無名指 | nameless finger | anaaman | nameless |
| Venus | 太白 | great white | śukra | white |
| moon | 兔 | rabbit | śaśin | hare-possessor |
| limited (in knowledge) | 牛涔 | cow-puddle (rainwater in bovine footprint) | goṣpada | cow-foot |
| bezoar | 牛黄 | cow-yellow | gorocanaa | cow-yellow |
He concluded that "all of them are the result of early exchange between China and India."
Historical linguists are deeply concerned with distinguishing between coincidences and similarities due to contact or genetic relationship. There is no genetic relationship between Chinese and Sanskrit (unless it is extremely distant and beyond demonstration), so that leaves coincidence and contact as the only explanations for these similarities.
I think all but the fourth are probably coincidences.
1. 'Nameless finger' is in English and Russian (безымянный палец). As far as I know, the term cannot be reconstructed in Proto-Indo-European. I think English, Russian, Sanskrit, and Chinese could have developed the term independently. László Magyar listed other languages with 'nameless finger': e.g., Hungarian, Finnish, and Turkish. Is the term used outside Eurasia?
Another term for that finger with a distant parallel is Latin digitus medicinalis which matches Japanese 藥指 kusuriyubi 'medicine-finger'.
2. Venus is "one of the brightest objects in the sky", so two or more cultures could independently call it 'white'. Moreover, Skt śukra is primarily 'bright' and is from the root śuc 'gleam'.
The Japanese and Korean word for 'Friday' is 金曜日 'metal shine day' - metal being the element associated with Venus in the Sinosphere. Guess what the Thai word for 'Friday' is ... วันศุกร์ wan suk 'day Venus' = 'Venus day'.
3. If the Aztecs could associate the moon with rabbits, could the Chinese also have done so without contact with India?
5. Googling for photos of bezoar, I see that it is often yellow, so it might be surprising if Chinese and Sanskrit didn't have 'yellow' in their terms for it.
4. Only 'cow puddle' remains. Does that metaphor exist outside the Sinosphere and Indosphere?
10.6.9.23:45: WHAT WAS THE FIRST SANSKRIT WORD BORROWED INTO CHINESE?
I was expecting a Buddhist term, but Hoong Teik Toh (2010) thinks it's keśii 'one having a mane', transcribed in Old Chinese as 雞斯 *kese in Huainanzi (2nd c. BC). Skt ś [ɕ] corresponds to OC *s since there was no palatal *ɕ in OC. It's also possible that the Indic original was an early Middle Indo-Aryan form like kesii with -s- < Skt ś and -e or even kese 'hair' with the eastern masculine nominative singular ending -e corresponding to Sanskrit -as. If the original ended in -ii, a closer transcription could have been 雞私 *kesi.
What was the first Sanskrit word borrowed into Tangut? I don't know, but I bet it was borrowed through Chinese. Although Nishida (1964) and Grinstead (1972) apparently assume that Tangut Sanskrit transcriptions directly represent Sanskrit, I suspect that they are actually based on Chinese pronunciations of Sanskrit. But it's also possible that the Tangut learned Sanskrit words through Tibetan. I'd like to look into 'Indo-Tangut' later.
10.6.8.23:59: THE GOLDEN GUIDE: LINES 23-24: TANGRAPHS 111-120
First, a couple of pairs of antonyms:
| Tangraph number | 111 | 112 | 113 | 114 | 115 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3368 | 0187 | 0590 | 5621 | 1868 |
| My reconstructed pronunciation | 1thwị | 2naʳ | 2ziọ | 1lhəu | 1tiẹ |
| Tangraph gloss | young (noun) | old; aged (noun) | longevity; life; generation; world | to increase; to raise; to add | to reduce; to remove |
| Word | change; oscillation; growth and fall; profit and loss | ||||
| Translation | The changes of longevity of the young and the old, | ||||
This line consists of a series of nouns, so I translated it as a chain of possession.
111 is from 0611 1miəʳ 'strong; robust' (a quality of youth?) + 0960 1miẹ 'woman; female' (why?):
+
The right side of 111 is unique. 0960 'woman' is similar but has the filler ヒ added to the bottom right. This radical is supposedly from 3168 1mi 'woman; female' plus the right side of ... 111!
0960 'woman' can be abbreviated in several other ways:
=
+
1. Top and bottom left: second half of 0225 1851 1ɣɨə-1zwị 'to marry' and first half of 2mə-2diõ 'sister'
and first half of 0857 0549 2mə-2diõ 'sister'
These are the only two instances of this abbreviation ̣(alphacode tin).
2. Top and center: 3361 1kɛ̣ 'sister'
3. Bottom only: 4706 2dʒɨuu (transcription of Chn 女 'woman' which had an initial *ndʒ- in the northwestern dialect of the time)
112 'old' has left and right radicals that appear in tangraphs for 'old'.
The left radical (alphacode pus) appears in only four other tangraphs which all represent words involving aging:
The right radical (alphacode fur) resembles Chinese 老 'old'.0188 1ʃwɨə 'wrinkle; to decline; old'
0647 variant of 0188 with the unique right radical hao, a variant of fur (see below)
0769 1lwie 'old; aged; to die'
16071khwiaʳ 'old ox'
0923 1və̣ 'old; aged'
2140 1vɨə̣ 'old; aged'
4217 1vɨuu 'old; rotten; withered'
(All three words are probably cognate.)
But not all fur tangraphs mean 'old': e.g.,
0252 1sio 'long and thin' (with 'skin' on the left)
5158 1siọ 'agriculture' (with 'hand' on the left)
0254 1khəu 'owlet' (with 'bird' on the left): i.e., a young owl, not an old one! (Or were owls - even young ones - symbolic of aging?)
113 has a left radical
alphacode: too
that Nishida (1966: 243) identified as 'longevity' plus the radical 'person' on the right. This radical could be based on Chinese 寿 'longevity'.
Is 'person' a 'filler' to prevent the left radical from standing alone?
113 2ziọ vaguely sounds like 寿 Tangut period *ʃu < Middle Chinese *(d)ʑuʔ/h 'longevity' but if it were a Chinese borrowing, I would expect it to have an initial ʃ- or ʒ- rather than z-. The z- may be from a lenited sibilant:
*sɯ-(T)SoH > *sɯ-(d)zoH > *sɯ-zioH > *szioH > *zzioH > *zzioḤ > *ziọH > 2ziọ
(The relatively chronology of changes may be wrong.)
114 looks like 'words and deed' since it consists of 'hand', a vertical line, and 'language', but means 'add':
+
5621 1lhəu 'to add' =
1763 0lhəu 'to add' (an exact or near homophone depending on its unknown tone) +
3189 2lɨo 'to spread; to disseminate' ('language' on the right implying word of mouth)
115 is from 1770 1lhwi 'to take' plus 1880 1tshiẽ 'to pare' (with 'small' on the right)
+
which of course has a circular analysis with 1880 1ʔwọ 'thick; bulky' as the source of its left side:
=
+
The left radical hie of 1805 and 1880 should not be confused with the 'horse' radical on the left of
1115 1gie 'horse'
from line 8.
Alas, no parallel antonyms in line 24, which begins with a couple of grammatical words. How did the Tangut write words with abstract meanings?
| Tangraph number | 116 | 117 | 118 | 119 | 120 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5354 | 5880 | 1290 | 1463 | 2833 |
| My reconstructed pronunciation | 2thiə | 2ŋwəu | 2tsew | 2dʊ | 2diẽ |
| Tangraph gloss | this | instrumental case suffix | limit; class; ordinal number suffix | to measure; to set bounds to | calm; quiet; certainly; without fail; (to settle?) |
| Word | to measure; to weigh; to limit; (limit [noun]?) | ||||
| Translation | Thus limits were settled. | ||||
I am not sure how to translate this line.
116 2thiə 'this' has a very dubious analysis:
+
5354 2thiə 'this' =
5355 2thiə 'scorpion' (phonetic) +
0046 2lie 'to see' (why?; graph from Chn 見 plus filler bottom right radical)
Was 'scorpion' really devised before 'this'?
This analysis also makes little sense as a mnemonic device, since most tangraphic learners would know 'this' before 'scorpion'.
And yes, 'scorpion' was analyzed as being from 'this':
5355 2thiə 'scorpion' =
5354 2thiə 'this' (phonetic) +
1887 1kie 'insect' (semantic)
1887 is a rare radical that can stand alone.
The analysis of 5355 must be correct, but what is the true analysis of 5354?
Changing the vowel of 2thiə 'this' results in
2thiu 'here'
which looks like 'person' + 'high'.
117 2ŋwəu 'instrumental case suffix'
has a left radical fax which resembles
gux 'small' (cf. Chinese 小 'small', 少 'few') in the 117 lookalike 5881 1la 'small'
and in 115 'to reduce' (see above)
but has a single フ stroke across the vertical instead of two strokes (ソ). The distinction between fax and gux is absent in the Mojikyo font, so I had to modify 117 myself.
Unlike gux, fax cannot stand by itself, so 'person' may be a filler.
116 and 117 together could be literally translated as 'this-by' or 'by (means of) this'.
118-119 can form a compound verb 'to limit' from 119 'to measure' and its object 118 'limit'. I would expect that verb to be at the end of the sentence, but it's followed by 120 which is normally an adjective (or an adverb according to Kychanov 2006: 370). Could 118-119 be a compound noun 'limit' that is the object of 120 as a verb, borrowed from Middle Chinese 定 *deŋ 'settled' which can also be a verb 'to settle'?
In any case, there is no passive in the original. I use the passive only because there is no specified subject in the original. I don't know who's limiting, but I suppose 'limit' refers to the lifespans in the previous line.
119 2dʊ (Grade II) could be borrowed from Middle Chinese 度 *doh 'measure' (Grade I), though the MC word is a noun, not a verb. The mismatch in grades (MC Grade I, Tangut Grade II) could reflect the fact that there is no Tangut Grade I dəu.
120 looks like a distortion of Chn 定 'id.' with the top half converted into the Tangut 'grass' radical and the bottom half split into the Tangut 'not' radical and the radical bil of unknown function.
10.6.7.19:45: THE GOLDEN GUIDE: LINES 21-22: TANGRAPHS 101-110
The next hundred tangraphs begin with yet another word for 'night'. Four other words are in lines 3, 13, and 14.
What is the difference between all these apparent synonyms? For about a century, Tangutologists have been working with convenient tag translations which may obscure semantic differences in Tangut that may not have parallels in Chinese, Russian, etc.
| Tangraph number | 101 | 102 | 103 | 104 | 105 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 0102 | 1421 | 3305 | 0811 | 2226 |
| My reconstructed pronunciation | 2giə | 1zị | 1kiew | 2jaaʳ | 2vəi |
| Tangraph gloss | night | daylight; daytime | year; age | date; day | to be; to do |
| Word | |||||
| Translation | Nights and days comprise years and dates, | ||||
101 might be a distortion of Chn 夜 'night' whose shape always reminded me of the unrelated tangraph
2ʔwɨəʳ 'literature' (elaborated version of Chn 文 'id.'?)
102 has a unique bottom half. It shares a top and a bottom left with
2vɨe 'a surname'
which has no semantic or phonetic similarity. The lost analysis of 102, if any, probably contains three tangraphs as sources for its top, bottom left, and bottom right radicals.
103 1kiew 'year' is analyzed as being from 1tʃɨẹ 'year; age' + 1vɨi 'year; age':
+
Of course, both its supposed source characters are in turn derived from it!
'year' = 'year' + 2tʃɨẹ 'a kind of bird' (phonetic)
=
+
'year' = 'year' + 'flow' + 'month'
104 has a unique left side
which looks like it should be a combination of two radicals, but its bottom half (ㄇ with a line through it) does not occur elsewhere without something else on top.
The right radical ヒ seems like a 'filler' whose sole function is to prevent the left side from standing alone. I still do not understand why some radicals can be independent tangraphs while others need fillers.
Could 103-104 'year-day' be 'date' like Japanese 年月日 nengappi 'date', literally 'year month day'?
105 consists of 85 1vəə 'to own; to have; to belong to' from line 17 and 24 1ʃɨẽ 'to accomplish; to achieve; to become' from line 5:
+
105 2vəi 'to be; to do' is probably cognate to Old Chinese 爲 *waj 'to be; to do'.
| Tangraph number | 106 | 107 | 108 | 109 | 110 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 4082 | 2105 | 3096 | 3457 | 0756 |
| My reconstructed pronunciation | 1reʳ | 1tʃɨõ | 1kwi | 1siw | 2dʒɨu |
| Tangraph gloss | twelfth month | first month | used; worn; old | new; fresh | to meet |
| Word | |||||
| Translation | The last and first months, the old and the new meet. | ||||
106 'twelfth month' is a combination of 'cold' and 'season' from line 6:
107 'first month' is a combination of 'year' + 1tʃɨõ 'a surname' (phonetic) + 'to raise; to happen':
+
+
108 and 109 are normally adjectives, but here I treat them as nouns parallelling 106 and 107.
108 'old' has a dubious derivation:
+
'old' = 'old; outdated' + 1tị 'to place; to put; to set up' (why?)
Guess what's in the derivation of the second tangraph:
+
'old; outdated' = 'tattered' (with 'insect' on the bottom right) + 'used; worn; old'
109 1siw 'new' is from 'not' + 'old' + 1swie 'clear; obvious'
It's not ... clear or obvious why part of 'clear; obvious' is in new. Perhaps the analysis of 'clear; obvious' can give us some clues:
=
+
1swie 'clear; obvious' = 1kõ 'night' + 1swew 'to shine; to illuminate'
I wonder if 1swew 'shine' is both phonetic and semantic in 1siw 'new': cf. the English phrase shiny and new.
?
1siw < *sik 'new' is cognate to
Taoping Qiang tshi < *khsi?
Mawo Qiang khsə
Ronghong Qiang xsə
Japhug rGyalrong kɯ-ɕɤɣ
Somang rGyalrong kə-ɕə́k
both < Proto-rGyalrong *ɕɐk
Written Burmese sac < *sik
Old Chinese 新 *sin < *siŋ (with a final nasal instead of a stop)
110 probably had a derivation other than the one in the Tangraphic Sea:
+
2dʒɨu 'to meet' = 2bəiʳ 'to meet' + 1diụ 'to meet; to encounter' (cognate to 2dʒɨu?)
However, the Tangraphic Sea derivations for the second and third 'to meet' may be accurate:
+
2bəiʳ 'to meet' = 0dʒɨi 'to walk; to go' + 2dʒɨu 'to meet'
=
+
1diụ 'to meet; to encounter' = 1tʃhɨe 'to go; to walk' + 2dʒɨu 'to meet'
1tʃhɨe 'to go; to walk' may be from *K-dʒi-e, an affixed variant of 0dʒɨi < *dʒi 'to walk; to go'.
10.6.6.23:12: THE TOP HUNDRED CHARACTERS IN TANGUT, JAPANESE, AND CHINESE
I just finished translating and annotating the first hundred characters in the first ten lines of the Golden Guide, a book for Tangut native speakers to learn the thousand most important characters in their script:
For comparison, here are the first hundred Chinese characters that are taught in the Japanese school system. The first eighty are taught in first grade and the following twenty are taught in second grade. Needless to say, they are much simpler than the first hundred Tangut characters. You can see their readings and meanings here.
First grade (80 characters):
一二三四五 六七八九十
百千上下左 右中大小月
日年早木林 山川土空田
天生花草虫 犬人名女男
子目耳口手 足見音力気
円入出立休 先夕本文字
学校村町森 正水火玉王
石竹糸貝車 金雨赤青白
Second grade (first 20 out of 160 characters):
数多少万半 形太細広長
点丸交光角 計直線矢弱
I haven't seen any lists of the first hundred characters taught in the PRC, Taiwan, Hong Kong, or South Korea. Here's a list of the 1800 characters taught in South Korean secondary schools (900 in middle school and 900 in high school) arranged by reading. Below are the one hundred most frequent traditional Chinese characters in Usenet in 1993-94 from Chih-Hao Tsai's site:
的是不我一 有大在人了
中到資要以 可這個你會
好為上來學 就交也用能
如時文說沒 他看那問生
提下過請們 天所多麼小
之想得工出 還電對都機
自而子後訊 家站心只去
知國很台成 信同何章道
發地法無然 但當於嗎本
年現前最真 新和因果意
And here's a list of the top hundred most common simplified characters from Jun Da's site:
的一是不了 在人有我他
这个们中来 上大为和国
地到以说时 要就出会可
也你对生能 而子那得于
着下自之年 过发后作里
用道行所然 家种事成方
多经么去法 学如都同现
当没动面起 看定天分还
进好小部其 些主样理心
她本前开但 因只从想实
The Tangut top one hundred includes two pairs of inseparable characters representing disyllabic words
2lɛ̣-1ɣʊ 'night'
1na-2raʳ 'tomorrow'
whereas all of the Chinese characters represent monosyllabic bound or free morphemes.
Andrew West has written a post comparing the compexity of Tangut, Chinese, Khitan Large, and Jurchen characters:
On the other hand, it was a surprise (to me at least) to see how closely the contour of Tangut matches that of traditional Chinese, as I had always assumed that Tangut characters must, on average, be much more complex than Chinese characters. But although Tangut does not have any characters with very few strokes (less than 4 strokes) or very many strokes (more than 24 strokes), which distinguishes it from Chinese, if you ignore the lower and upper ends of the graph the distribution of stroke counts for Tangut is very close to that of traditional Chinese. Why then does Tangut text look so much more complex and more crowded than Chinese? That could be answered with another graph which took into account each character's frequency of occurence. A large proportion of high frequency Chinese characters have very few strokes (e.g. 一二三人女山火水大小中), and conversely Chinese characters with very many strokes tend to occur less frequently, with the result that normal Chinese text always has a large proportion of characters with few strokes. In contrast to the situation with Chinese, there does not appear to be any relationship between frequency and stroke count for Tangut characters, so that normal Tangut text is uniformly composed of characters with 12±6 strokes, with the result that it appears denser and more crowded than Chinese.
Let's look at the number of strokes per character in the top ten characters for each list:
| Character | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Mean | Mode |
| Tangut | 13 | 10 | 9 | 9 | 11 | 9 | 12 | 8 | 9 | 14 | 10.4 | 9 |
| Japanese | 1 | 2 | 3 | 5 | 4 | 4 | 2 | 2 | 2 | 2 | 2.7 | 2 |
| Traditional Chinese | 8 | 9 | 4 | 7 | 1 | 6 | 3 | 6 | 2 | 2 | 4.8 | 2 or 6 |
| Simplified Chinese | 8 | 1 | 9 | 4 | 2 | 6 | 2 | 6 | 7 | 5 | 5.0 |
This is comparing apples and oranges since the top ten Tangut and Japanese characters are not the most frequent in those languages and the top ten Japanese characters represent numerals and have fewer strokes than most Chinese characters in Japanese. Nonetheless, all forty characters are among the first learned by students and the statistics clearly show that Tangut characters are more complex even at a beginning level.
Another way to measure complexity is to count the number of radicals/elements per character:
| Character | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Mean | Mode |
| Tangut | 2 | 2 | 4 | 4 | 3 | 2 | 3 | 2 | 1 | 4 | 2.7 | 2 |
| Japanese | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Traditional Chinese | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 2 | 1 | 2 | 1.4 | 1 |
| Simplified Chinese | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 2 | 1 | 2 | 1.4 | 1 |
(The numbers for traditional and simplified Chinese are exactly the same even though the top ten characters in the two lists don't match!)
The average Tangut character has at least two radicals. One-radical Tangut characters are rare whereas they are common in Japanese and Chinese. (One should not conclude from the above table that Chinese characters in Japanese usually have only one radical because the first ten numeral characters all consist only of a single radical.) The vast majority of Chinese characters also have two or three radicals and some even have more strokes than Tangut, but as Andrew noted, it is the high-frequency simple characters that make Chinese writing look simpler than Tangut. In turn, the use of kana in Japanese makes Japanese writing look even simpler than Chinese: the kana の for the Japanese genitive has only one stroke, whereas its Chinese equivalent 的, the most common character of all, has eight. I am surprised that I know of no proposals to officially simplify 的. The variants of 的 at the ROC Dictionary of Chinese Character Variants are almost as complex or even more complex. (In Taiwan, I saw の as a substitute for 的. Is that a remnant of the colonial period, or a more recent practice?) One might expect the literary Chinese equivalent of 的 to be more complex, but in fact it's simpler: 之.
There are other aspects of Tangut complexity that are harder to express in terms of numerals: e.g., the multiple and sometimes even unknown functions of Tangut radicals. It is the challenge of comprehending this complexity that attracts me to Tangut. I wonder how many Tangutologists didn't become interested in Tangut because of the script.
6.7:0:11: In the comments for Andrew's post, David Boxenhorn and Andrew discuss how Chinese characters have more basic elements than Tangut. So why is Tangut more difficult? Although Tangut employs fewer elements, those elements are very similar in shape: e.g., the ヒ-series of radicals
which appear in one out of six tangraphs. There are about a dozen more in that series. It is relatively easy to remember that a given Tangut character has a ヒ-like shape on the bottom right, but it is harder to remember exactly which& nbsp;ヒ-like radical is in that position, especially when the functions of these radicals remain largely unknown.
Chinese radicals have a greater diversity of forms and are hence more distinctive. One need not worry about distinguishing 心 'heart' from lookalike radicals with one, two, or four instead of three dots, etc.
One could replace the twenty-six letters of the Roman alphabet with, say, five shapes plus diacritics, but five different vowel symbols
A E I O U
are more distinctive than five variants of a single shape:
Ë E É È Ê
A comparison with the Roman alphabet is appropriate since Alan Downes grouped Tangut radicals into 21 groups that he named after Roman consonant letters in his 2008 thesis: e.g., the ヒ-series was mostly part of his c-series since ヒ resembles c:
ce, co, cace, damace, mamace, damamace, lece, lecoo, cii, macii, qe (resembles Q; no c!)
10.6.6.16:36: THE GOLDEN GUIDE: LINES 19-20: TANGRAPHS 91-100
I'm finally one-tenth of the way through the Golden Guide.
| Tangraph number | 91 | 92 | 93 | 94 | 95 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5841 | 5834 | 3589 | 1084 | 4027 |
| My reconstructed pronunciation | 2khwəụ | 2le | 2dziẽ | 2ɣạ | 1niəə |
| Tangraph gloss | to cut; to slice | to change; to vary | time | ten | two |
| Word | twelve | ||||
| Translation | The times of changes are twelve, | ||||
91-92 are similar in shape and look like they should represent a disyllabic word, but I can't find any such word in Kychanov (2006: 729) or Li Fanwen (2008: 920). 91 and 92 are both independent verbs. I would expect verbs to appear at the end of the line, so I wonder if 91-92 represent a noun. Nie and Shi translate it as 变化 'change'. I treat it as a modifier of 93 'time'.
Tangut nouns are preceded by nominal modifiers
|
|
| Noun1 | Noun2 |
| 2khwəu-2lẹ | 2dziẽ |
| change | time |
| time(s) of change | |
but are followed by adjectival modifiers:
 |
 |
| Noun | Adjective |
| 1tseʳw | 2bi |
| joint | low |
| low degree of relation (example from Kychanov 2006: 565) | |
1tseʳw 'joint' can also refer to segments of time. Its tangraph is the right half of 93 2dziẽ 'time':
+
1tseʳw < *r(ʌ)-tsek or *rʌ-tsik is cognate to Old Chinese 節 *tsik which has the same range of meaning.'time' = 'day' + 'segment of time'
Tangut numbers precede nouns if there is no classifier
 |
 |
| Numeral | Noun |
| 1sọ | 2kɛ̣ |
| three | realm (see line 1) |
| three realms (Pearl in the Palm 356.9-10) | |
and folllow nouns and precede classifiers:
 |
 |
 |
| Noun | Numeral | Classifier |
| 1bəị | 0ʔa | 2bɛ̣ |
| lance; spear | one | classifier for threads and trees (Jacques 2007: 165) |
| one spear (西夏法典 II; Li Fanwen 2008: 755, 927) | ||
though I found this counterexample from 西夏法典 II (Li Fanwen 2008: 927):
|
|
|
 |
| Numeral | Classifier | Noun | |
| 1sọ | 2ɣạ | 2bɛ̣ | 1lɨị |
| three x ten = thirty | classifier for threads and trees (Jacques 2007: 165) | arrow | |
| thirty arrows | |||
The construction (noun + numeral) without any classifier doesn't fit any of these patterns. If line 19 is supposed to be a sentence, could it be equational
times of changes = twelve
even though it lacks a copula at the end and/or the linker LFW3583 1tia (see line) between the nouns?
Tangut equational constructions (Nishida 1966: 287, 585)(A) B 2ŋwəu
A 1tia B
A 1tia B 2ŋwəu
A common equational construction in Tangraphic Sea definitions is
(A 1tia) B 1lɨə
94 2ɣạ has a lenited initial and a tense vowel implying an earlier presyllable: *Sʌ-qa (cf. proto-rGyalrong sqa- 'ten'). I would expect a Grade II rhyme -æ̣ after an earlier uvular, but there is no such rhyme in Tangut. Perhaps -æ̣ merged into -ạ:
| Pre-Tangut | Postuvular vowel lowering | Lenition | Fusion and fortition | Vowel tensing | Initial simplification | Uvular-velar merger | Grade I/II merger |
| *S(ʌ)-qa | *S(ʌ)-qæ | *S(ʌ)-ʁæ | *ʁʁæ | *ʁʁæ̣ | *ʁæ̣ | *ɣæ̣ | ɣạ |
| *S(ʌ)-ka | *S(ʌ)-ka | *S(ʌ)-ɣa | *ɣɣa | *ɣɣạ | *ɣạ | *ɣạ |
The distribution of Grades I and II in tense rhymes (< *S(ʌ)-) is strange.
| Pre-Tangut | *-u | *-i | *-a | *-ə | *-e | *-o |
| Grade I | -əụ | -əị | -ạ | -ə̣ | none | -ọ |
| Grade II | none | -ɪ̣ | none | -ɛ̣ | -ɔ̣ | |
Was there a full paradigm at one point
| Pre-Tangut | *-u | *-i | *-a | *-ə | *-e | *-o |
| Grade I | *-əụ | *-əị | *-ạ | *-ə̣ | *-ẹ | *-ọ |
| Grade II | *-ʊ̣ | *-ɪ̣ | *-æ̣ | *-ʌ̣ | *-ɛ̣ | *-ɔ̣ |
or are the gaps accidental? I suspect the former. The complex rhyme system in Tangraphic Sea could be descended from an even more complex rhyme system. If there were a *S(ʌ)-qe and a *S(ʌ)-Cre that led to Grade II Cɛ̣, there probably once was a *S(ʌ)-Ce without uvulars or *-r- that became Grade I *Cẹ. I am surprised at the direction of merger, as I'd expect Grade II to merge into Grade I, not the other way around.
95 1niəə < *nəə 'two' has a schwa vowel that doesn't match the high front vowel of Written Tibetan gnyis or Old Chinese 二 *nits. The schwa superficially resembles the neutral vowel of Japhug rGyalrong ʁnɯs 'two', but that ɯ is from proto-rGyalrong *i whose frontness is preserved in Somang kə-nês and Zbu ʁnîs (Jacques 2004: 255). Is the schwa of pre-Tangut due to ablaut?
| Tangraph number | 96 | 97 | 98 | 99 | 100 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 4501 | 3331 | 3101 | 5171 | 5659 |
| My reconstructed pronunciation | 1ʃɨe | 1bəu | 2ji | 1sə | 1veʳ |
| Tangraph gloss | moon | to sink; to submerge | again; to repeat; to duplicate | full | flourishing; luxuriant |
| Word | |||||
| Translation | The moon wanes, then waxes again. | ||||
96 looks like 'motion' atop 'moon' (see line 2). Grinstead thought 96 was a verb 'to wax' or 'to wane' but it can't be a verb in initial position. Li Fanwen (2008: 715) defined 96 as 'moon' and gave no examples of 96 in texts apart from its appearance in Homophones. 96 also appears in Precious Rhymes of the Tangraphic Sea which only tells us that it belongs to level tone rhyme 35.
97 is from 'night' plus 'shadow' (from line 12):
+
98 2ji sounds like Tangut period northwestern Chinese 亦 *ji < Old Chinese *jak 'also'. Could it be a loanword?
98 was analyzed in Precious Rhymes of the Tangraphic Sea as
+
left and bottom right of1khiaʳ 'to look into; to investigate; to interrogate; to repeat; to duplicate; repetition' (semantic)+
left of lɨị 'to judge; to examine; to investigate; to judge; court of justice' (why?)
What is 'water' doing in the first two and why does 'person' lengthen its right leg? There is no tangraph with a regular 'person' plus the remaining two-thirds of 'again'.
I treat 99-100 as a compound intransitive verb.
99 is from 0ʔa 'full; content' (semantic) + 1biə 'to overflow' (semantic):
+
100 is from 1rieʳ 'skillful; ingenious' (semantic?) + 1gwiəʳ 'to rise; to grow' (semantic):
+